
歸一化和標準化-機器學習
阿新 • • 發佈:2020-10-21
# 歸一化與標準化
歸一化和標準化本質上都是一種線性變換。線性變換保持線性組合與線性關係式不變,這保證了特定模型不會失效。
## 歸一化 Normalization
歸一化一般是將資料對映到指定的範圍,用於去除不同維度資料的量綱以及量綱單位。
常見的對映範圍有 **[0, 1]** 和 **[-1, 1]** ,最常見的歸一化方法就是 **Min-Max 歸一化**:
![[公式]](https://www.zhihu.com/equation?tex=x_%7Bnew%7D%3D%5Cfrac%7Bx-x_%7Bmin%7D%7D%7Bx_%7Bmax%7D-x_%7Bmin%7D%7D)
舉個例子,判斷一個人的身體狀況是否健康,那麼我們會採集人體的很多指標,比如說:身高、體重、紅細胞數量、白細胞數量等。
一個人身高 180cm,體重 70kg,白細胞計數 ![[公式]](https://www.zhihu.com/equation?tex=7.50%C3%9710%5E%7B9%7D%2FL)
衡量兩個人的狀況時,白細胞計數就會起到主導作用從而**遮蓋住其他的特徵**,歸一化後就不會有這樣的問題。
## 標準化 Normalization
**英文翻譯的問題:**
> 歸一化和標準化的英文是一致的,但是根據其用途(或公式)的不同去理解(或翻譯)
最常見的標準化方法: **Z-Score 標準化**
標準化的輸出範圍不受限制,對異常值有更好的處理
![[公式]](https://www.zhihu.com/equation?tex=x_%7Bnew%7D%3D%5Cfrac%7Bx-%5Cmu+%7D%7B%5Csigma+%7D)
其中 ![[公式]](https://www.zhihu.com/equation?tex=%5Cmu) 是樣本資料的**均值(mean)**, ![[公式]](https://www.zhihu.com/equation?tex=%5Csigma) 是樣本資料的**標準差(std)**。
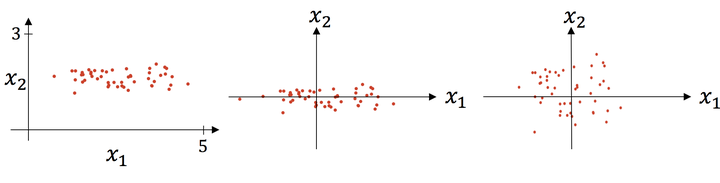
上圖則是一個散點序列的標準化過程:**原圖->減去均值->除以標準差**
## 歸一化和標準化的區別:
歸一化和標準化的本質都是縮放和平移,他們的區別直觀的說就是歸一化的縮放是 “拍扁” 統一到區間(0-1),而標準化的縮放是更加 “彈性” 和 “動態” 的,和整體樣本的分佈有很大的關係。
常見的歸一化方法:![[公式]](https://www.zhihu.com/equation?tex=x_%7Bnew%7D%3D%5Cfrac%7Bx-x_%7Bmin%7D%7D%7Bx_%7Bmax%7D-x_%7Bmin%7D%7D)
常見的標準化方法:![[公式]](https://www.zhihu.com/equation?tex=x_%7Bnew%7D%3D%5Cfrac%7Bx-%5Cmu+%7D%7B%5Csigma+%7D)
從輸出範圍角度來看, 歸一化的輸出結果必須在 0-1 間。而標準化的輸出範圍不受限制,通常情況下比歸一化更廣
## 標準化與歸一化的應用場景:
- 一般情況下,如果對輸出結果範圍有要求,用歸一化
- 如果資料較為穩定,不存在極端的最大最小值,用歸一化
- 如果資料存在異常值和較多噪音,用標準化,可以間接通過中心化**避免異常值和極端值**的影響
- 在機器學習中,**標準化是更常用**的手段,歸一化的應用場景是有限的,原因就在於二者的區別:
- 標準化更好保持了樣本間距。當樣本中有異常點時,歸一化有可能將正常的樣本“擠”到一起去,對異常值和極端值處理的並不好
- 標準化更符合統計學假。對一個數值特徵來說,很大可能它是服從正態分佈的。標準化其實是基於這個隱含假設,只不過是將這個正態分佈調整為均值為0,方差為1的標準正態分