
[神經網絡與深度學習(一)]使用神經網絡識別手寫數字
1.1 感知器
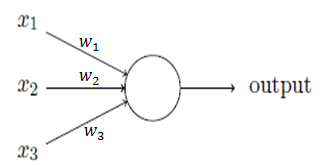
感知器的輸出為:
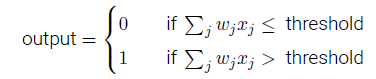
wj為權重,表示相應輸入對輸出的重要性;
threshold為閾值,決定神經元的輸出為0或1。
也可用下式表示:
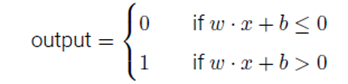
其中b=-threshold,稱為感知器的偏置。
通過學習算法,能夠自動調整人工神經元的權重和偏置。
1.2 S型神經元
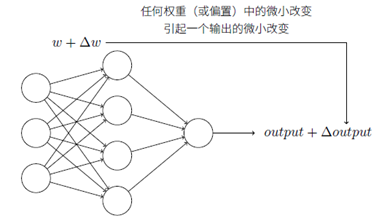
感知器模型中,權重或偏置的微小變化可能導致輸出是0和1的不同,使得調試權重或偏置的工作變得困難。使用S型神經元可以改進這種情況。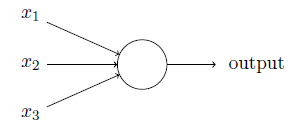
S型神經元的輸出為:
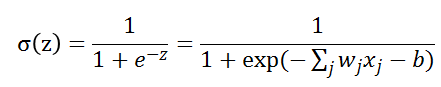
上面函數形狀如下圖:
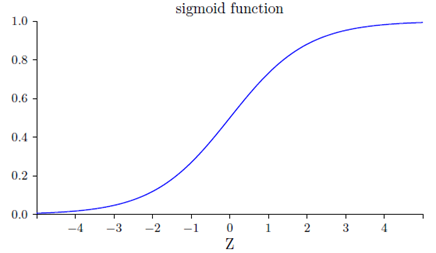
Z為很大的正數時,輸出為1;Z為很大的負數時,輸出為0。
當權重和偏置發生微小的變化時,輸出的變化是:
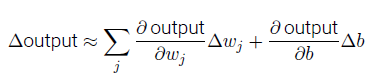
Δoutput 是一個反映權重和偏置變化的線性函數。這一線性使得選擇權重和偏置的微小變化來達到輸出的微小變化的運算變得容易。
1.3 神經網絡的結構
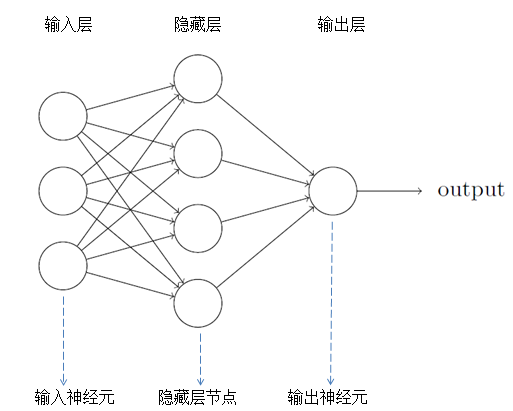
神經網絡一般分為輸入層,隱藏層和輸出層。需要註意兩點:1.有些神經網絡包含著多個隱藏層;2.輸出層的輸出神經元可以為1個或多個。例如手寫數字識別,它的輸出可以為“0”到“9”,一共10個輸出神經元。
1.4 梯度下降法
當設計好一個神經網絡的架構時,它的權重和偏置是未知的。需要用梯度下降法去尋找這些權重w和偏置b的值。
訓練集中,輸入為x,輸出為y(x),定義一個代價函數:
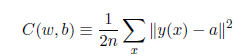
N是訓練輸入數據的個數,a表示輸入為x時的輸出,由x,w和b決定。C稱為二次代價函數,或均方誤差或MSE。如果a的值約等於y(x)(當前輸出等於目標輸出),則說明網絡的權重和偏置設計符合要求。
因此,我們的目標是使C(w,b)約等於0,並求出相應的權重和偏置。
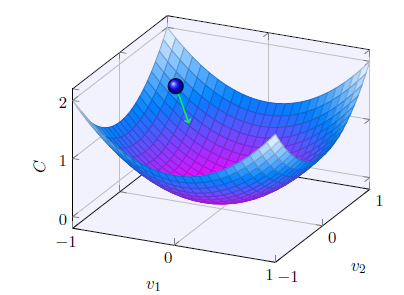
假設C是一個只有兩個變量v1和v2的函數,我們的目標是將小球移動到最低點。上圖中,當球體在v1和v2分別移動很小的量時,C的變化為:
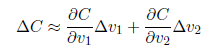
定義v的變化向量為:![]() ,梯度向量為:
,梯度向量為: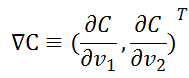
此時,我們選擇v的變化量為: 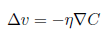 。所以C的變化量可以表示為:
。所以C的變化量可以表示為: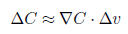
則C的變化量為一個恒小於0的值,可以使得C一直減小,從而找到C的最小值。(為一個很小的正數,稱為學習速率)
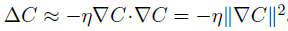
此時,球體的位置表示為:
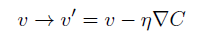
總結一下,梯度下降算法的工作方式就是重復計算梯度?C,然後沿著相反的方向移動,沿著山谷“滾落”。
1.5 神經網絡中的梯度下降法
在神經網絡中使用梯度下降法,主要的目標是尋找能夠使下列方程的代價取得最小值的權重wk和偏置bl。
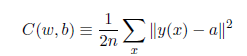
更新規則為:
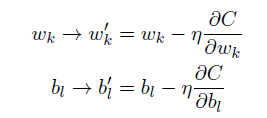
因為每一次更新總需要利用到所有的訓練樣本,為加快訓練時間,可使用隨機梯度下降法,主要的思想就是隨機選取小量訓練樣本來計算梯度變量。
算法:
Step1.隨機選擇m個訓練樣本![]() ,稱為小批量數據。
,稱為小批量數據。
Step2.假設這m個訓練樣本的梯度下降量等於整個訓練樣本的梯度下降量。
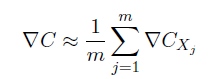
Step3.使用這些數據更新神經網絡的權重和偏置。
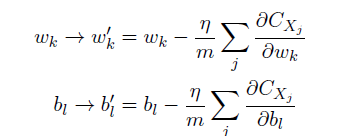
Step4.再挑選另一隨機選定的小批量數據去訓練。直到用完所有的訓練樣本,稱為一個訓練叠代期。
1.6 手寫數字識別的實現

首先,將一個手寫數字圖像分成一個m×n個部分。例如將圖像分成28×28個區域,則輸出層包含了784(28×28)個輸入神經元,其神經網絡的架構如圖。
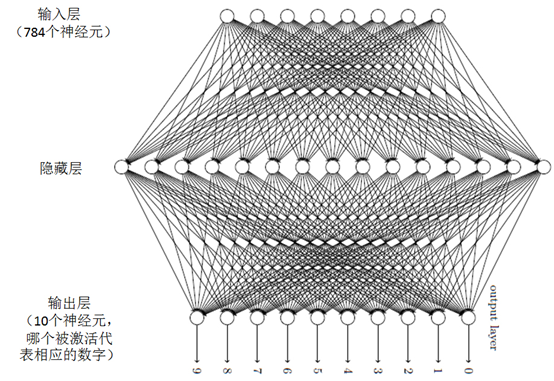
對於輸入神經元,當黑色部分占這個區域超過50%時,則這個神經元的值為1,否則為0。
對於輸出神經元,一共有10個。當第一個神經元被激活,它的輸出為1時,即識別這個數字為0。
[神經網絡與深度學習(一)]使用神經網絡識別手寫數字