
開源數據采集組件比較: scribe、chukwa、kafka、flume
針對每天TB級的數據采集,一般而言,這些系統需要具有以下特征:
- 構建應用系統和分析系統的橋梁,並將它們之間的關聯解耦;
- 支持近實時的在線分析系統和類似於Hadoop之類的離線分析系統;
- 具有高可擴展性。即:當數據量增加時,可以通過增加節點進行水平擴展。
從設計架構,負載均衡,可擴展性和容錯性等方面對開源的個關組件進行說明
FaceBook的Scribe
Scribe是facebook開源的日誌收集系統,在facebook內部已經得到大量的應用。它能夠從各種日誌源上收集日誌,存儲到一個中央存儲系統 (可以是NFS,分布式文件系統等)上,以便於進行集中統計分析處理。它為日誌的“分布式收集,統一處理”提供了一個可擴展的,高容錯的方案
它最重要的特點是容錯性好。當後端的存儲系統crash時,scribe會將數據寫到本地磁盤上,當存儲系統恢復正常後,scribe將日誌重新加載到存儲系統中。
架構:scribe的架構比較簡單,主要包括三部分,分別為scribe agent, scribe和存儲系統。
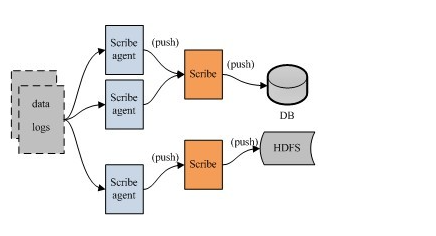
(1) scribe agent
scribe agent實際上是一個thrift client。 向scribe發送數據的唯一方法是使用thrift client, scribe內部定義了一個thrift接口,用戶使用該接口將數據發送給server
(2) scribe
scribe接收到thrift client發送過來的數據,根據配置文件,將不同topic的數據發送給不同的對象。scribe提供了各種各樣的store,如 file, HDFS等,scribe可將數據加載到這些store中。
(3) 存儲系統
存儲系統實際上就是scribe中的store,當前scribe支持非常多的store,包括:
-
- file(文件)
- buffer(雙層存儲,一個主儲存,一個副存儲)
- network(另一個scribe服務器)
- bucket(包含多個 store,通過hash的將數據存到不同store中)
- null(忽略數據)
- thriftfile(寫到一個Thrift TFileTransport文件中)
- multi(把數據同時存放到不同store中)。
Apache的Chukwa
chukwa是一個屬於hadoop系列產品,因而使用了很多hadoop的組件(用HDFS存儲,用mapreduce處理數據),它提供了很多模塊以支持hadoop集群日誌分析。其架構示意圖如下:
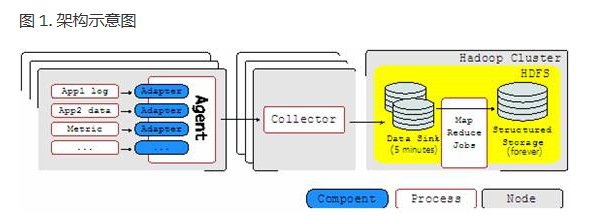
Chukwa中主要有3種角色,分別為:adaptor,agent,collector
Agent
- agent 是駐守在各個節點上的負責收集數據的程序。
- Agent 又由若幹 adapter 組成。
- adapter 運行在 Agent 進程以內,執行實際收集數據的工作。
- 而 Agent 則負責 adapter 的管理(給adaptor提供各種服務,包括:啟動和關閉adaptor,將數據通過HTTP傳遞給Collector;定期記錄adaptor狀態,以便crash後恢復)
Collector
- 對多個數據源發過來的數據進行合並,然後加載到HDFS中;隱藏HDFS實現的細節,如,HDFS版本更換後,只需修改collector即可
HDFS 存儲系統
- Chukwa采用了HDFS作為存儲系統。
- HDFS的設計初衷是支持大文件存儲和小並發高速寫的應用場景,而日誌系統的特點恰好相反,它需支持高並發低速率的寫和大量小文件的存儲。
- 需要註意的是,直接寫到HDFS上的小文件是不可見的,直到關閉文件,另外,HDFS不支持文件重新打開
Demux和achieving
- 直接支持利用MapReduce處理數據。
- 它內置了兩個mapreduce作業,分別用於獲取data和將data轉化為結構化的log。存儲到data store(可以是數據庫或者HDFS等)中
LinkedIn的Kafka
Kafka是2010年12月份開源的項目,采用scala語言編寫,使用了多種效率優化機制,整體架構比較新穎(push/pull),更適合異構集群。主要的設計元素如下:
- afka在設計之時為就將持久化消息作為通常的使用情況進行了考慮。
- 主要的設計約束是吞吐量而不是功能。
- 有關哪些數據已經被使用了的狀態信息保存為數據使用者(consumer)的一部分,而不是保存在服務器之上。
- Kafka是一種顯式的分布式系統。它假設,數據生產者(producer)、代理(brokers)和數據使用者(consumer)分散於多臺機器之上。
架構:
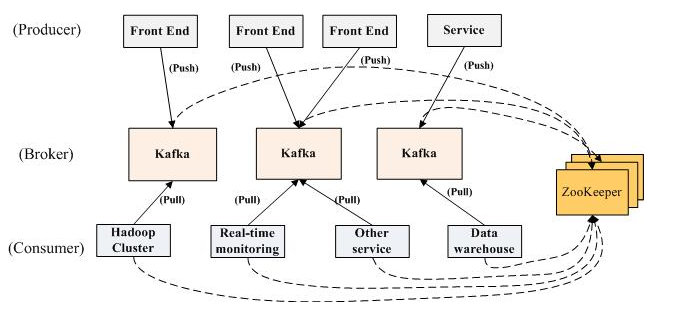
- Kafka實際上是一個消息發布訂閱系統。
- producer向某個topic發布消息,而consumer訂閱某個topic的消息,進而一旦有新的關於某個topic的消息,broker會傳遞給訂閱它的所有consumer。
- 在kafka中,消息是按topic組織的,而每個topic又會分為多個partition,這樣便於管理數據和進行負載均衡。
- 同時,它也使用了zookeeper進行負載均衡。
Kafka中主要有三種角色,分別為producer,broker和consumer
Producer
- Producer的任務是向broker發送數據。
- Kafka提供了兩種producer接口,一種是low_level接口,使用該接口會向特定的broker的某個topic下的某個partition發送數據;另一種那個是high level接口,該接口支持同步/異步發送數據,基於zookeeper的broker自動識別和負載均衡(基於Partitioner)。
- 其中,基於zookeeper的broker自動識別值得一說。producer可以通過zookeeper獲取可用的broker列表,也可以在zookeeper中註冊listener,該listener在以下情況下會被喚醒:
- a.添加一個broker
- b.刪除一個broker
- c.註冊新的topic
- d.broker註冊已存在的topic
Broker
Broker采取了多種策略提高數據處理效率,包括sendfile和zero copy等技術
Consumer
- consumer的作用是將日誌信息加載到中央存儲系統上。
- kafka提供了兩種consumer接口,一種是low level的,它維護到某一個broker的連接,並且這個連接是無狀態的,即,每次從broker上pull數據時,都要告訴broker數據的偏移量。另一種是high-level 接口,它隱藏了broker的細節,允許consumer從broker上push數據而不必關心網絡拓撲結構。
- 更重要的是,對於大部分日誌系統而言,consumer已經獲取的數據信息都由broker保存,而在kafka中,由consumer自己維護所取數據信息。
Cloudera的Flume
Flume是cloudera於2009年7月開源的日誌系統。它內置的各種組件非常齊全,用戶幾乎不必進行任何額外開發即可使用。設計目標如下:
- 可靠性: 當節點出現故障時,日誌能夠被傳送到其他節點上而不會丟失。Flume提供了三種級別的可靠性保障,從強到弱依次分別為:可擴展性 : Flume采用了三層架構,分別問agent,collector和storage,每一層均可以水平擴展。其中,所有agent和collector由master統一管理,這使得系統容易監控和維護,且master允許有多個(使用ZooKeeper進行管理和負載均衡),這就避免了單點故障問題
- end-to-end(收到數據agent首先將event寫到磁盤上,當數據傳送成功後,再刪除;如果數據發送失敗,可以重新發送。)
- Store on failure(這也是scribe采用的策略,當數據接收方crash時,將數據寫到本地,待恢復後,繼續發送)
- Best effort(數據發送到接收方後,不會進行確認)
- 可擴展性:Flume采用了三層架構,分別問agent,collector和storage,每一層均可以水平擴展。其中,所有agent和collector由master統一管理,這使得系統容易監控和維護,且master允許有多個(使用ZooKeeper進行管理和負載均衡),這就避免了單點故障問題
- 可管理性:所有agent和colletor由master統一管理,這使得系統便於維護。用戶可以在master上查看各個數據源或者數據流執行情況,且可以對各個數據源配置和動態加載。Flume提供了web 和shell script command兩種形式對數據流進行管理
- 功能可擴展性: 用戶可以根據需要添加自己的agent,colletor或者storage。此外,Flume自帶了很多組件,包括各種agent(file, syslog等),collector和storage(file,HDFS等)。
架構圖:
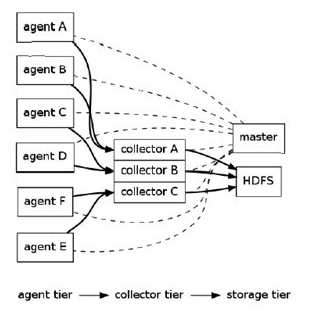
Flume采用了分層架構,由三層組成,分別為agent,collector和storage。其中,agent和collector均由兩部分組成:source和sink,source是數據來源,sink是數據去向。
(1) agent :agent的作用是將數據源的數據發送給collector,Flume自帶了很多直接可用的數據源(source),如:
- text(“filename”):將文件filename作為數據源,按行發送
- tail(“filename”):探測filename新產生的數據,按行發送出去
- fsyslogTcp(5140):監聽TCP的5140端口,並且接收到的數據發送出去
- 同時提供了很多sink,如:
- console[("format")] :直接將將數據顯示在桌面上
- text(“txtfile”):將數據寫到文件txtfile中
- dfs(“dfsfile”):將數據寫到HDFS上的dfsfile文件中
- syslogTcp(“host”,port):將數據通過TCP傳遞給host節點
(2) collector:collector的作用是將多個agent的數據匯總後,加載到storage中。它的source和sink與agent類似。
(3) storage : storage是存儲系統,可以是一個普通file,也可以是HDFS,HIVE,HBase等。
event的相關概念:
flume的核心是把數據從數據源(source)收集過來,在將收集到的數據送到指定的目的地(sink)。為了保證輸送的過程一定成功,在送到目的地(sink)之前,會先緩存數據(channel),待數據真正到達目的地(sink)後,flume在刪除自己緩存的數據。如下圖:
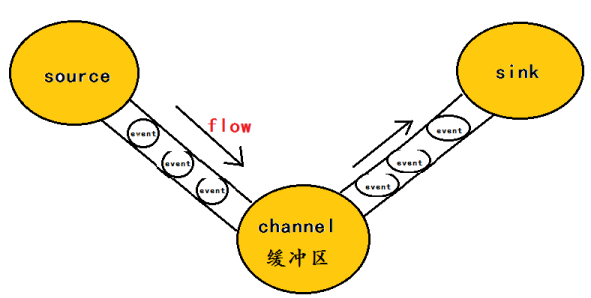
在整個數據的傳輸的過程中,流動的是event,即事務保證是在event級別進行的。那麽什麽是event呢?—–event將傳輸的數據進行封裝,是flume傳輸數據的基本單位,如果是文本文件,通常是一行記錄,event也是事務的基本單位。event從source,流向channel,再到sink,本身為一個字節數組,並可攜帶headers(頭信息)信息。event代表著一個數據的最小完整單元,從外部數據源來,向外部的目的地去。
總結
根據這四個系統的架構設計,可以總結出系統需具備三個基本組件,分別為agent(封裝數據源,將數據源中的數據發送給collector),collector(接收多個agent的數據,並進行匯總後導入後端的store中),store(中央存儲系統,應該具有可擴展性和可靠性,應該支持當前非常流行的HDFS)。
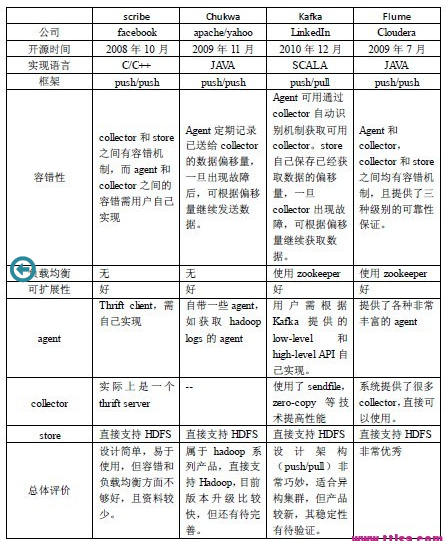
四個系統結果對比分析如下:
參考資料:
- https://www.ibm.com/developerworks/cn/opensource/os-cn-chukwa/
- http://www.open-open.com/lib/view/open1386814790486.html
開源數據采集組件比較: scribe、chukwa、kafka、flume