
使用pandas篩選出指定列值所對應的行
在pandas中怎麼樣實現類似mysql查詢語句的功能:
select * from table where column_name = some_value;pandas中獲取資料的有以下幾種方法:
- 布林索引
- 位置索引
- 標籤索引
- 使用API
假設資料如下:
import pandas as pd import numpy as np df = pd.DataFrame({'A': 'foo bar foo bar foo bar foo foo'.split(), 'B': 'one one two three two two one three'.split(), 'C': np.arange(8), 'D': np.arange(8) * 2})

布林索引
該方法其實就是找出每一行中符合條件的真值(true value),如找出列A中所有值等於foo
df[df['A'] == 'foo'] # 判斷等式是否成立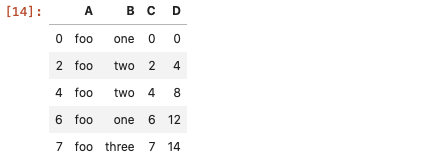
位置索引
使用iloc方法,根據索引的位置來查詢資料的。這個例子需要先找出符合條件的行所在位置
mask = df['A'] == 'foo'
pos = np.flatnonzero(mask) # 返回的是array([0, 2, 4, 6, 7])
df.iloc[pos]
#常見的iloc用法
df.iloc[:3,1:3]
標籤索引
如何DataFrame的行列都是有標籤的,那麼使用loc方法就非常合適了。
df.set_index('A', append=True, drop=False).xs('foo', level=1) # xs方法適用於多重索引DataFrame的資料篩選
# 更直觀點的做法
df.index=df['A'] # 將A列作為DataFrame的行索引
df.loc['foo', :]
# 使用布林
df.loc[df['A']=='foo']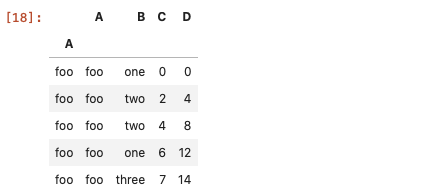
使用API
pd.DataFrame.query方法在資料量大的時候,效率比常規的方法更高效。
df.query('A=="foo"')
# 多條件
df.query('A=="foo" | A=="bar"')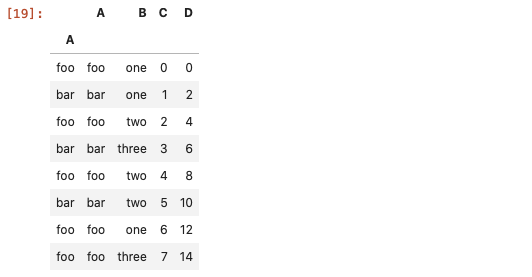
資料提取不止前面提到的情況,第一個答案就給出了以下幾種常見情況:
1、篩選出列值等於標量的行,用==
df.loc[df['column_name'] == some_value]2、篩選出列值屬於某個範圍內的行,用isin
df.loc[df['column_name'].isin(some_values)] # some_values是可迭代物件3、多種條件限制時使用&,&的優先順序高於>=或<=,所以要注意括號的使用
df.loc[(df['column_name'] >= A) & (df['column_name'] <= B)]4、篩選出列值不等於某個/些值的行
df.loc[df['column_name'] != 'some_value']
df.loc[~df['column_name'].isin('some_values')] #~取反如果你覺得我的文章還可以,可以關注我的微信公眾號,檢視更多實戰文章:Python爬蟲實戰之路
也可以掃描下面二維碼,新增我的微信公眾號

相關推薦
使用pandas篩選出指定列值所對應的行
在pandas中怎麼樣實現類似mysql查詢語句的功能: select * from table where column_name = some_value; pandas中獲取資料的有以下幾種方法: 布林索引 位置索引 標籤索引 使用API 假設資料如下: import pandas as pd im
Panda篩選出某列值相同的行
比如DataFrame有兩列,[luid,message] 現在我想挑選出相同人傳送的資訊 那麼程式碼如下: # 篩選出luid相同的行 subData = trainData.loc[(trainD
pandas Dataframe按指定列值排序問題
想檢視按某列值排序後的情況,借鑑網上的解決辦法: df.sort_values(by="sales" , ascending=False) by 指定列 ascending 想顯示結果的話,可以設定另一個變數 b=df.sort_values(by="sales" , a
mysql查詢篩選出多列值同時重複的資料
例如表test: id name age 1 a 10 2 a 10 3 b 10 篩選出name和age不重複的資料 SELECT a.id,a.name,a.age FROM (SELECT t
js實現獲取兩個日期之間篩選出指定周日制的方法
js var start = "2017-5-25"; var end = "2017-6-5"; var startTime = new Date(start); var endTime = new Date(end) var timeArr = []; var weekDay = ["1","2
pandas篩選出表中滿足另一個表所有條件的資料
今天記錄一下pandas篩選出一個表中滿足另一個表中所有條件的資料。例如: list1 結構: 名字,ID,顏色,數量,型別。list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b
獲取DataGrid行指定列值
1.獲取選中行 2.選中行轉換為DataRowView 3.獲取指定列 示例程式碼 //dg為DataGrid控制元件名稱 if (null != dg.SelectedItem) { DataRowView drv = dg.SelectedItem as DataRow
[Python]numpy:獲取索引值所對應的數字值(索引值、下標轉化為數字)
舉個例子: q=[0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15] 我想獲取其中值等於7的那個值的下標,以便於用於其他計算。 如果使用np.where,如: q=np.arange(0,16,1) g=np.where(q==7) print
Python中獲取字典中value的最大值所對應的鍵的方法
可以用max(dict,key=dict.get)方法獲得字典dict中value的最大值所對應的鍵的方法,max(dict, key)方法首先遍歷迭代器,並將返回值作為引數傳遞給key對應的函式,然後將函式的執行結果傳給key,並以此時key值為標準進行大小判斷,返回最大值
把資料庫表中某幾列值相同的行去重,只保留一行
使用分析函式row_number() over (partition by … order by …)來進行分組編號,然後取分組標號值為1的記錄即可。目前主流的資料庫都有支援分析函式,很好用。 其中,partition by 是指定按哪些欄位進行分組,這些欄
pandas 知道幾個index的值,求這些index所對應的資料
''' Unnamed: 0 duration user_id subject_1 0 907296360955 957658 5548154389 1
pandas 篩選指定行或者列的資料
pandas主要的兩個資料結構是:series(相當於一行或一列資料結構和DataFrame(相當於多行多列的一個表格資料機構)。 原文:https://www.cnblogs.com/gangandimami/p/8983323.html 1.重新索引:reindex和ix
pandas 篩選指定行或者列的數據
指定 情況 選擇 修改索引 部分 table ron index 兩個 pandas主要的兩個數據結構是:series(相當於一行或一列數據結構和DataFrame(相當於多行多列的一個表格數據機構)。 原文:https://www.cnblogs.com/ganga
jquery datagrid根據指定列的值改變所在行的背景顏色
$('#gridlist').datagrid({ rowStyler:function(index,row){ if (row.ORDERSID==1){ return 'background-color:gray;'
python利用pandas找出矩陣的最大值或最小值及其對應的位置
import pandas as pd text = pd.DataFrame([[21,45,78],[23,56,89],[14,25,36],[47,58,69]]) # 先建立一個矩陣 print(text) Out[1]: 0 1 2 0 21 45 78 1
【Bootstrap Table】在指定列中新增下拉框控制元件,並獲取所選值
背景 最近在使用Bootstrap table ,有一個在某一列新增一個下拉列表,並且通過 “getAllSelections”方法獲取所選行的需求,在實現這個功能的時,走了一些彎路,遇到了一些坑。所以今天總結出來,既是自己的學習,也分享給大家,
遍歷一個對象中所有屬性所對應的值
對象 屬性 值和遍歷 數組中的每一個元素的方法很類似註意:在遍歷數組時 其中的i對應著數組的下標。遍歷一個對象中所有屬性所對應的值
pandas布林表示式篩選表的列資料,注意多個條件需加括號
result[(result.CREATE_TIME > pd.to_datetime('2018-07')) & (result.CREATE_TIME < pd.to_datetime('2018-08'))] 如果要使用與(and),用符號&表示,如df.A&n
pandas DataFrame高效程式設計方法: 根據多列的值做判斷,生成新的列值,其中多列的值是包含多個值的資料型別
一.遇到的問題描述: 我遇到問題的資料比較複雜,下面以比較簡單的資料為例說明問題,所以這些資料的含義是沒有意義的,可以忽略資料的的具體意義。資料如下所示: import numpy as np import pandas as pd data = {'city': [{'Beijing':1
實現功能:點選選項之後,篩選出對應的產品
實現功能:點選選項之後,篩選出對應的產品 1.注意替換後臺提供的url 2.beforeSend: function(){ $("#xunhuan2").html(""); }, 實現在傳送前,清空內容 3.html