
sqoop用法之mysql與hive資料匯入匯出
阿新 • • 發佈:2020-12-23
[TOC]
## 一. Sqoop介紹
`Sqoop`是一個用來將`Hadoop`和關係型資料庫中的資料相互轉移的工具,可以將一個關係型資料庫(例如:`MySQL、Oracle、Postgres`等)中的資料導進到`Hadoop`的`HDFS`中,也可以將`HDFS`的資料導進到關係型資料庫中。對於某些`NoSQL`資料庫它也提供了聯結器。`Sqoop`,類似於其他`ETL`工具,使用元資料模型來判斷資料型別並在資料從資料來源轉移到`Hadoop`時確保型別安全的資料處理。`Sqoop`專為大資料批量傳輸設計,能夠分割資料集並建立`Hadoop`任務來處理每個區塊。
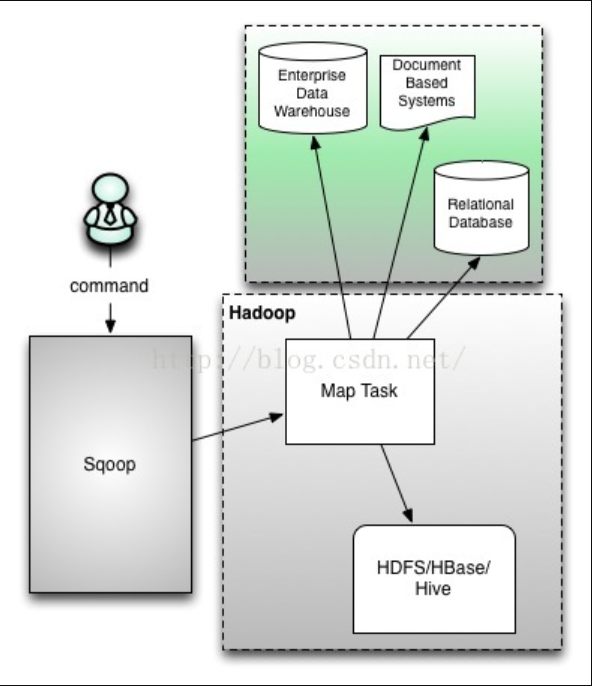
**本文版本說明**
>`hadoop`版本 : `hadoop-2.7.2`
>`hive版本` : `hive-2.1.0`
>sqoop版本:`sqoop-1.4.6`
## 二. Mysql 資料匯入到 Hive
1). 將`mysql`的`people_access_log`表匯入到`hive`表`web.people_access_log`,並且`hive`中的表不存在。
`mysql`中表`people_access_log`資料為:
```java
1,15110101010,1577003281739,'112.168.1.2','https://www.baidu.com'
2,15110101011,1577003281749,'112.16.1.23','https://www.baidu.com'
3,15110101012,1577003281759,'193.168.1.2','https://www.taobao.com'
4,15110101013,1577003281769,'112.18.1.2','https://www.baidu.com'
5,15110101014,1577003281779,'112.168.10.2','https://www.baidu.com'
6,15110101015,1577003281789,'11.168.1.2','https://www.taobao.com'
```
將`mysql`資料匯入`hive`的命令為:
```bash
sqoop import \
--connect jdbc:mysql://master1.hadoop:3306/test \
--username root \
--password 123456 \
--table people_access_log \
-m 1 \
--hive-import \
--create-hive-table \
--fields-terminated-by '\t' \
--hive-table web.people_access_log
```
該命令會啟用一個`mapreduce`任務,將`mysql`資料匯入到`hive`表,並且指定了`hive`表的分隔符為`\t`,如果不指定則為預設分隔符`^A(ctrl+A)`。
**引數說明**
|引數|說明|
|:---:|:---:|
|`--connect`|`mysql`的連線資訊|
|`--username`|`mysql`的使用者名稱|
|`--password`|`mysql`的密碼|
|`--table`|被匯入的`mysql`源表名|
|`-m`|並行匯入啟用的`map`任務數量,與`--num-mapper`含義一樣|
|`--hive-import`|插入資料到`hive`當中,使用`hive`預設的分隔符,可以使用`--fields-terminated-by`引數來指定分隔符。|
|`-- hive-table`|hive當中的表名|
2). 也可以通過`--query`條件查詢`Mysql`資料,將查詢結果匯入到`Hive`
```bash
sqoop import \
--connect jdbc:mysql://master1.hadoop:3306/test \
--username root \
--password 123456 \
--query 'select * from people_access_log where \$CONDITIONS and url = "https://www.baidu.com"' \
--target-dir /user/hive/warehouse/web/people_access_log \
--delete-target-dir \
--fields-terminated-by '\t' \
-m 1
```
|引數|說明|
|:---:|:---:|
|`--query`|後接查詢語句,條件查詢需要`\$CONDITIONS and`連線查詢條件,這裡的`\$`表示轉義`$`,必須有.|
|`--delete-target-dir`|如果目標`hive`表目錄存在,則刪除,相當於`overwrite`.|
## 三. Hive資料匯入到Mysql
還是使用上面的`hive`表`web.people_access_log`,將其匯入到`mysql`中的`people_access_log_out`表中.
```bash
sqoop export \
--connect jdbc:mysql://master1.hadoop:3306/test \
--username root \
--password 123456 \
--table people_access_log_out \
--input-fields-terminated-by '\t' \
--export-dir /user/hive/warehouse/web.db/people_access_log \
--num-mappers 1
```
注意:`mysql`表`people_access_log_out`需要提前建好,否則報錯:`ErrorException: Table 'test.people_access_log_out' doesn't exist`。如果有`id`自增列,`hive`表也需要有,`hive`表與`mysql`表字段必須完全相同。
```sql
create table people_access_log_out like people_access_log;
```
執行完一個`mr`任務後,成功匯入到`mysql`表`people_access_log_out`中.
## 四. mysql資料增量匯入hive
實際中`mysql`資料會不斷增加,這時候需要用`sqoop`將資料增量匯入`hive`,然後進行海量資料分析統計。增量資料匯入分兩種,一是基於遞增列的增量資料匯入(`Append`方式)。二是基於時間列的增量資料匯入(`LastModified`方式)。有幾個核心引數:
- `–check-column`:用來指定一些列,這些列在增量匯入時用來檢查這些資料是否作為增量資料進行匯入,和關係型資料庫中的自增欄位及時間戳類似.**注意**:這些被指定的列的型別不能使任意字元型別,如char、varchar等型別都是不可以的,同時`–check-column`可以去指定多個列
- `–incremental`:用來指定增量匯入的模式,兩種模式分別為`Append`和`Lastmodified`
- `–last-value`:指定上一次匯入中檢查列指定欄位最大值
### 1. 基於遞增列Append匯入
接著前面的日誌表,裡面每行有一個唯一標識自增列`ID`,在關係型資料庫中以主鍵形式存在。之前已經將id在`0~6`之間的編號的訂單匯入到`Hadoop`中了(這裡為`HDFS`),現在一段時間後我們需要將近期產生的新的訂 單資料匯入`Hadoop`中(這裡為`HDFS`),以供後續數倉進行分析。此時我們只需要指定`–incremental` 引數為`append`,`–last-value`引數為`6`即可。表示只從`id`大於`6`後即`7`開始匯入。
#### 1). 建立`hive`表
首先我們需要建立一張與`mysql`結構相同的`hive`表,假設指定欄位分隔符為`\t`,後面匯入資料時候分隔符也需要保持一致。
#### 2). 建立`job`
增量匯入肯定是多次進行的,可能每隔一個小時、一天等,所以需要建立計劃任務,然後定時執行即可。我們都知道`hive`的資料是存在`hdfs`上面的,我們建立`sqoop job`的時候需要指定`hive`的資料表對應的`hdfs`目錄,然後定時執行這個`job`即可。
當前`mysql`中資料,`hive`中資料與`mysql`一樣也有6條:
|`id`|`user_id`|`access_time`|`ip`|`url`|
|:---:|:---:|:---:|:---:|:---:|
|1|15110101010|1577003281739|112.168.1.2|https://www.baidu.com|
|2|15110101011|1577003281749|112.16.1.23|https://www.baidu.com|
|3|15110101012|1577003281759|193.168.1.2|https://www.taobao.com|
|4|15110101013|1577003281769|112.18.1.2|https://www.baidu.com|
|5|15110101014|1577003281779|112.168.10.2|https://www.baidu.com|
|6|15110101015|1577003281789|11.168.1.2|https://www.taobao.com|
增量匯入有幾個引數,保證下次同步的時候可以接著上次繼續同步.
```bash
sqoop job --create mysql2hive_job -- import \
--connect jdbc:mysql://master1.hadoop:3306/test \
--username root \
--password 123456 \
--table people_access_log \
--target-dir /user/hive/warehouse/web.db/people_access_log \
--check-column id \
--incremental append \
--fields-terminated-by '\t' \
--last-value 6 \
-m 1
```
這裡通過`sqoop job --create job_name`命令建立了一個名為`mysql2hive_job`的`sqoop job`。
#### 3). 執行job
建立好了`job`,後面只需要定時週期執行這個提前定義好的`job`即可。我們先往`mysql`裡面插入2條資料。
```sql
INSERT INTO `people_access_log` (`id`,`user_id`,`access_time`,`ip`,`url`) VALUES
(7,15110101016,1577003281790,'112.168.1.3','https://www.qq.com'),
(8,15110101017,1577003281791,'112.1.1.3','https://www.microsoft.com');
```
這樣`mysql`裡面就會多了2條資料。此時`hive`裡面只有`id`為`1 ~ 6`的資料,執行同步`job`使用以下命令。
```bash
sqoop job -exec mysql2hive_job
```
執行完成後,發現剛才`mysql`新加入的`id`為`7 ~ 8`的兩條資料已經同步到`hive`。
```sql
hive> select * from web.people_access_log;
OK
1 15110101010 1577003281739 112.168.1.2 https://www.baidu.com
2 15110101011 1577003281749 112.16.1.23 https://www.baidu.com
3 15110101012 1577003281759 193.168.1.2 https://www.taobao.com
4 15110101013 1577003281769 112.18.1.2 https://www.baidu.com
5 15110101014 1577003281779 112.168.10.2 https://www.baidu.com
6 15110101015 1577003281789 11.168.1.2 https://www.taobao.com
7 15110101016 1577003281790 112.168.1.3 https://www.qq.com
8 15110101017 1577003281791 112.1.1.3 https://www.microsoft.com
```
由於實際場景中,`mysql`表中的資料,比如訂單表等,通常是一致有資料進入的,這時候只需要將`sqoop job -exec mysql2hive_job`這個命令定時(比如說10分鐘頻率)執行一次,就能將資料10分鐘同步一次到`hive`資料倉庫。
### 2. `Lastmodified` 匯入實戰
`append`適合業務系統庫,一般業務系統表會通過自增ID作為主鍵標識唯一性。`Lastmodified`適合`ETL`的資料根據時間戳欄位匯入,表示只匯入比這個時間戳大,即比這個時間晚的資料。
#### 1). 新建一張表
在`mysql`中新建一張表`people_access_log2`,並且初始化幾條資料:
```sql
CREATE TABLE `people_access_log2` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`user_id` bigint(20) unsigned NOT NULL COMMENT '使用者id',
`access_time` timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`ip` varchar(15) NOT NULL COMMENT '訪客ip',
`url` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
```
插入資料:
```sql
insert into people_access_log2(id,user_id, ip, url) values(1,15110101010,'112.168.1.200','https://www.baidu.com');
insert into people_access_log2(id,user_id, ip, url) values(2,15110101011,'112.16.1.2','https://www.baidu.com');
insert into people_access_log2(id,user_id, ip, url) values(3,15110101012,'112.168.1.2','https://www.taobao.com');
insert into people_access_log2(id,user_id, ip, url) values(4,15110101013,'112.168.10.2','https://www.baidu.com');
insert into people_access_log2(id,user_id, ip, url) values(5,15110101014,'112.168.1.2','https://www.jd.com');
insert into people_access_log2(id,user_id, ip, url) values(6,15110101015,'112.168.12.4','https://www.qq.com');
```
`mysql`裡面的資料就是這樣:
|id|user_id|access_time|ip|url|
|:---:|:---:|:---:|:---:|:---:|
|`1`|`15110101010`|`2019-12-28 16:23:10`|`112.168.1.200`|`https://www.baidu.com`|
|`2`|`15110101011`|`2019-12-28 16:23:33`|`112.16.1.2`|`https://www.baidu.com`|
|`3`|`15110101012`|`2019-12-28 16:23:41`|`112.168.1.2`|`https://www.taobao.com`|
|`4`|`15110101013`|`2019-12-28 16:23:46`|`112.168.10.2`|`https://www.baidu.com`|
|`5`|`15110101014`|`2019-12-28 16:23:52`|`112.168.1.2`|`https://www.jd.com`|
|`6`|`15110101015`|`2019-12-28 16:23:56`|`112.168.12.4`|`https://www.qq.`|
#### 2). 初始化`hive`表:
初始化`hive`資料,將`mysql`裡面的`6`條資料匯入`hive`中,並且可以自動幫助我們建立對應`hive`表,何樂而不為,否則我們需要自己手動建立,完成初始化工作。
```bash
sqoop import \
--connect jdbc:mysql://master1.hadoop:3306/test \
--username root \
--password 123456 \
--table people_access_log2 \
--hive-import \
--create-hive-table \
--fields-terminated-by ',' \
--hive-table web.people_access_log2
```
可以看到執行該命令後,啟動了二一個`mapreduce`任務,這樣6條資料就進入`hive`表`web.people_access_log2`了:
```sql
hive> select * from web.people_access_log2;
OK
1 15110101010 2019-12-28 16:23:10.0 112.168.1.200 https://www.baidu.com
2 15110101011 2019-12-28 16:23:33.0 112.16.1.2 https://www.baidu.com
3 15110101012 2019-12-28 16:23:41.0 112.168.1.2 https://www.taobao.com
4 15110101013 2019-12-28 16:23:46.0 112.168.10.2 https://www.baidu.com
5 15110101014 2019-12-28 16:23:52.0 112.168.1.2 https://www.jd.com
6 15110101015 2019-12-28 16:23:56.0 112.168.12.4 https://www.qq.com
Time taken: 0.326 seconds, Fetched: 6 row(s)
```
#### 3). 增量匯入資料:
我們再次插入一條資料進入`mysql`的`people_access_log2`表:
```sql
insert into people_access_log2(id,user_id, ip, url) values(7,15110101016,'112.168.12.45','https://www.qq.com');
```
此時,`mysql`表裡面已經有`7`條資料了,我們使用`incremental`的方式進行增量的匯入到`hive`:
```bash
sqoop import \
--connect jdbc:mysql://master1.hadoop:3306/test \
--username root \
--password 123456 \
--table people_access_log2 \
--hive-import \
--hive-table people_access_log2 \
-m 1 \
--check-column access_time \
--incremental lastmodified \
--last-value "2019-12-28 16:23:56" \
```
`2019-12-28 16:23:56`就是第6條資料的時間,這裡需要指定。報錯了:
```
19/12/28 16:17:25 ERROR tool.ImportTool: Error during import: --merge-key or --append is required when using --incremental lastmodified and the output directory exists.
```
**注意**:可以看到`--merge-key or --append is required when using --incremental lastmodified`意思是,這種基於時間匯入模式,需要指定`--merge-key`或者`--append`引數,表示根據時間戳匯入,資料是直接在末尾追加(append)還是合併(merge),這裡使用`merge`方式,根據`id`合併:
```bash
sqoop import \
--connect jdbc:mysql://master1.hadoop:3306/test \
--username root \
--password 123456 \
--table people_access_log2 \
--hive-import \
--hive-table web.people_access_log2 \
--check-column access_time \
--incremental lastmodified \
--last-value "2019-12-28 16:23:56" \
--fields-terminated-by ',' \
--merge-key id
```
執行該命令後,與直接匯入不同,該命令啟動了2個`mapreduce`任務,這樣就把資料增量`merge`匯入`hive`表了.
```sql
hive> select * from web.people_access_log2 order by id;
OK
1 15110101010 2019-12-28 16:23:10.0 112.168.1.200 https://www.baidu.com
2 15110101011 2019-12-28 16:23:33.0 112.16.1.2 https://www.baidu.com
3 15110101012 2019-12-28 16:23:41.0 112.168.1.2 https://www.taobao.com
4 15110101013 2019-12-28 16:23:46.0 112.168.10.2 https://www.baidu.com
5 15110101014 2019-12-28 16:23:52.0 112.168.1.2 https://www.jd.com
6 15110101015 2019-12-28 16:23:56.0 112.168.12.4 https://www.qq.com
6 15110101015 2019-12-28 16:23:56.0 112.168.12.4 https://www.qq.com
7 15110101016 2019-12-28 16:28:24.0 112.168.12.45 https://www.qq.com
Time taken: 0.241 seconds, Fetched: 8 row(s)
```
可以看到`id=6`的資料,有2條,它的時間剛好是`--last-value`指定的時間,則會匯入**大於等於**`--last-value`指定時間的資料,這點需要