
2017.08.11 Python網絡爬蟲實戰之Beautiful Soup爬蟲
1.與Scrapy不同的是Beautiful Soup並不是一個框架,而是一個模塊;與Scrapy相比,bs4中間多了一道解析的過程(Scrapy是URL返回什麽數據,程序就接受什麽數據進行過濾),bs4則在接收數據和進行過濾之間多了一個解析的過程,根據解析器的不同,最終處理的數據也有所不同,加上這一步驟的優點是可以根據輸入數據的不同進行針對性的解析;同一選擇lxml解析器;
2.安裝Beautiful Soup環境:pip install beautifulsoup4

3.Beautiful Soup除了支持python標準庫中的HTML解析器外,還支持一些第三方解析器;效率更高
4.安裝lxml解析器:pip install lxml

5.Beautiful Soup的查找數據的方法更加靈活方便,不但可以通過標簽查找,還可以通過標簽屬性來查找,而且bs4還可以配合第三方的解析器,可以針對性的對網頁進行解析,使得bs4威力更加強大,方便
自建一個html的示例文件scenery.html,通過對scenery.html的操作學習bs4模塊:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>泉州旅遊景點</title>
<meta name="description" content="泉州旅遊景點 精簡版"/>
<meta name="author" content="chunyu" >
</head>
<body>
<div id="content">
<div class="title">
<h3>泉州景點</h3>
</div>
<ul>
<li>景點<a>門票價格</a></li>
</ul>
<ul class="content">
<li nu="1">東湖公園<a class="price">60</a></li>
<li nu="2">西湖公園<a class="price">60</a></li>
<li nu="3">華僑大學<a class="price">120</a></li>
<li nu="4">清源山<a class="price">150</a></li>
<li nu="5">文廟<a class="price">60</a></li>
</ul>
</div>
</body>
</html>
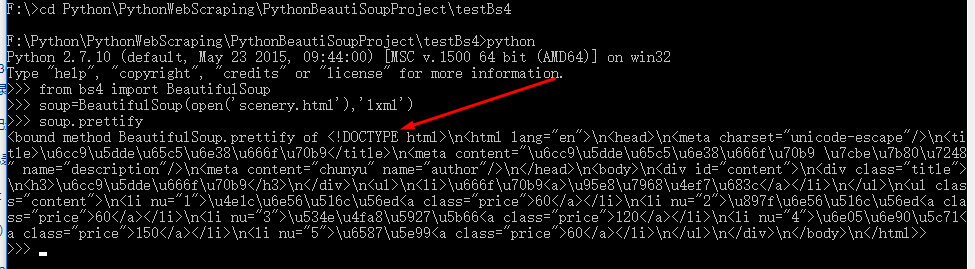
6.進入文件目錄執行命令:
F:\>cd Python\PythonWebScraping\PythonBeautiSoupProject\testBs4
F:\Python\PythonWebScraping\PythonBeautiSoupProject\testBs4>python
>>> from bs4 import BeautifulSoup
>>> soup=BeautifulSoup(open(‘scenery.html‘),‘lxml‘)
>>> soup.prettify
執行結果:
7.一個文件或者一個網頁,在導入BeautifulSoup處理之前,bs4並不知道它的字符編碼是什麽,在導入BeautifulSoup過程中,它會自動猜測這個文件或者網頁的字符編碼,常用的字符編碼當然很快就會猜出來,但是不常用的編碼就需要BeautifulSoup提供的兩個參數解決:exclude_encoding和from_encoding
(1)參數exclude_encoding的作用是排除不正確的字符編碼,例如已經確定非常網頁不是iso-8859-7也不是gb2312編碼,就可以使用命令:
soup=BeautifulSoup(response.read(),exclude_encoding=[‘iso-8859-7‘,‘gb2312‘])
(2)如果已經知道網頁的編碼是big5,也可以直接使用from_encoding參數直接確定編碼:
soup=BeautifulSoup(response.read(),from_encoding=[‘big5‘])
(3)如果不知道文件的字符編碼,而bs4又解析錯誤時,那就只有安裝chardet或者cchardet模塊,然後使用UnicodeDammit自動檢測了
8.解決字符編碼這個問題後,已經得到了soup這個bs4的類。在soup中,bs4將網頁節點解析成一個個Tag;
執行命令:Tag1=soup.ul

9.使用命令soup.find_all(Tag,[attrs])可以獲取所有符合條件的標簽列表,然後直接從列表中讀取就可以了:
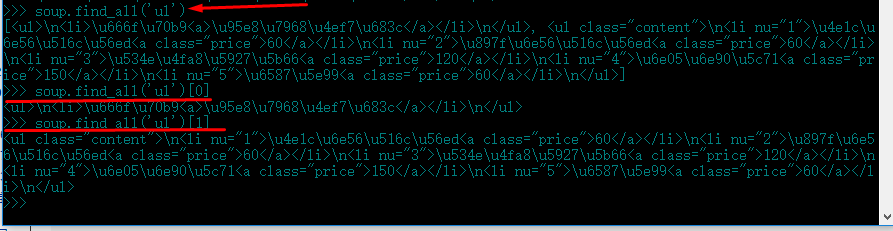
10.從順序上區別同名標簽,這樣出現再多的同名標簽也可以很從容的定位了。在html中,同名標簽比較少,可以用soup.find_all
來獲取標簽位置列表,再一個一個數的方法確定標簽位置,但是如果這個列表太長,就沒法接受了;
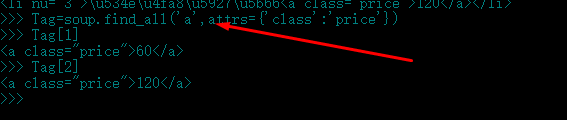
所以,需要使用soup.find和soup.find_all都支持的名字+屬性值定位:

11.如果標簽名相同,屬性相同,連屬性值都相同的標簽,那就用soup.find_all(tagName,attrs={‘attName‘:‘attValue‘})將所有符合條件的標簽裝入列表,然後一個一個的慢慢數吧,本實例中符合此條件的也就是<a>標簽了:
所有<a>標簽的標簽名,屬性和屬性值雖然相同,但是他們的上級標簽(父標簽)標簽名,屬性和屬性值總不可能都相同:

這種不直接定位目標標簽,而是先間接定位目標的上級標簽,再間接定位目標標簽的方法,有點類似於Scrapy中的XPath的嵌套過濾了
12.一般來說,最終獲取保存的不會是標簽,而是標簽裏的數據,這個數據可能是標簽所包含的字符串,也可能是標簽的屬性值
Tag=soup.find(‘li‘,attrs={‘nu‘:‘4‘})
Tag.get(‘nu‘)
Tag.a.get_text()
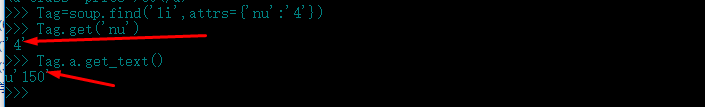
2017.08.11 Python網絡爬蟲實戰之Beautiful Soup爬蟲