
提高程式碼逼格的利器:巨集定義-從入門到放棄
阿新 • • 發佈:2021-02-07
[TOC] ## 一、前言 一直以來,我都有這樣一種感覺:當我學習一個新領域的知識時,如果其中的某個知識點在剛開始接觸時,我感覺比較難懂、不好理解,那麼以後不論我花多長時間去研究這個知識點,心裡會一直認為該知識點比較難,也就是說第一印象特別的重要。 就比如 C 語言中的巨集定義,好像跟我犯衝一樣,我一直覺得巨集定義是 C 語言中最難的部分,就好比有有些小夥伴一直覺得指標是 C 語言中最難的部分一樣。 巨集的本質就是程式碼生成器,在前處理器的支援下實現程式碼的動態生成,具體的操作通過條件編譯和巨集擴充套件來實現。我們先在心中建立這麼一個基本的概念,然後通過實際的描述和程式碼來深入的體會:如何駕馭巨集定義。 所以,今天我們就來把巨集定義所有的知識點進行彙總、深挖,希望經過這篇文章,我能夠擺脫心理的這個魔障。看完這篇總結文章後,我相信你也一定能夠對巨集定義有一個總體、全域性的把握。 ## 二、前處理器的操作 #### 1. 巨集的生效環節:預處理 一個 C 程式在編譯的時候,從原始檔開始到最後生成二進位制可執行檔案,一共經歷 4 個階段: 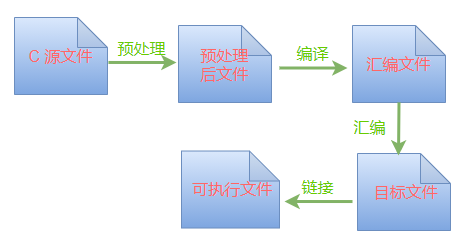 我們今天討論的內容就是在第一個環節:預處理,由前處理器來完成這個階段的工作,包括下面這 4 項工作: > 1. 檔案引入(#include); > 2. 條件編譯(#if..#elif..#endif); > 3. 巨集擴充套件(macro expansions); > 4. 行控制(line control)。 #### 2. 條件編譯 一般情況下,C 語言檔案中的每一行程式碼都是要被編譯的,但是有時候出於對程式程式碼優化的考慮,希望只對其中的一部分程式碼進行編譯,此時就需要在程式中加上條件,讓編譯器只對滿足條件的程式碼進行編譯,將不滿足條件的程式碼捨棄,這就是條件編譯。 簡單的說:就是前處理器根據我們設定的條件,對程式碼進行動態的處理,把有效的程式碼輸出到一箇中間檔案,然後送給編譯器進行編譯。 條件編譯基本上在所有的專案程式碼中都被使用到,例如:當你需要考慮下面的幾種情況時,就一定會使用條件編譯: > 1. 需要把程式編譯成不同平臺下的可執行程式; > 2. 同一套程式碼需要執行在同一平臺上的不同功能產品上; > 3. 在程式中存在著一些測試目的的程式碼,不想汙染產品級的程式碼,需要遮蔽掉。 這裡舉 3 個例子,在程式碼中經常看到的關於條件編譯: 示例1:用來區分 C 和 C++ 程式碼 ``` #ifdef __cplusplus extern "C" { #endif void hello(); #ifdef __cplusplus } #endif ``` 這樣的程式碼幾乎在每個開源庫中都可能見到,主要的目的就是 C 和 C++ 混合程式設計,具體來說就是: > 1. 如果使用 gcc 來編譯,那麼巨集 __cplusplus 將不存在,其中的 extern "C" 將會被忽略; > 2. 如果使用 g++ 來編譯,那麼巨集 __cplusplus 就存在,其中的 extern "C" 就發生作用,編譯出來的函式名 hello 就不會被 g++ 編譯器改寫,因此就可以被 C 程式碼來呼叫; 示例2:用來區分不同的平臺 ``` #if defined(linux) || defined(__linux) || defined(__linux__) sleep(1000 * 1000); // 呼叫 Linux 平臺下的庫函式 #elif defined(WIN32) || defined(_WIN32) Sleep(1000 * 1000); // 呼叫 Windows 平臺下的庫函式(第一個字母是大寫) #endif ``` 那麼,這些 `linux, __linux, __linux__, WIN32, _WIN32` 是從哪裡來的呢?我們可以認為是編譯目標平臺(作業系統)為我們預先準備好的。 示例3:在編寫 Windows 平臺下的動態庫時,宣告匯出和匯入函式 ``` #if defined(linux) || defined(__linux) || defined(__linux__) #define LIBA_API #else #ifdef LIBA_STATIC #define LIBA_API #else #ifdef LIBA_API_EXPORTS #define LIBA_API __declspec(dllexport) #else #define LIBA_API __declspec(dllimport) #endif #endif #endif LIBA_API void hello(); ``` 這段程式碼是直接從我之前在 B 站錄製的一個小視訊裡的示例拿過來的,當時主要是演示如何如何在 Linux 平臺下使用 make 和 cmake 構建工具來編譯,後來又小夥伴讓我在 Windows 平臺下也用 make 和 cmake 來構建,所以就寫了上面這段巨集定義。 > 1. 在使用 MSVC 編譯動態庫時,需要在編譯選項(Makefle 或者 CMakeLists.txt)中定義巨集 LIBA_API_EXPORTS,那麼匯出函式 hello 的最前面的巨集 LIBA_API 就會被替換成:__declspec(dllexport),表示匯出操作; > 2. 在編譯應用程式的時候,使用動態庫,需要 include 動態庫的標頭檔案,此時在編譯選項中不需要定義巨集 LIBA_API_EXPORTS,那麼 hello 函式最前面的 LIBA_API 就會被替換成 __declspec(dllimport),表示匯入操作; > 3. 補充一點:如果使用靜態庫,編譯選項中不需要任何巨集定義,那麼巨集 LIBA_API 就為空。 #### 3. 平臺預定義的巨集 上面已經看到了,目標平臺會為我們預先定義好一些巨集,方便我們在程式中使用。除了上面的作業系統相關巨集,還有另一類巨集定義,在日誌系統中被廣泛的使用: > __FILE__:當前原始碼檔名; > __LINE__:當前原始碼的行號; > __FUNCTION__:當前執行的函式名; > __DATE__: 編譯日期; > __TIME__: 編譯時間; 例如: ``` printf("file name: %s, function name = %s, current line:%d \n", __FILE__, __FUNCTION__, __LINE__); ``` ## 三、巨集擴充套件 所謂的巨集擴充套件就是程式碼替換,這部分內容也是我想表達的主要內容。巨集擴充套件最大的好處有如下幾點: > 1. 減少重複的程式碼; > 2. 完成一些通過 C 語法無法實現的功能(字串拼接); > 3. 動態定義資料型別,實現類似 C++ 中模板的功能; > 4. 程式更容易理解、修改(例如:數字、字串常亮); 我們在寫程式碼的時候,所有使用巨集名稱的地方,都可以理解為一個佔位符。在編譯程式的預處理環節,這些巨集名將會被替換成巨集定義中的那些程式碼段,注意:僅僅是單純的文字替換。 #### 1. 最常見的巨集 為了方便後面的描述,先來看幾個常見的巨集定義: (1) 資料型別的定義 ``` #ifndef BOOL typedef char BOOL; #endif #ifndef TRUE #define TRUE #endif #ifndef FALSE #define FALSE #endif ``` 在資料型別定義中,需要注意的一點是:如果你的程式需要用不同平臺下的編譯器來編譯,那麼你要去查一下所使用的編譯器對這些巨集定義控制的資料型別是否已經定義了。例如:在 gcc 中沒有 BOOL 型別,但是在 MSVC 中,把 BOOL 型別定義為 int 型。 (2) 獲取最大、最小值 ``` #define MAX(a, b) (((a) > (b)) ? (a) : (b)) #define MIN(a, b) (((a) < (b)) ? (a) : (b)) ``` (3) 計算陣列中的元素個數 ``` #define ARRAY_SIZE(x) (sizeof(x) / sizeof((x)[0])) ``` (4) 位操作 ``` #define BIT_MASK(x) (1 << (x)) #define BIT_GET(x, y) (((x) >> (y)) & 0x01u) #define BIT_SET(x, y) ((x) | (1 << (y))) #define BIT_CLR(x, y) ((x) & (~(1 << (y)))) #define BIT_INVERT(x, y) ((x) ^ (1 << (y))) ``` #### 2. 與函式的區別 從上面這幾個巨集來看,所有的這些操作都可以通過函式來實現,那麼他們各有什麼優缺點呢? 通過函式來實現: > 1. 形參的型別需要確定,呼叫時對引數進行檢查; > 2. 呼叫函式時需要額外的開銷:操作函式棧中的形參、返回值等; 通過巨集來實現: > 1. 不需要檢查引數,更靈活的傳參; > 2. 直接對巨集進行程式碼擴充套件,執行時不需要函式呼叫; > 3. 如果同一個巨集在多處呼叫,會增加程式碼體積; 還是舉一個例子來說明比較好,就拿上面的比較大小來說吧: (1) 使用巨集來實現 ``` #define MAX(a, b) (((a) > (b)) ? (a) : (b)) int main() { printf("max: %d \n", MAX(1, 2)); } ``` (2) 使用函式來實現 ``` int max(int a, int b) { if (a > b) return a; return b; } int main() { printf("max: %d \n", max(1, 2)); } ``` 除了函式呼叫的開銷,其它看起來沒有差別。這裡比較的是 2 個整型資料,那麼如果還需要比較 2 個浮點型資料呢? > 1. 使用巨集來呼叫:MAX(1.1, 2.2);一切 OK; > 2. 使用函式呼叫:max(1.1, 2.2); 編譯報錯:型別不匹配。 此時,使用巨集來實現的優勢就體現出來了:因為巨集中沒有型別的概念,呼叫者傳入任何資料型別都可以,然後在後面的比較操作中,大於或小於操作都是利用了 C 語言本身的語法來執行。 如果使用函式來實現,那麼就必須再定義一個用來操作浮點型的函式,以後還有可能比較:char 型、long 型資料等等。 在 C++ 中,這樣的操作可以通過引數模板來實現,所謂的模板也是一種程式碼動態生成機制。當定義了一個函式模板後,根據呼叫者的實參,來動態產生多個函式。例如定義下面這個函式模板: ```