
MySQL索引及優化(1)儲存引擎和底層資料結構
在昨天的面試中問到了MySQL索引怎麼優化(查詢很慢怎麼辦),回答的很不理想,所以今天來總結幾篇關於MySQL索引的知識。
1.什麼是索引?
首先我們一定要明確什麼是索引?我自己的總結就是索引是一種資料結構,可以幫助我們快速訪問資料庫的指定資訊,就像一本書的目錄一樣,可以加快查詢速度
2.MySQl儲存引擎
MySQL中最常見的儲存引擎有InnoDB和MyISAM,它們的主要區別如下:
- MyISAM不支援事務;InnoDB是事務型別的儲存引擎。
- MyISAM只支援表級鎖;InnoDB支援行級鎖和表級鎖,預設為行級鎖。
- MyISAM引擎不支援外來鍵;InnoDB支援外來鍵。
- 對於count(*)查詢來說MyISAM更有優勢,因為其儲存了行數。
- InnoDB是為處理巨大資料量時的最大效能設計的儲存引擎。
- MyISAM支援全文索引(FULLTEXT);InnoDB不支援。
總結:
最主要的區別就是MyISAM表不支援事務、不支援行級鎖、不支援外來鍵。 InnoDB表支援事務、支援行級鎖、支援外來鍵。
在MySQL5.5.5版本之後,InnoDB已經成為了其預設的儲存引擎,也是大部分公司的不二選擇,畢竟誰家公司會不要求資料庫支援事務呢?誰家公司又可以忍受表級鎖導致的讀寫衝突呢?
除了InnoDB以及MyISAM儲存引擎外,常見的考察儲存引擎還有Memory,使用Memory作為儲存引擎的表也可以叫做記憶體表,將資料儲存在了記憶體中,所以適合做臨時表來使用,在索引結構上支援B+樹索引和Hash索引。
3.為什麼選擇B+樹索引
這裡推薦一個外國的學習資料結構的一個網站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html(非常的nice)
首先列舉幾個可以做索引的資料結構:
- 二叉查詢樹
- 紅黑樹
- B樹
- B+樹
1.平衡二叉查詢樹(AVL樹)
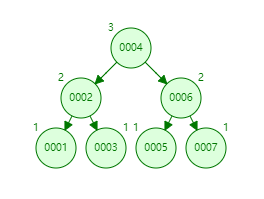
看一下最基本的結構,這裡我也是插入了7個數據
說一下特徵:
- 非葉子結點最多有兩個子結點
- 非葉子結點大於左邊子結點,小於右邊子結點
- 沒有值相等重複的點
- 每個節點的左子樹和右子樹的高度差至多為1
它的快體現在哪裡呢?
比如說我們查詢3:3是小於根節點4的,從它的左子樹找,3是大於2的,所以在2的右子樹,這樣就查詢到3的位置了,查詢速度為O(LogN)
缺點:維護平衡二叉樹的代價太大每次都需要左旋或者右旋來維持平衡
2.紅黑樹
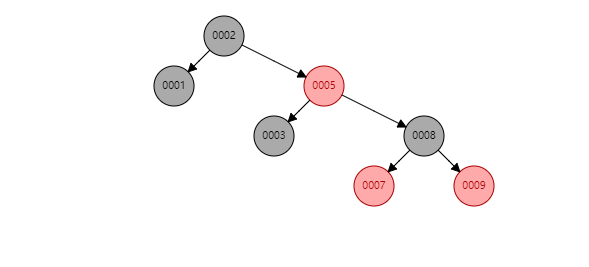
插入10後
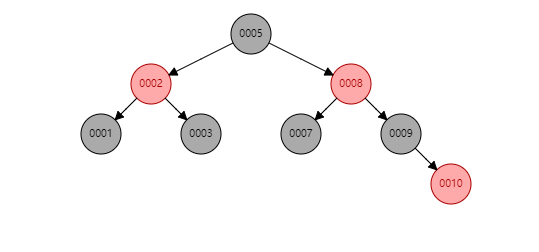
特徵:
- 每個節點或者是黑色,或者是紅色。
- 根節點是黑色。
- 每個葉子節點(NIL)是黑色。 [注意:這裡葉子節點,是指為空(NIL或NULL)的葉子節點!]
- 如果一個節點是紅色的,則它的子節點必須是黑色的。
- 從一個節點到該節點的子孫節點的所有路徑上包含相同數目的黑節點。[這裡指到葉子節點的路徑]
到這裡我們要說到一些東西
磁碟IO
計算機硬體效能在過去十年間的發展普遍遵循摩爾定律,通用計算機的CPU主頻早已超過3GHz,記憶體也進入了普及DDR4的時代。然而傳統硬碟雖然在儲存容量上增長迅速,但是在讀寫效能上並無明顯提
升,同時SSD硬碟價格高昂,不能在短時間內完全替代傳統硬碟。傳統磁碟的I/O讀寫速度成為了計算機系統性能提高的瓶頸,制約了計算機整體效能的發展。
其實簡單來說就是我們要減少磁碟IO的次數,樹的深度越大,磁碟IO的次數就越多,所以無論是從它的平衡代價或者磁碟IO次數來講紅黑樹和AVL樹都太適合。
區域性性原理與磁碟預讀:
由於儲存介質的特性,磁碟本身存取就比主存慢很多,再加上機械運動耗費,磁碟的存取速度往往是主存的幾百分分之一,因此為了提高效率,要儘量減少磁碟I/O。為了達到這個目的,磁碟往往不是嚴格按需讀取,而是每次都會預讀,即使只需要一個位元組,磁碟也會從這個位置開始,順序向後讀取一定長度的資料放入記憶體。這樣做的理論依據是電腦科學中著名的區域性性原理:
當一個數據被用到時,其附近的資料也通常會馬上被使用。
程式執行期間所需要的資料通常比較集中。
由於磁碟順序讀取的效率很高(不需要尋道時間,只需很少的旋轉時間),因此對於具有區域性性的程式來說,預讀可以提高I/O效率。
紅黑樹這種結構,h明顯要深的多。由於邏輯上很近的節點(父子)物理上可能很遠,無法利用區域性性,所以紅黑樹的I/O漸進複雜度也為O(h),效率明顯不太盡人意。
3.B樹

一個M階的b樹具有如下幾個特徵:
- 定義任意非葉子結點最多隻有M個兒子,且M>2;
- 根結點的兒子數為[2, M];
- 除根結點以外的非葉子結點的兒子數為[M/2, M],向上取整;
- 非葉子結點的關鍵字個數=兒子數-1;
- 所有葉子結點位於同一層;
- k個關鍵字把節點拆成k+1段,分別指向k+1個兒子,同時滿足查詢樹的大小關係。
特性
- 關鍵字集合分佈在整顆樹中;
- 任何一個關鍵字出現且只出現在一個結點中;
- 搜尋有可能在非葉子結點結束;
- 其搜尋效能等價於在關鍵字全集內做一次二分查詢;
4.B+樹
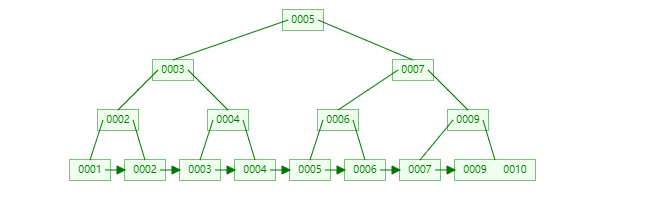
M階的b+樹的特徵:
- 有n棵子樹的非葉子結點中含有n個關鍵字(b樹是n-1個),這些關鍵字不儲存資料,只用來索引,所有資料都儲存在葉子節點(b樹是每個關鍵字都儲存資料)。
- 所有的葉子結點中包含了全部關鍵字的資訊,及指向含這些關鍵字記錄的指標,且葉子結點本身依關鍵字的大小自小而大順序連結。
- 所有的非葉子結點可以看成是索引部分,結點中僅含其子樹中的最大(或最小)關鍵字。
- 通常在b+樹上有兩個頭指標,一個指向根結點,一個指向關鍵字最小的葉子結點。
- 同一個數字會在不同節點中重複出現,根節點的最大元素就是b+樹的最大元素。
B+樹相對於B樹的優勢
- b+樹的中間節點不儲存資料,所以磁碟頁能容納更多節點元素,更“矮胖”;
- b+樹查詢必須查詢到葉子節點,b樹只要匹配到即可不用管元素位置,因此b+樹查詢更穩定(並不慢);
- 對於範圍查詢來說,b+樹只需遍歷葉子節點連結串列即可,b樹卻需要重複地中序遍歷,如下兩圖:
4.總結
資料庫引擎:InnoDB和MyISAM
主要區分:事務,外來鍵,行級鎖(以上InnoDB都支援,MyISAM只支援表級鎖)
為什麼選擇B+樹:
- AVL樹和紅黑樹深度深,磁碟IO次數多,父子節點物理上遠,不滿足區域性性原理
- B+樹,非葉子節點不儲存資料,葉子結點之間有指標可以進行範圍查詢,並且B+樹裡的元素也是有序的。
附加問題:
B+樹中一個節點到底多大合適?
B+樹中一個節點為一頁(16KB)或頁的倍數最為合適。
因為如果一個節點的大小小於1頁,那麼讀取這個節點的時候其實也會讀出1頁,造成資源的浪費。
如果一個節點的大小大於1頁,比如1.2頁,那麼讀取這個節點的時候會讀出2頁,也會造成資源的浪費。
所以為了不造成浪費,所以最後把一個節點的大小控制在1頁、2頁、3頁、4頁等倍數頁大小最為合適。
&n