
日誌采集框架Flume
概述
- Flume是一個分布式、可靠、和高可用的海量日誌采集、聚合和傳輸的系統。
- Flume可以采集文件,socket數據包等各種形式源數據,又可以將采集到的數據輸出到HDFS、hbase、hive、kafka等眾多外部存儲系統中
- 一般的采集需求,通過對flume的簡單配置即可實現
- Flume針對特殊場景也具備良好的自定義擴展能力,因此,flume可以適用於大部分的日常數據采集場景
運行機制
1、 Flume分布式系統中最核心的角色是agent,flume采集系統就是由一個個agent所連接起來形成
2、 每一個agent相當於一個數據傳遞員,內部有三個組件:
a) Source:采集源,用於跟數據源對接,以獲取數據
b) Sink:下沈地,采集數據的傳送目的,用於往下一級agent傳遞數據或者往最終存儲系統傳遞數據
c) Channel:angent內部的數據傳輸通道,用於從source將數據傳遞到sink
註意:source 到 Channel 到 Sink之間傳遞數據的形式是Event事件;Event事件是一個數據流單元。
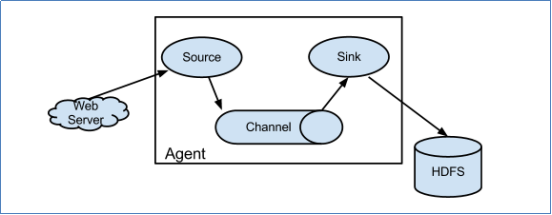
Flume采集系統結構圖
1. 簡單結構
單個agent采集數據
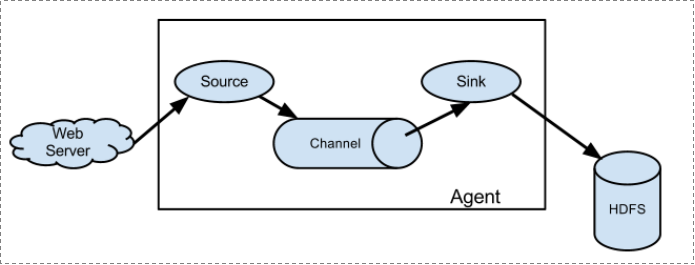
復雜結構
多級agent之間串聯
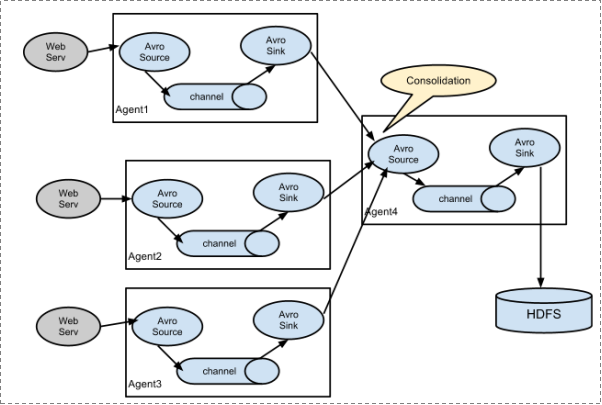
Flume實戰案例
Flume的安裝部署
1、Flume的安裝非常簡單,只需要解壓即可,當然,前提是已有hadoop環境
上傳安裝包到數據源所在節點上
然後解壓 tar -zxvf apache-flume-1.6.0-bin.tar.gz
然後進入flume的目錄,修改conf下的flume-env.sh,在裏面配置JAVA_HOME
2、根據數據采集的需求配置采集方案,描述在配置文件中(文件名可任意自定義)
3、指定采集方案配置文件,在相應的節點上啟動flume agent
先用一個最簡單的例子來測試一下程序環境是否正常
1、先在flume的conf目錄下新建一個文件
vi netcat-logger.conf
# 定義這個agent中各組件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述和配置source組件:r1 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # 描述和配置sink組件:k1 a1.sinks.k1.type = logger # 描述和配置channel組件,此處使用是內存緩存的方式 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 描述和配置source channel sink之間的連接關系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
1、啟動agent去采集數據
|
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console |
-c conf 指定flume自身的配置文件所在目錄
-f conf/netcat-logger.con 指定我們所描述的采集方案
-n a1 指定我們這個agent的名字
1、測試
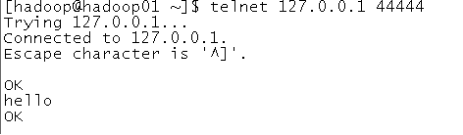
先要往agent采集監聽的端口上發送數據,讓agent有數據可采
隨便在一個能跟agent節點聯網的機器上
telnet anget-hostname port (telnet localhost 44444)
日誌采集框架Flume