
【大白話系統】MySQL 學習總結 之 緩衝池(Buffer Pool) 的設計原理和管理機制
一、緩衝池(Buffer Pool)的地位
在《MySQL 學習總結 之 InnoDB 儲存引擎的架構設計》中,我們就講到,緩衝池是 InnoDB 儲存引擎中最重要的元件。因為為了提高 MySQL 的併發效能,使用到的資料都會快取在緩衝池中,然後所有的增刪改查操作都將在緩衝池中執行。
通過這種方式,保證每個更新請求,儘量就是隻更新記憶體,然後往磁碟順序寫日誌檔案。
更新記憶體的效能是極高的,然後順序寫磁碟上的日誌檔案的效能也是比較高的,因為順序寫磁碟檔案,他的效能要遠高於隨機讀寫磁碟檔案。
正因為緩衝池的重要性,所以我們必須比較深入地去理解和研究其中的原理和機制。當然了,我這裡還是比較大白話的介紹緩衝池這個元件的原理,比較適合大家比較整體和從巨集觀上去了解,如果需要更加深入的,建議大家去看 MySQL 的官方文件,或者是相關技術書籍。
二、 Buffer Pool 的大小
緩衝池(Buffer Pool)的預設大小為 128M,可通過 innodb_buffer_pool_size 引數來配置。
三、Buffer Pool 的結構
當 SQL 執行時,用到的相關表的資料行,會將這些資料行都快取到 Buffer Pool 中。
但是我們可以想象一下,如果像上面的機制那麼簡單,那麼如果是分頁的話,不斷地查詢就要不斷地將磁碟檔案中資料頁的資料快取到 Buffer Pool 中了,那麼這時候快取池這個機制就顯得沒什麼用了,每次查詢還是會有一次或者多次的磁碟IO。
但是怎麼快取呢?
1、資料頁概念
我們先了解一下資料頁這個概念。它是 MySQL 抽象出來的資料單位,磁碟檔案中就是存放了很多資料頁,每個資料頁裡存放了很多行資料。
預設情況下,資料頁的大小是 16kb。
所以對應的,在 Buffer Pool 中,也是以資料頁為資料單位,存放著很多資料。但是我們通常叫做快取頁,因為 Buffer Pool 畢竟是一個緩衝池,並且裡面的資料都是從磁碟檔案中快取到記憶體中。
所以,預設情況下快取頁的大小也是 16kb,因為它和磁碟檔案中資料頁是一一對應的。
所以,緩衝池和磁碟之間的資料交換的單位是資料頁,包括從磁碟中讀取資料到緩衝池和緩衝池中資料刷回磁碟中,如圖所示:
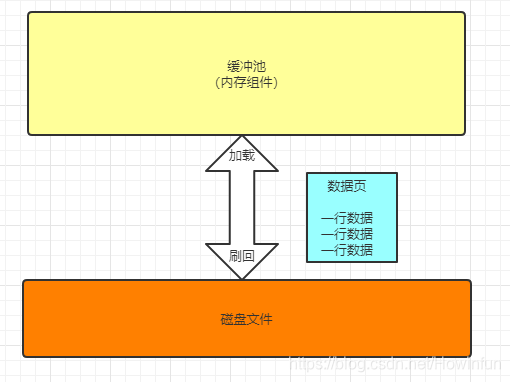
2、怎麼識別資料在哪個快取頁中?
到此,我們都知道 Buffer Pool 中是用快取頁來快取資料的,但是我們怎麼知道快取頁對應著哪個表,對應著哪個資料頁呢?
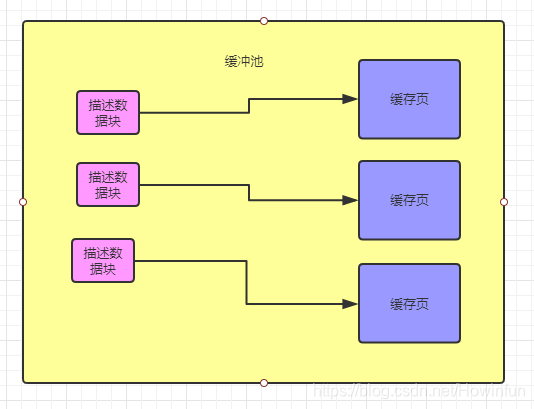
所以每個快取頁都會對應著一個描述資料塊,裡面包含資料頁所屬的表空間、資料頁的編號,快取頁在 Buffer Pool 中的地址等等。
描述資料塊本身也是一塊資料,它的大小大概是快取頁大小的5%左右,大概800個位元組左右的大小。
描述如圖所示:
四、Buffer Pool 的初始化
到此,我們都知道了,Buffer Pool 是快取資料的資料單位為快取頁,利用描述資料塊來標識快取頁。
那麼,MySQL 啟動時,是如何初始化 Buffer Pool 的呢?
1、MySQL 啟動時,會根據引數 innodb_buffer_pool_size 的值來為 Buffer Pool 分配記憶體區域。
2、然後會按照快取頁的預設大小 16k 以及對應的描述資料塊的 800個位元組 左右大小,在 Buffer Pool 中劃分中一個個的快取頁和一個個的描述資料庫塊。
3、注意,此時的快取頁和描述資料塊都是空的,畢竟才剛啟動 MySQL 呢。
五、Free 連結串列記錄空閒快取頁
上面我們瞭解了 Buffer Pool 在 MySQL 啟動時是如何初始化的。當 MySQL 啟動後,會不斷地有 SQL 請求進來,此時空先的快取頁就會不斷地被使用。
那麼, Buffer Pool 怎麼知道哪些快取頁是空閒的呢?
1、Free 連結串列的使用原理
free 連結串列,它是一個雙向連結串列,連結串列的每個節點就是一個個空閒的快取頁對應的描述資料塊。
他本身其實就是由 Buffer Pool 裡的描述資料塊組成的,你可以認為是每個描述資料塊裡都有兩個指標,一個是 free_pre 指標,一個是 free_next 指標,分別指向自己的上一個 free 連結串列的節點,以及下一個 free 連結串列的節點。
通過 Buffer Pool 中的描述資料塊的 free_pre 和 free_next 兩個指標,就可以把所有的描述資料塊串成一個 free 連結串列。
下面我們可以用虛擬碼來描述一下 free 連結串列中描述資料塊節點的資料結構:
DescriptionDataBlock{
block_id = block1;
free_pre = null;
free_next = block2;
}free 連結串列有一個基礎節點,他會引用連結串列的頭節點和尾節點,裡面還儲存了連結串列中有多少個描述資料塊的節點,也就是有多少個空閒的快取頁。
下面我們也用虛擬碼來描述一下基礎節點的資料結構:
FreeListBaseNode{
start = block01;
end = block03;
count = 2;
}到此,free 連結串列就介紹完了。上面我們也介紹了 MySQL 啟動時 Buffer Pool 的初始流程,接下來,我會將結合剛介紹完的 free 連結串列,講解一下 SQL 進來時,磁碟資料頁讀取到 Buffer Pool 的快取頁的過程。但是,我們先要了解一下一個新概念:資料頁快取雜湊表,它的 key 是表空間+資料頁號,而 value 是對應快取頁的地址。
描述如圖所示:
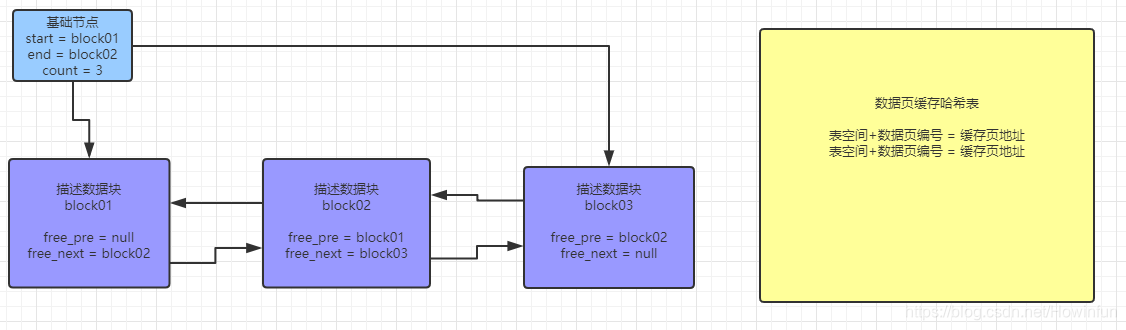
2、磁碟資料頁讀取到 Buffer Pool 的快取頁的過程
1、首先,SQL 進來時,判斷資料對應的資料頁能否在 資料頁快取雜湊表裡 找到對應的快取頁。
2、如果找到,將直接在 Buffer Pool 中進行增刪改查。
3、如果找不到,則從 free 連結串列中找到一個空閒的快取頁,然後從磁碟檔案中讀取對應的資料頁的資料到快取頁中,並且將資料頁的資訊和快取頁的地址寫入到對應的描述資料塊中,然後修改相關的描述資料塊的 free_pre 指標和 free_next 指標,將使用了的描述資料塊從 free 連結串列中移除。記得,還要在資料頁快取雜湊表中寫入對應的 key-value 對。最後也是在 Buffer Pool 中進行增刪改查。
六、Flush 連結串列記錄髒快取頁
1、髒頁和髒資料
我們都知道 SQL 的增刪改查都在 Buffer Pool 中執行,慢慢地,Buffer Pool 中的快取頁因為不斷被修改而導致和磁碟檔案中的資料不一致了,也就是 Buffer Pool 中會有很多個髒頁,髒頁裡面很多髒資料。
所以,MySQL 會有一條後臺執行緒,定時地將 Buffer Pool 中的髒頁刷回到磁碟檔案中。
但是,後臺執行緒怎麼知道哪些快取頁是髒頁呢,不可能將全部的快取頁都往磁碟中刷吧,這會導致 MySQL 暫停一段時間。
2、MySQL 是怎麼判斷髒頁的
我們引入一個和 free 連結串列類似的 flush 連結串列。他的本質也是通過快取頁的描述資料塊中的兩個指標,讓修改過的快取頁的描述資料塊能串成一個雙向連結串列,這兩指標大家可以認為是 flush_pre 指標和 flush_next 指標。
下面我用虛擬碼來描述一下:
DescriptionDataBlock{
block_id = block1;
// free 連結串列的
free_pre = null;
free_next = null;
// flush 連結串列的
flush_pre = null;
flush_next = block2;
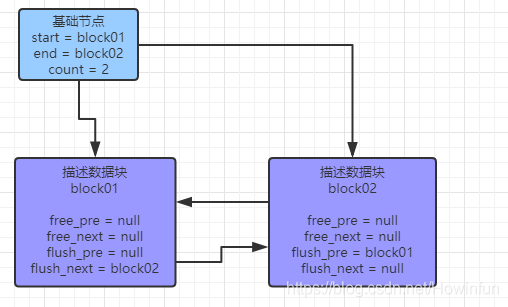
}flush 連結串列也有對應的基礎節點,也是包含連結串列的頭節點和尾節點,還有就是修改過的快取頁的數量。
FlushListBaseNode{
start = block1;
end = block2;
count = 2;
}到這裡,我們都知道,SQL 的增刪改都會使得快取頁變為髒頁,此時會修改髒頁對應的描述資料塊的 flush_pre 指標和 flush_next 指標,使得描述資料塊加入到 flush 連結串列中,之後 MySQL 的後臺執行緒就可以將這個髒頁刷回到磁碟中。
描述如圖所示:
七、LRU 連結串列記錄快取頁的命中率
1、快取命中率
我們都知道,當載入磁碟中的資料頁到快取中時,會從 free 連結串列找到空閒的快取頁,然後將資料載入到快取頁裡。
但是快取頁總會有用完的時候,此時需要淘汰一下快取頁,將它刷入磁碟中,然後清空。
那麼會選擇誰淘汰呢?
那麼必定會淘汰快取命中率低的快取頁。
什麼叫快取命中率低:假如你有100次請求,有30次請求都是查詢和修改快取頁一,直接操作快取而不需要從磁碟載入,這就是快取命中率高。而快取頁二自載入到 Buffer Pool 後,只被查詢和修改過一次,之後的100次請求中甚至沒有一次是查詢和修改它的,這就是快取命中率低了,因為大部分請求都是操作其他快取頁,甚至要從磁碟中載入。
2、lru 連結串列的使用原理
InnoDB 儲存引擎是利用 lru 連結串列完成上面的快取命中率的。lru 就是 Least Recently Used,最近最少使用的意思。
ps:lru 連結串列也是類似於 free 連結串列和 flush 連結串列的資料結構。
當有磁碟資料頁載入資料到快取頁時,會將快取頁對應的描述資料塊放入 lru 連結串列的頭部;後續只要查詢或者修改了快取頁的資料,也會將對應描述資料塊移到 lru 連結串列的頭部去。
此時,lru 連結串列尾部的描述資料塊對應的快取頁,必定是命中率最低的,也就是使用最少的快取頁,所以優先被淘汰的肯定是它。
3、lru 連結串列存在的問題
lru 連結串列的使用當然不會像上面的那麼簡單。
因為 MySQL 為了提高效能,提供了一個機制:預讀機制。
當你從磁碟上載入一個數據頁的時候,他可能會連帶著把這個資料頁相鄰的其他資料頁,也載入到快取裡去。這個機制會帶來這麼一個問題:連帶的資料頁可能在後面的查詢或者修改中,並不會用到,但是它們卻在 lru 連結串列的頭部。
什麼意思?
那就是,本來經常被用到的快取頁被壓到 lru 連結串列的尾部去了,如果此時需要淘汰快取頁,命中率高的快取頁反而被淘汰掉了!
當然了,全表掃描也會帶來同樣的問題。
全表掃描會將表裡所有的資料一次性載入到 Buffer Pool 來,但是卻有很多資料在之後都不會用到。
4、冷熱資料分離
什麼是冷熱分離?
簡單點,就是將命中率高的資料和命中率低的資料分開,分成兩塊區域。
InnoDB 儲存引擎就是利用冷熱資料分離方案來解決上面的問題:將 lru 連結串列分為兩部分,一部分是熱資料區域連結串列,一部分是冷資料區域連結串列。
lru 連結串列的頭節點指向熱資料區域的連結串列頭節點,lru 連結串列的尾節點指向冷資料區域的連結串列尾節點。
描述如圖所示:
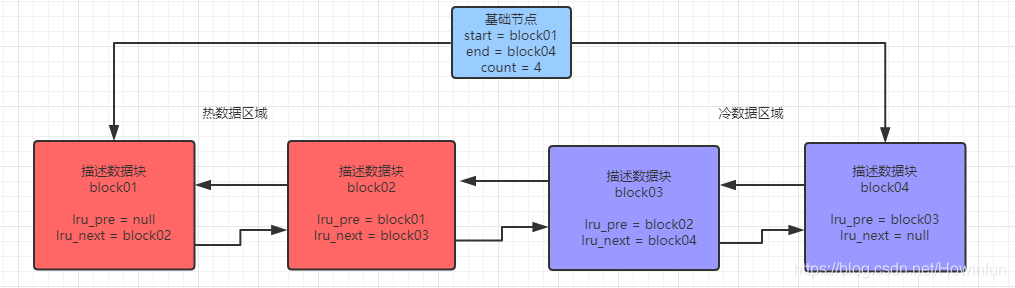
冷熱分離的比例
由引數 innodb_old_blocks 控制,預設值為37,表示冷資料佔所有資料的37%。
冷熱分離的原理
磁碟中的資料頁第一次載入到快取頁時,對應的描述資料塊放到冷資料區域的連結串列頭部,然後在 1s 後,如果再次訪問這個快取頁,才會將快取頁對應的描述資料塊移動到熱資料區域的連結串列頭部去。
這個 1s 由引數 innodb_old_blocks_time 指定,預設值是 1000 毫秒。
熱資料區的優化
冷資料區的快取頁是在 1s 後再被訪問到就移動到熱資料區的連結串列頭部。那麼熱資料區域的規則呢,是不是隻要被訪問就會移動到熱資料區域的連結串列頭部。
當然不是了。大家可以想一下,能留在熱資料區域的快取頁,證明都是快取命中率比較高的,會經常被訪問到。如果每個快取頁被訪問都移動到連結串列頭部,那這個操作將會非常的頻繁。
所以 InnoDB 儲存引擎做了一個優化,只有在熱資料區域的後 3/4 的快取頁被訪問了,才會移動到連結串列頭部;如果是熱資料區域的前 1/4 的快取頁被訪問到,它是不會被移動到連結串列頭部去的。
lru 連結串列尾部的快取頁何時刷入磁碟
當 free 連結串列為空了,此時需要將資料頁載入到緩衝池裡,就會 lru 連結串列的冷資料區域尾部的快取頁刷入磁碟,然後清空,再載入資料頁的資料。
一條後臺執行緒,執行一個定時任務,定時將 lru 連結串列的冷資料區域的尾部的一些快取頁刷入磁碟,然後清空,最後把他們對應的描述資料塊加入到 free 連結串列中去。
當然了,除了 lru 連結串列尾部的快取頁會被刷入磁碟,還有的就是 flush 連結串列的快取頁。
後臺執行緒同時也會在 MySQL 不繁忙的時候,將 flush 連結串列中的快取頁刷入磁碟中,這些快取頁的描述資料塊會從 lru 連結串列和 flush 連結串列中移除,並加入到 free 連結串列中。
八、總結
到此,我已經將緩衝池 Buffer Pool介紹完畢了。
下面簡單總結一下 Buffer Pool 從初始化到使用的整個流程。
1、MySQL 啟動時會根據分配指定大小記憶體給 Buffer Pool,並且會建立一個個描述資料塊和快取頁。
2、SQL 進來時,首先會根據資料的表空間和資料頁編號查詢 資料頁快取雜湊表 中是否有對應的快取頁。
3、如果有對應的快取頁,則直接在 Buffer Pool中執行。
4、如果沒有,則檢查 free 連結串列看看有沒有空閒的快取頁。
5、如果有空閒的快取頁,則從磁碟中載入對應的資料頁,然後將描述資料塊從 free 連結串列中移除,並且加入到 lru 連結串列的冷資料區域的連結串列頭部。後面如果被修改了,還需要加入到 flush 連結串列中。
6、如果沒有空閒的快取頁,則將 lru 連結串列的冷資料區域的連結串列尾部的快取頁刷回磁碟,然後清空,接著將資料頁的資料載入到快取頁中,並且描述資料塊會加入到 lru 連結串列的冷資料區域的連結串列頭部。後面如果被修改了,還需要加入到 flush 連結串列中。
7、5或者6後,就接著在 Buffer Pool 中執行增刪改查。
注意:5和6中,快取頁加入到冷資料區域的連結串列頭部後,如果在 1s 後被訪問,則將入到熱資料區域的連結串列頭部。
8、最後,就是描述資料塊隨著 SQL 語句的執行不斷地在 free 連結串列、flush 連結串列和 lru 連結串列中移動了