
圖解Janusgraph系列-圖資料底層序列化原始碼分析(Data Serialize)
阿新 • • 發佈:2020-12-17
# 圖解Janusgraph系列-圖資料底層序列化原始碼分析(Data Serialize)
大家好,我是`洋仔`,JanusGraph圖解系列文章,`實時更新`~
#### 圖資料庫文章總目錄:
* **整理所有圖相關文章,請移步(超鏈):**[圖資料庫系列-文章總目錄 ](https://liyangyang.blog.csdn.net/article/details/111031257)
* **地址:**[https://liyangyang.blog.csdn.net/article/details/111031257](https://liyangyang.blog.csdn.net/article/details/111031257)
> **`原始碼分析相關可檢視github(碼文不易,求個star~)`**: [https://github.com/YYDreamer/janusgraph](https://github.com/YYDreamer/janusgraph)
> 下述流程高清大圖地址:[https://www.processon.com/view/link/5f471b2e7d9c086b9903b629](https://www.processon.com/view/link/5f471b2e7d9c086b9903b629)
> 版本:JanusGraph-0.5.2
**轉載文章請保留以下宣告:**
>作者:洋仔聊程式設計
>微信公眾號:匠心Java
>原文地址:[https://liyangyang.blog.csdn.net/](https://liyangyang.blog.csdn.net/)
## 正文
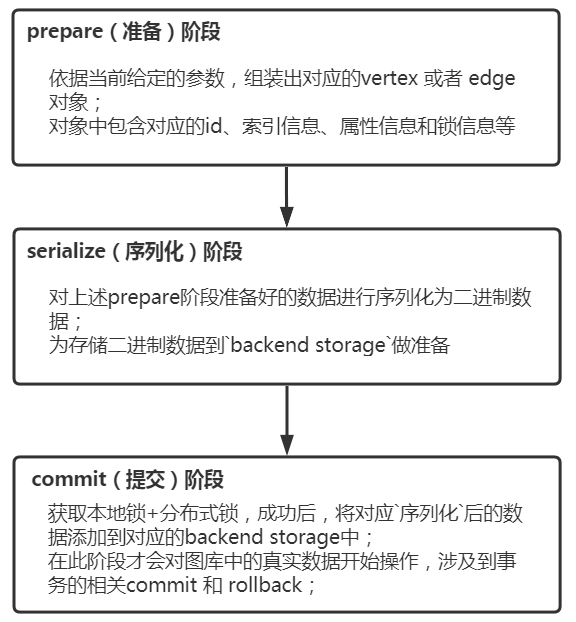
JanusGraph的資料匯入過程主要分為三階段:prepare(準備)、serialize(序列化)、commit(提交);不同階段有不同的作用,如下:
下面我們分別從匯入`vertex`節點和`edge`邊兩部分來分析寫流程
> 建議依據原始碼同步看本文章,便於理解!
## 一:vertex資料寫流程
下面`vertex`節點資料的匯入,
### prepare階段
主要是依據當前給定的引數,組裝出對應的vertex 或者 edge 物件;物件中包含對應的id、索引資訊、屬性資訊和鎖資訊等;
過程中包含以下幾種作用:
* 預設新增`vertex exist`屬性,值為true,標識當前節點是否存在
* 預設新增`label edge`邊,標識當前的節點 或者 邊是什麼label
* 生成`vertex`、`edge`、`property`的全域性分散式唯一id
* 自定義屬性驗證是否滿足唯一性約束
主要流程如下圖(建議依照原始碼一塊檢視,上述github地址已給出):

### serialize階段
主要是對上述`prepare`階段準備好的資料進行序列化為二進位制資料,為儲存二進位制資料到`backend storage`做準備; 另外獲取本地鎖 + 分散式鎖資料插入(此處只是將資料插入到Hbase,插入成功並不代表獲取成功)
過程中包含以下幾種作用:
* 序列化所有`relation`資料並存儲,包含屬性、label edge、normal edge
* 獲取屬性對應`index`需要更新的資料,並序列化儲存; 包含`組合索引和mixed index`的處理
* 獲取基於圖例項的本地鎖
* 獲取了本地鎖的前提前,獲取`edge lock` 和 `index lock`分散式鎖(此處的獲取鎖只是將對應的KLV儲存到Hbase中!儲存成功並不代表獲取鎖成功,在commit階段才會去檢查是不是獲取分散式鎖成功!)
主要流程如下圖:

### commit階段
主要是獲取`本地鎖`+`分散式鎖`成功後,將對應`序列化`後的資料新增到對應的`backend storage`中;完成圖資料插入過程! 在此階段才會對相簿中的真實資料開始影響,才會涉及到事務的回滾機制;
過程中包含以下幾種作用:
* 判斷分散式鎖的狀態,獲取成功則進行資料持久化;不成功則失敗
* 持久化`relation`資料
* 持久化`index`資料,包含組合索引儲存到第三方儲存;`mixed index`儲存到第三方索引庫中
* 刪除對應的本地鎖 和 分散式鎖的佔用
主要流程如下圖:

## 二:edge資料寫流程
針對於`edge`的寫資料流程,整體的流程和`vertex`節點的資料寫入相同,有幾點不同,下面一一列出:
**1、生成分散式唯一id的過程**
匯入Edge資料在生成edge的唯一id時,`partition id`的獲取不再是`隨機獲取`,而是嘗試獲取邊對應的`out vertex`的`partition id`; id的組成部分也不同,沒有`idPadding`部分;
具體解釋請看:《JanusGraph-分散式id生成策略》文章
**2、在`edge`的匯入中,沒有同`vertex`資料匯入,新增預設的`節點是否存在屬性`和`節點和節點對應label的邊`**
**3、獲取`edge`對應的屬性的index update時不同**
在匯入`vertex`資料時,將節點對應的屬性作為relation存放在addRelation中,然後收集所有的屬性relation迴圈獲取index uodate;如下虛擬碼:
```java
for (InternalRelation add : Iterables.filter(addedRelations,filter)) {
if (add.isProperty()) mutatedProperties.put(vertex,add); // 此處只操作屬性型別的
mutations.put(vertex.longId(), add);
}
// 此處,收集節點對應屬性對應的索引需要更新的資料、增加或刪除節點時才有作用; 針對於插入edge的操作,不涉及此處
for (InternalVertex v : mutatedProperties.keySet()) {
indexUpdates.addAll(indexSerializer.getIndexUpdates(v,mutatedProperties.get(v)));
}
```
而在`edge`資料匯入中,只將edge這條邊作為relation插入到addRelation中,所以無法獲取屬性relation,轉而通過收集過程中,對每個edge對應的所有屬性進行分別獲取;如下虛擬碼:
```java
for (InternalRelation add : Iterables.filter(addedRelations,filter)) {
if (add.isProperty()) mutatedProperties.put(vertex,add); // 此處只操作屬性型別的
mutations.put(vertex.longId(), add);
// 獲取邊包含的屬性;在節點插入時沒有作用,插入邊資料時,獲取邊上的屬性對應的索引; 只有edge操作中包含邊屬性,並且包含索引!
indexUpdates.addAll(indexSerializer.getIndexUpdates(add));
}
```
**4、`edge`對應的relation資料,也就是當前插入的這個邊,需要被序列化兩次**
一次是源節點+邊關係,一次是目標節點+邊關係(因為jansugraph是通過edge cut方式儲存圖資料的)
**5、`edge`的資料插入過程中,edge的序列化組成部分不同於vertex的序列化組成部分;**
不同點請看《Janusgraph-儲存結構》文章
**6、`edge`的資料插入中,edge的property和vertex的property組成不同!**
`edge`中針對於`sort key`和`signature key`配置的屬性,只將`property value`儲存在對應位置。其他未被配置的屬性值包含`proeprty key label id + property value`;
不同於vertex資料中的屬性組成包含:`proeprty key label id + property 唯一id +property value`
## 三:原始碼分析
原始碼分析已經push到github:https://github.com/YYDreamer/janusgraph
資料寫入的流程原始碼過多,就不在文章中給出分析了,具體請看github中原始碼分析註釋吧
## 四:應用
基於資料序列化匯入的原始碼博主將圖資料的序列化邏輯抽取出來,生成一個工具包;
主要用於圖資料的遷移和圖資料庫的初始化,適用於大資料量的匯入,主要流程如下:
1. 生成schema到圖中
2. 獲取schema資訊,快取到記憶體中
3. 呼叫api佔用對應的id blocker,用於離線資料的分散式唯一id生成
4. 呼叫抽取的序列化邏輯序列化節點和邊資料
5. 生成Hfile
6. 將hfile匯入到Hbase中
上述流程已經經過嚴格的驗證並在生產環境中使用,具體之後會再出一篇文章介紹一下詳細的設計與流程
## 五:總結
對於JanusGraph圖資料的寫入,主要分為3部分:
* schema的建立
* vertex節點資料的匯入
* edge邊資料的匯入
上述主要分析了`vertex`和`edge`的資料匯入,大致流程相似;也分析了兩部分匯入資料的差異;
其中涉及的`分散式唯一id`的生成邏輯 和 `鎖機制獲取`的邏輯,請看《圖解Janusgraph系列-Lock鎖機制(本地鎖+分散式鎖)分析》和《圖解Janusgraph系列-分散式id生成策略分析》兩篇文章!
針對於第三方索引的序列化儲存邏輯,邏輯相對簡單,此處沒有給出,具體讀者可以自主分析一下原始碼
> 碼字不易,求個贊