
卷積層,池化層等,前向/反向傳播原理講解
今天閑來無事,考慮到以前都沒有好好研究過卷積層、池化層等等的前向/反向傳播的原理,所以今天就研究了一下,參考了一篇微信好文,講解如下:
參考鏈接:https://www.zybuluo.com/hanbingtao/note/485480
https://github.com/hanbt/learn_dl/blob/master/cnn.py
一、卷積層
(1)首先是卷積神經網絡中的卷積操作:
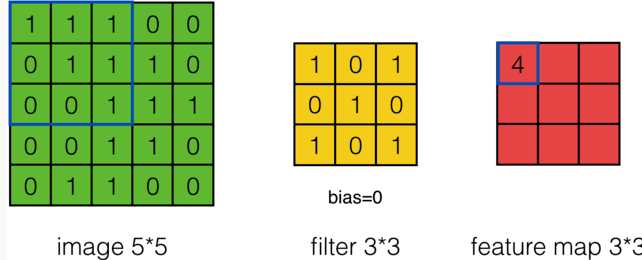
計算公式為:
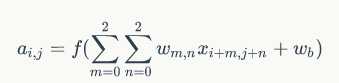
註意上式的使用場景:stride = 1 , channel = 1
我們可以將其擴展到 stride = s , channel = d時的情況,這個時候公式如下:

(2)然後,我們再來看一下數學中的卷積操作,下面引入數學中的二維卷積公式:
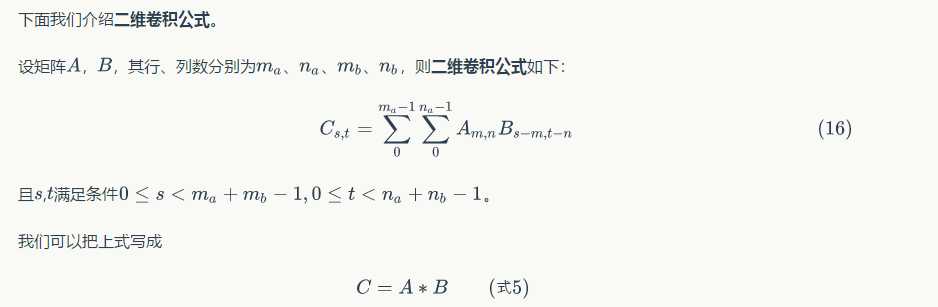
對於如下的圖,數學中的卷積操作如下:
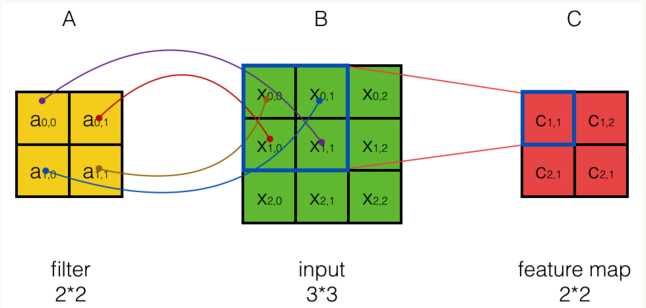
從上圖可以看到,A左上角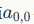 的值與B對應區塊中右下角
的值與B對應區塊中右下角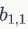 的值相乘,而不是與左上角
的值相乘,而不是與左上角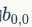 的相乘。因此,數學中的卷積和卷積神經網絡中的『卷積』還是有區別的,為了避免混淆,我們把卷積神經網絡中的『卷積』操作叫做互相關(cross-correlation)操作。
的相乘。因此,數學中的卷積和卷積神經網絡中的『卷積』還是有區別的,為了避免混淆,我們把卷積神經網絡中的『卷積』操作叫做互相關(cross-correlation)操作。
另外:數學卷積和互相關操作是可以相互轉化的,比如對於C = A * B,這裏A和B的卷積就相當於將B翻轉180度然後與A做互相關操作得到。
(3)再來說說卷積層的前向、反向傳播:
首先是前向傳播:很簡單,直接使用互相關的公式計算即可;
然後是反向傳播:可以參考我之前作的關於全連接層的反向傳播過程,原理公式近似;
具體說一下反向傳播過程:
首先引入一道題:

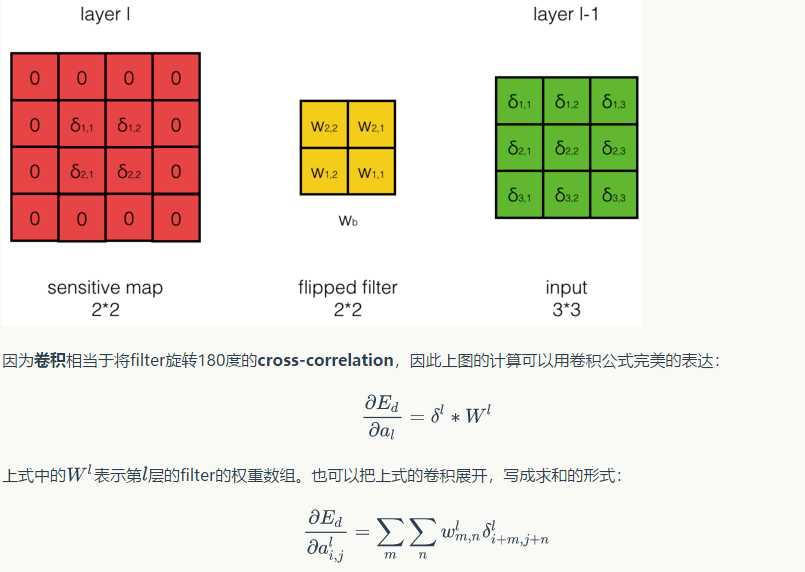
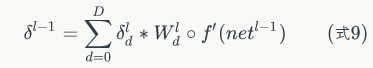
可以發現,卷積層的反向傳播過程和全連接層的反向傳播過程真的是神似啊,只不過公式需要對應的修改一下;
這裏還要註意一點的是,步長stride = s和stride = 1時反向傳播的區別:
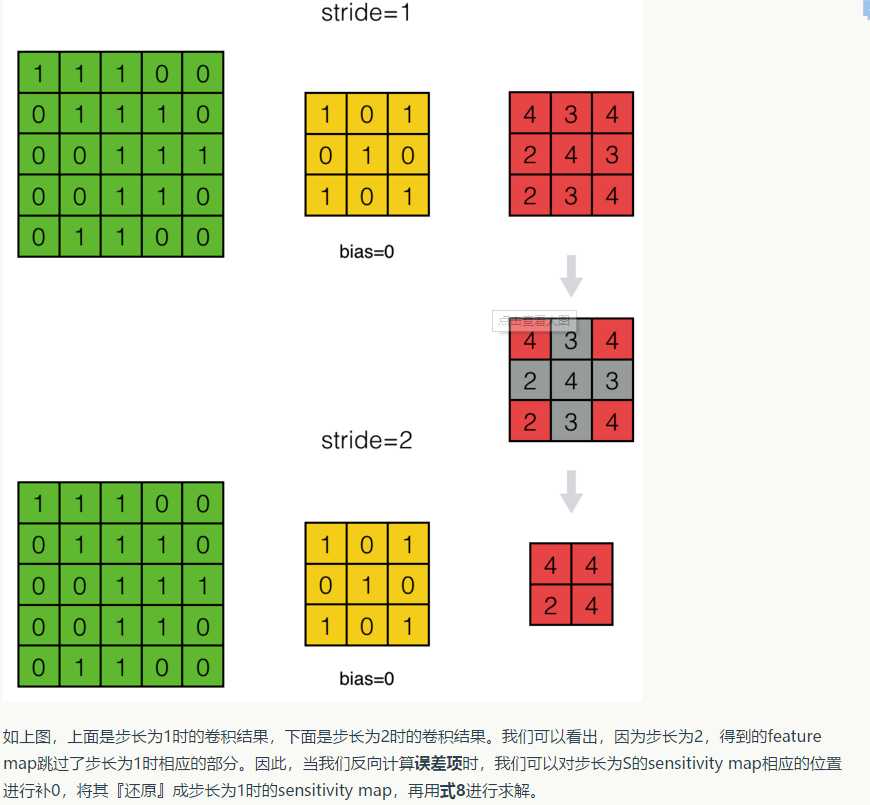
這裏面就涉及到了“擴展”和"zero padding"操作,在後面代碼中有所體現;
緊接著我們可以得到權重梯度和偏置項梯度如下:
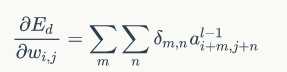
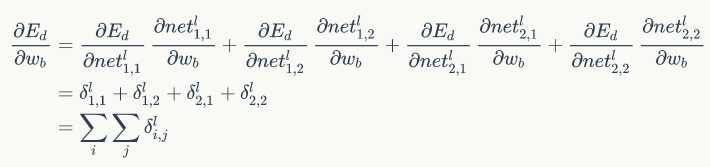
好的,放出代碼了,如下:
import numpy as np from activators importReluActivator , IdentityActivator #獲取卷積區域 def get_patch(input_array , i , j , filter_width , filter_height , stride): ‘‘‘ 從輸入數組中獲取本次卷積的區域,自動適配輸入為2D和3D的情況 ‘‘‘ start_i = i * stride start_j = j * stride if input_array.dim == 2: return input_array[start_i : start_i + filter_height , start_j : start_j + filter_width] elif input_array.dim == 3: return input_array[: , start_i : start_i + filter_height , start_j : start_j + filter_width] #獲取一個2D區域的最大值的索引 def get_max_index(array): max_i = 0 max_j = 0 max_value = array[0 , 0] for i in range(array.shape[0]): for j in range(array.shape[1]): if(array[i , j] > max_value): max_value = array[i , j] max_i , max_j = i , j return max_i , max_j #計算卷積,是互相關操作 def conv(input_array , kernel_array , output_array , stride , bias): ‘‘‘ 計算卷積,自動適配輸入為2D和3D的情況 ‘‘‘ channel_number = input_array.ndim output_width = output_array.shape[1] output_height = output_array.shape[0] kernel_width = kernel_array.shape[1] kernel_height = kernel_array.shape[0] for i in range(output_height): for j in range(output_width): output_array[i][j] = ( get_patch(input_array , i , j , kernel_width , kernel_height , stride) * kernel_array).sum() + bias #對數組增加zero padding def padding(input_array , zp): ‘‘‘ 對數組增加zero padding,自動適配2D的情況 ‘‘‘ if zp == 0: retrun input_array else: if(input_array.ndim == 3): input_width = input_array.shape[2] input_height = input_array.shape[1] input_depth = input_array.shape[0] padded_array = np.zeros((input_depth , input_height + 2 * zp , input_width + 2 * zp)) padded_array[: , zp : zp + input_height , zp : zp + input_width] = input_array return padded_array elif (input_array.ndim == 2): input_width = input_array.shape[1] input_height = input_array.shape[0] padded_array = np.zeros((input_height + 2 * zp , input_width + 2 * zp)) padded_array[zp : zp + input_height , zp : zp + input_width] = input_array return padded_array #對numpy數組進行element wise操作 def element_wise_op(array , op): for i in np.nditer(array , op_flags = [‘readwrite‘]): i[...] = op(i) #卷積核類 class Filter(object): def __init__(self , width , height , depth): self.weights = np.random.uniform(-1e-4 , 1e-4 , (depth , height , width)) self.bias = 0 self.weights_grad = np.zeros(self.weights.shape) self.bias_grad = 0 def __repr__(self): return ‘filter weights : \n%s\nbias : \n%s‘ % (repr(self.weights) , repr(self.bias)) def get_weights(self): return self.weights def get_bias(self): return self.bias def update(self , learning_rate): self.weights -= learning_rate * self.weights_grad self.bias -= learning_rate * self.bias_grad #卷積層類 class ConvLayer(object): def __init__(self , input_width , input_height , channel_number, filter_width , filter_height , filter_number , zero_padding , stride , activator , learning_rate): self.input_width = input_width self.input_height = input_height self.channel_number = channel_number self.filter_width = filter_width self.filter_height = filter_height self.filter_number = filter_number self.zero_padding = zero_padding self.stride = stride self.output_width = ConvLayer.calculate_output_size(self.input_width , filter_width , zero_padding , stride) self.output_height = ConvLayer.calculate_output_size(self.input_height , filter_height , zero_padding , stride) self.output_array = np.zeros((self.filter_number , self.output_height , self.output_width)) self.filters = [] for i in range(filter_number): self.filters.append(Filter(filter_width , filter_height , filter_number)) self.activator = activator self.learning_rate = learning_rate def forward(self , input_array): ‘‘‘ 計算卷積層的輸出 輸出結果保存在self.output_array ‘‘‘ self.input_array = input_array self.padded_input_array = padding(input_array , self.zero_padding) for f in range(self.filter_number): filter = self.filters[f] conv(self.padded_input_array , filter.get_weights() , self.output_array[f] , self.stride , filter.get_bias()) element_wise_op(self.output_array , self.activator.forward) #對輸出的每一個元素做激活操作 def backward(self , input_array , sensitivity_array , activator): ‘‘‘ 計算傳遞給前一層的誤差項,以及計算每個權重的梯度 前一層的誤差項保存在self.delta_array,梯度保存在Filter對象的weights_grad中 ‘‘‘ self.forward(input_array) self.bp_sensitivity_map(sensitivity_array , activator) self.bp_gradient(sensitivity_array) def update(self): ‘‘‘ 按照梯度下降,更新權重 ‘‘‘ for filter in self.filters: filter.update(self.learning_rate) #計算傳遞到上一層的誤差項 def bp_sensitivity_map(self , sensitivity_array , activator): ‘‘‘ 計算傳遞到上一層的sensitivity_map sensitivity_array:本層的sensitivity map activator:上一層的激活函數 ‘‘‘ #處理卷積步長,對原始sensitivity map進行擴展 expanded_array = self.expand_sensitivity_map(sensitivity_array) #full卷積,對sensitivity map進行zero padding #雖然原始輸入的zero padding單元也會獲得殘差,但這個殘差不需要繼續向上傳播,因此就不計算了 expanded_width = expanded_array.shape[2] #zero padding的值 zp = (self.input_width + self.filter_width - 1 - expanded_width) / 2 padded_array = padding(expanded_array , zp) #初始化delta_array,用於保存傳遞到上一層的sensitivity map self.delta_array = self.create_delta_array() #對於具有多個filter的卷積層來說,最終傳遞到上一層的sensitivity map相當於所有filter的sensitivity map之和 #註意:這裏的求和只是針對所有的num求和,而不是針對所有的channel求和; for f in range(self.filter_number): filter = self.filters[f] #將filter的權重翻轉180度 filpped_weights = np.array(map(lambda i : np.rot90(i , 2) , filter.get_weights())) #計算與一個filter對應的delta_array delta_array = self.create_delta_array() for d in range(delta_array.shape[0]): conv(padded_array[f] , filpped_weights[d] , delta_array[d] , 1 , 0) self.delta_array += delta_array #將計算結果與激活函數的偏導數做element-wise懲罰操作 derivative_array = np.array(self.input_array) element_wise_op(derivative_array , activator.backward) self.delta_array *= derivative_array #計算傳遞到上一層的權重梯度 def bp_gradient(self , sensitivity_array): #處理卷積步長,對原始的sensitivity map進行擴展 expanded_array = self.expand_sensitivity_map(sensitivity_array) for f in range(self.filter_number): #計算每個權重的梯度 filter = self.filters[f] for d in range(filter.weights.shape[0]): conv(self.padded_input_array[d] , expanded_array[f] , filter.weights_grad[d] , 1 , 0) #計算偏置項的梯度 filter.bias_grad = expanded_array[f].sum() #對步長不為1的sensitivity map進行擴展,使之還原成stride=1時的情況 def expand_sensitivity_map(self , sensitivity_array): depth = sensitivity_array.shape[0] #確定擴展後sensitivity map的大小 #計算stride為1時的sensitivity map的大小,之所以這麽做是因為後面對於stride不等於1的情況時,進行反向傳播時,都是先還原成stride=1時的情況再做處理 expanded_width = (self.input_width - self.filter_width + 2 * zero_padding + 1) expanded_height = (self.input_height - self.filter_height + 2 * zero_padding + 1) #構建新的sensitivity map expand_array = np.zeros((depth , expanded_height , expanded_width)) #從原始的sensitivity map拷貝誤差值 for i in range(self.output_height): for j in range(self.output_width): i_pos = i * self.stride j_pos = j * self.stride expand_array[: , i_pos , j_pos] = sensitivity_array[: , i , j] #stride = s還原到stride=1時的情況,通過對應位置0進行擴展 return expand_array def create_delta_array(self): return np.zeros((self.channel_number , self.input_height , self.input_width)) @staticmethod def calculate_output_size(input_size , filter_size , zero_padding , stride): return (input_size - filter_size + 2 * zero_padding) / stride + 1
二、池化層
卷積層,池化層等,前向/反向傳播原理講解