
scrapy爬蟲框架實例之一
本實例主要通過抓取慕課網的課程信息來展示scrapy框架抓取數據的過程。
1、抓取網站情況介紹
抓取網站:http://www.imooc.com/course/list
抓取內容:要抓取的內容是全部的課程名稱,課程簡介,課程URL ,課程圖片URL,課程人數(由於動態渲染暫時沒有獲取到)
網站圖片:
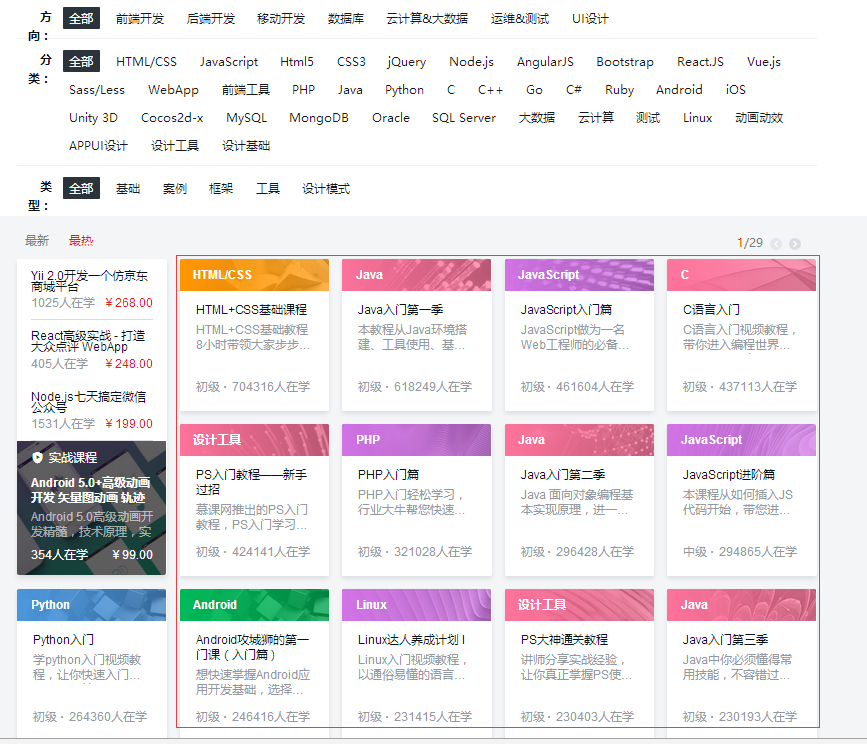
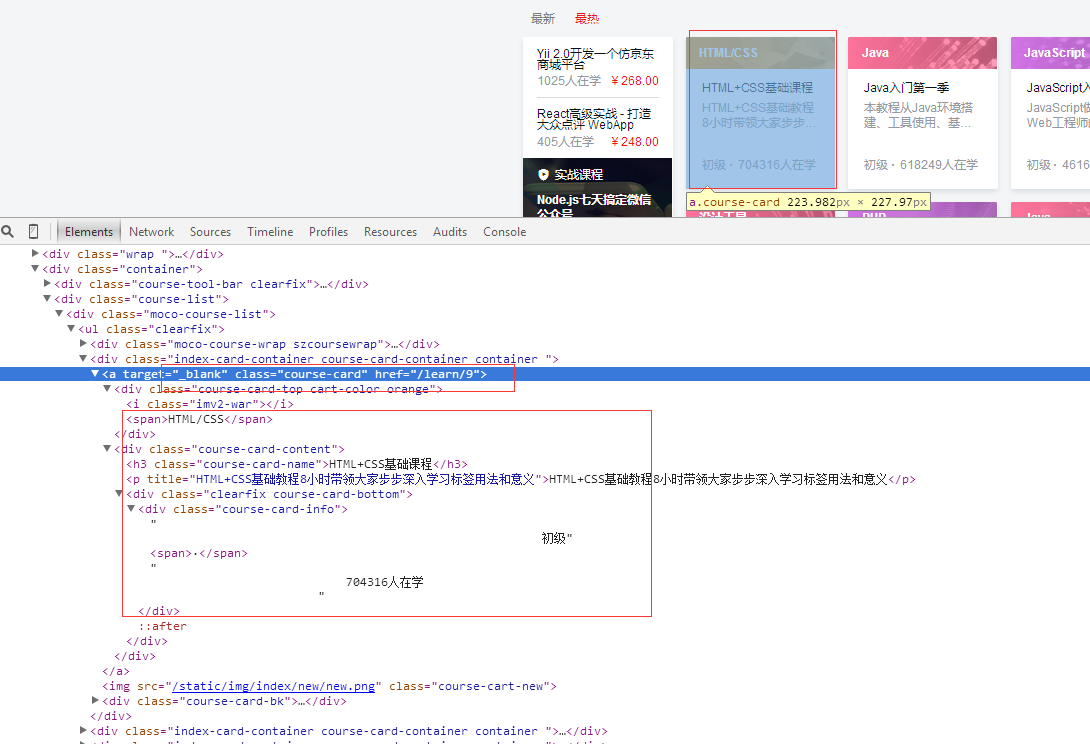

2、建立工程
在命令行模式建立工程
scrapy startproject scrapy_course
建立完成後,用pycharm打開,目錄如下:
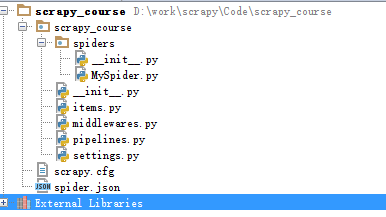
scrapy.cfg: 項目的配置文件
scrapytest/: 該項目的python模塊。之後您將在此加入代碼。
scrapytest/items.py: 項目中的item文件.
scrapytest/pipelines.py: 項目中的pipelines文件.
scrapytest/settings.py: 項目的設置文件.
scrapytest/spiders/: 放置spider代碼的目錄.
3、創建一個爬蟲
下面按步驟講解如何編寫一個簡單的爬蟲。
我們要編寫爬蟲,首先是創建一個Spider
我們在scrapy_course/spiders/目錄下創建一個文件MySpider.py
文件包含一個MySpider類,它必須繼承scrapy.Spider類。
同時它必須定義一下三個屬性:
-name: 用於區別Spider。 該名字必須是唯一的,您不可以為不同的Spider設定相同的名字。
-start_urls: 包含了Spider在啟動時進行爬取的url列表。 因此,第一個被獲取到的頁面將是其中之一。 後續的URL則從初始的URL獲取到的數據中提取。
-parse() 是spider的一個方法。 被調用時,每個初始URL完成下載後生成的 Response 對象將會作為唯一的參數傳遞給該函數。 該方法負責解析返回的數據(response data),提取數據(生成item)以及生成需要進一步處理的URL的 Request 對象。
scrapy爬蟲框架實例之一