
如何實現大數據系統
經常有人問我有關“大數據”的問題,而且多半情況下我們似乎是在各種不同的抽象和理解級別進行交談。實時 和高級分析 之類的詞語頻頻現身,並且我們總是立即開始談論產品,這通常並不是一個好主意。
|
因此我們來回顧一下,從一個用例的角度出發來看看大數據的含義,然後我們可以將該用例與一個可用的高級基礎架構圖對應起來。這些全部完成之後,(我希望)您將開始看到一種模式並開始了解實時 和分析 之類的詞的適用場合。
業務方面的用例
我不打算從頭開始發明什麽,而是觀察了描述 Smartmall 的主題演講用例(在該視頻中您可以看到一個智能商城的漂亮動畫和說明)。
圖 1. Smartmall
Smartmall 背後的思想通常稱為多渠道客戶交互,意即“我如何通過其智能手機與我的實體店中的客戶交互”?相比要求客戶掏出智能手機在互聯網上瀏覽價格,我們寧願主動推動其行為。
Smartmall 的目標相當直接:
- 提高商城內店鋪的流量。
- 增加每次訪問和每筆交易的收益。
- 降低只看不買的百分比。
您需要什麽?
在技術方面,您可能需要:
- 提供個人相關位置信息的智能設備
- 用於實時交互和分析的數據收集點和決策點
- 用於面向批處理的分析的存儲和處理工具
在數據集方面,您可能至少需要:
- 與個人和個人識別設備(電話、會員卡等)相關聯的客戶個人信息
- 與詳細的購買行為相關聯並與優惠券使用、首選產品及其他產品推薦等要素相關聯的非常細粒度的客戶細分
高級組件
一圖勝千言,圖 2 同時顯示了實時決策基礎架構以及批量數據處理和模型生成(分析)基礎架構。
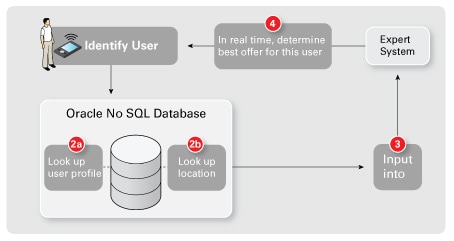
圖 2. 示例基礎架構
第一步,這個理論上最重要的一步,以及最重要的數據塊關乎客戶身份識別。在本例中,第 1 步是攜帶智能電話的用戶走進商城這一實際情況。通過識別這一情況,我們觸發第 2a 步和第 2b 步中在用戶個人信息數據庫中的查詢。
我們稍後將略微詳細地討論這一點,一般來說,這是一個利用索引結構來快速、高效執行查詢的數據庫。一旦查找到實際客戶,就將此客戶的個人信息提供給我們的實時專家系統(第 3 步)。
該專家系統(定制的軟件或 COTS 軟件)中的模型評估提供的數據和個人信息並決定要采取的行動(如發送優惠券)。所有這些都是實時發生的,記住,網站只需數毫秒即可完成這項工作,而我們的智能商城在 1 秒左右完成這項工作就可以了。
為了構建精確的模型(許多典型的大數據熱門詞匯正是來源於此),我們在圖中添加一個面向批處理的大規模處理場。圖 3 下半部分顯示如何利用包括 Apache Hadoop 和 Apache Hadoop 分布式文件系統 (HDFS) 在內的一組組件來創建購買行為模型。傳統上,我們利用數據庫(或數據倉庫 [DW])來實現這一目的。現在我們還是這樣,但現在我們在數據庫/數據倉庫之前利用一個基礎架構來跟蹤更多數據並不斷地重新評估所有數據。
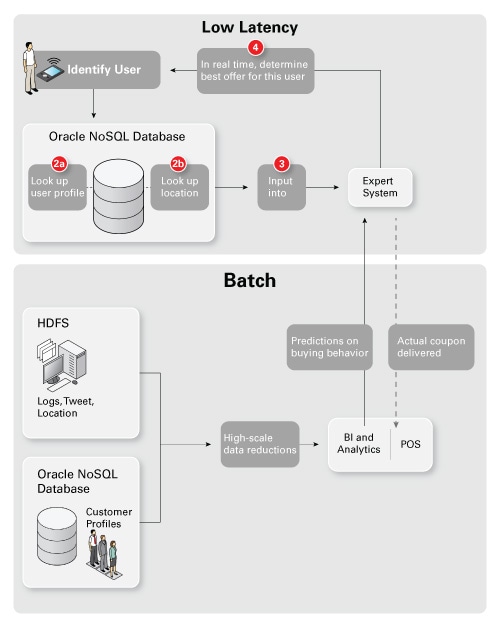
圖 3. 創建購買行為模型
說一下數據源。一個重要元素是銷售點 (POS) 數據(在關系數據庫中),您需要將其與客戶信息(來自網店、手機或會員卡)相關聯。圖 2 和圖 3 中包含客戶個人信息的 NoSQL 數據庫顯示網店元素。非常重要的是,要確保此多渠道數據與 Web 瀏覽、購買、搜索和社交媒體數據相集成(並且執行重復數據刪除,但這是題外話)。
一旦完成數據關聯和數據集成,就可以描繪出個人的行為。本質上,大數據使我們能夠在個人一級進行極細微的細分 — 實際上是對數百萬客戶中的每一位!
這一切的最終目標是構建實時決策引擎中使用的高度精確的模型。此模型的目標與上述業務目標直接相關。換句話說,如何在客戶來到商城時向客戶發送優惠券,讓客戶前往您的店鋪進行消費?
詳細的數據流和產品思路
現在,如何通過實際產品實現這一目標,並且數據在此生態系統中如何流動?下面幾節為您指出答案。
第 1 步:收集數據
要查找數據、收集數據以及根據數據作出決策,您需要實現一個分布式系統。因為設備基本上在不停地發送數據,您需要能夠以較小的延遲加載數據(收集或獲取數據)。這項工作在收集點完成,如圖 4 所示。這裏也是為實時決策而評估數據的位置。稍後我們再回到收集點。
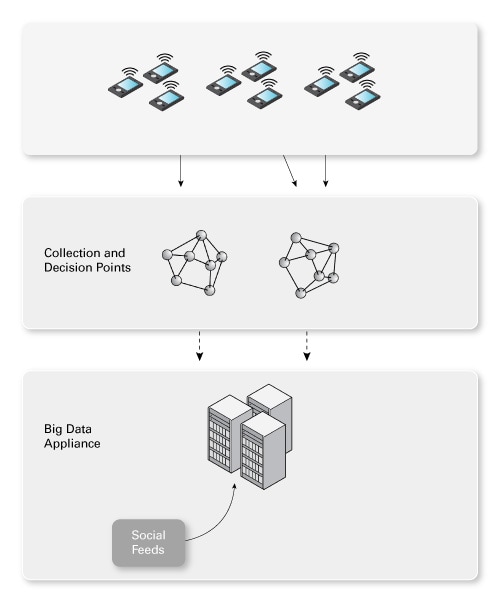
圖 4. 收集點
來自收集點的數據流入 Hadoop 集群(在本例中,即大數據機)。您可能還會將其他數據提供給此設備。例如,圖 4 所示的社交信源將來自分擇相關哈希標記的數據聚合者(通常是一家公司)。然後使用 Flume 或 Scribe 將數據加載到 Hadoop。
第 2 步:整理和移動數據
下一步是添加數據(社交信源、用戶個人信息和使結果與分析相關所需的任何其他數據)和開始整理、解釋和理解數據。
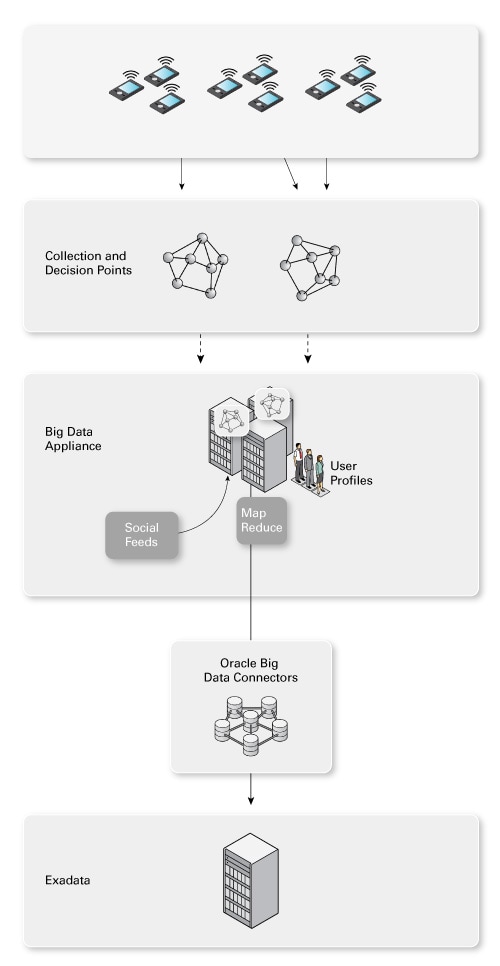
圖 5. 整理和解釋數據
例如,將用戶個人信息添加到社交信源和添加位置數據以建立對各用戶以及用戶相關模式的全面了解。通常,這使用 Apache Hadoop MapReduce 來完成。用戶個人信息通過 Hadoop InputFormat 接口從 Oracle NoSQL 數據庫批量加載,因此被添加到 MapReduce 數據集。
為了將所有這些與 POS 數據、客戶關系管理 (CRM) 數據以及各種其他交易數據結合,您可能會使用 Oracle Big Data Connectors 將精簡的數據高效地移動到 Oracle 數據庫。然後您可以使用 Oracle 商務智能雲服務器 (Exalytics) 或業務智能 (BI) 工具或者(這是比較有趣的地方)通過數據挖掘之類的工具,對您所跟蹤的數據有一個全面的了解。
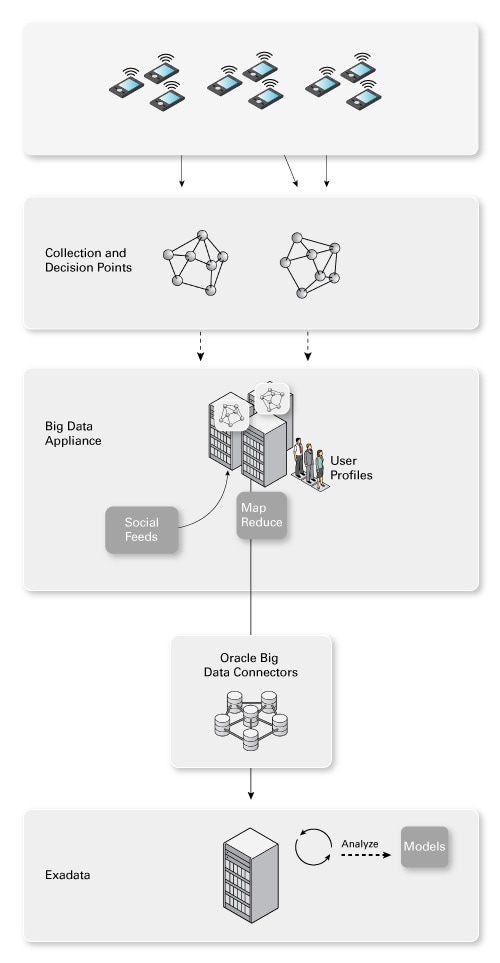
圖 6. 移動精簡數據
第 3 步:分析數據
最後一個階段(這裏稱為“分析”)是創建數據挖掘模型和統計模型以便用於產生合適的優惠券。這些模型真正是皇冠上的明珠,因為它們讓您能夠基於非常精確的模型實時進行決策。模型進入收集點和決策點以作用於實時數據,如圖 7 所示。
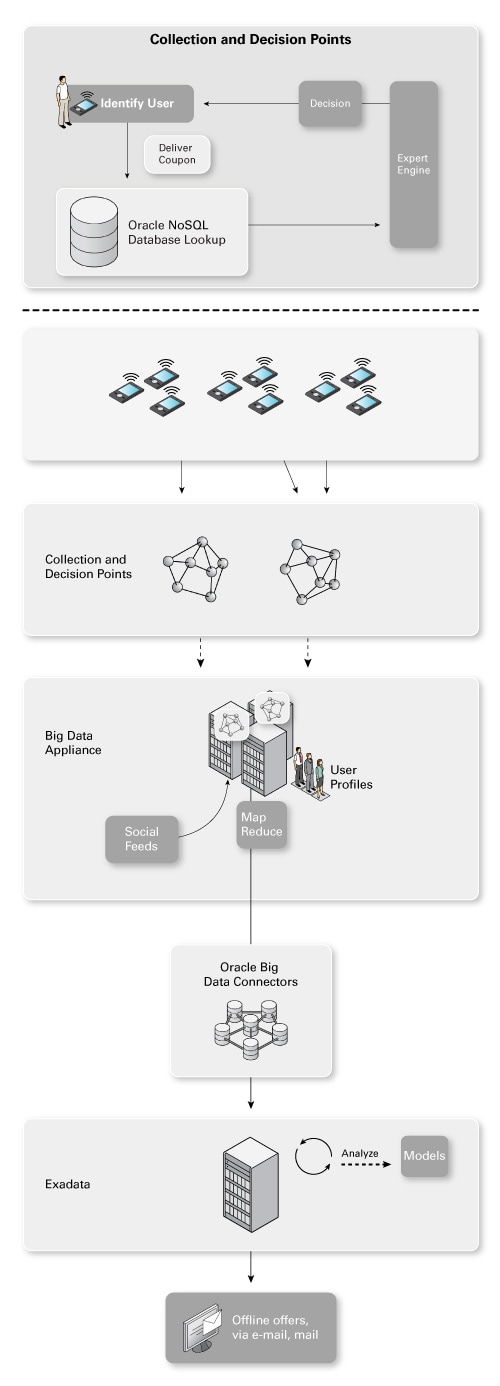
圖 7. 分析數據
在圖 7 中,您可以看到專家引擎中使用了一個灰色的模型。該模型描述和預測客戶個人的行為並基於這些預測確定要采取的行動。
總結
以上所述是對“大數據”和實時決策的端到端觀察。大數據讓我們能夠利用海量的數據和處理資源得出精確的模型。它還讓我們能夠確定以前無法預期的種種事情,從而產生更精確的模型以及新思想、新業務等等。
您可以使用基於 Oracle 技術的 Oracle 大數據機實現在此所展示的整個解決方案。然後就只需找幾個了解編程模型的人即可創建這些皇冠上的明珠。
如何實現大數據系統