
tensorflow學習筆記——AlexNet
1,AlexNet網路的創新點
AlexNet將LeNet的思想發揚光大,把CNN的基本原理應用到了很深很寬的網路中。AlexNet主要使用到的新技術點如下:
(1)成功使用ReLU作為CNN的啟用函式,並驗證其效果在較深的網路超過了Sigmoid,成功解決了Sigmoid在網路較深時的梯度彌散問題。雖然ReLU啟用函式在很久之前就被提出了,但直到AlexNet的出現才將其發揚光大。
在最初的感知機模型中,輸入和輸出的關係如下:
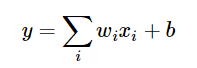
雖然只是單純的線性關係,這樣的網路結構有很大的侷限性:即使用很多這樣結構的網路層疊加,其輸出和輸入仍然是線性關係,無法處理有非線性關係的輸入輸出。因此,對每個神經元的輸出做個非線性的轉換也就是,將上面的加權求和的結果輸入到一個非線性函式,也就是啟用函式中。這樣,由於啟用函式的引入,多個網路層的疊加就不再是單純的線性變換,而是具有更強的表現能力。
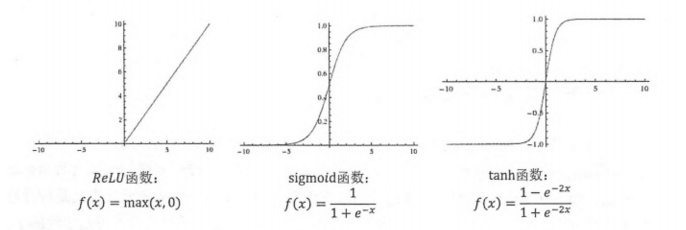
在網路層較少時,Sigmoid函式的特效能夠很好的滿足啟用函式的作用:它把一個實數壓縮至0到1之間,當輸入的數字非常大的時候,結果會接近1,;當輸入非常大的負數時,則會得到接近0的結果。這種特性,能夠很好的模擬神經元在受刺激後,是否被啟用向後傳遞資訊(輸出為0,幾乎不被啟用;輸出為1,完全被啟用)。Sigmoid函式一個很大的問題就是梯度飽和。觀察Sigmoid函式的曲線,當輸入的數字較大(或較小)時,其函式值趨於不變,其導數變得非常的小。這樣在層數很多的網路結構中,進行反向傳播時,由於很多個很小的Sigmoid導數累成,導致其結果趨於0,權值更新較慢。
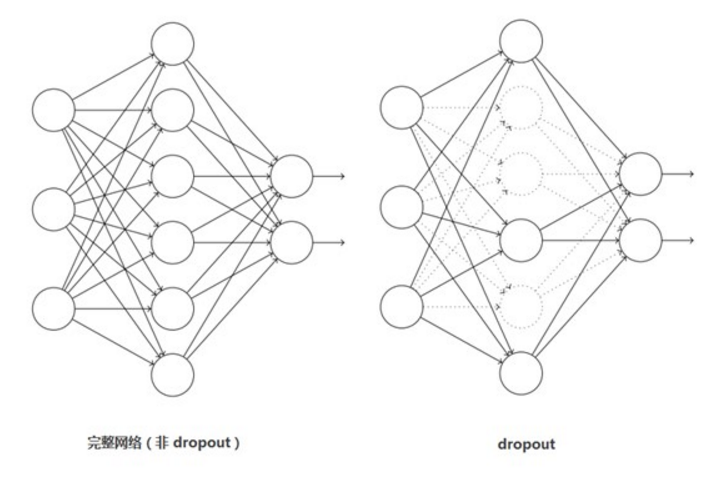
(2)訓練時使用Dropout隨機忽略一部分神經元,以避免模型過擬合。Dropout雖有單獨的論文論述,但是AlexNet將其實用化,通過實踐證實了它的效果。在AlexNet中主要是最後幾個全連線層使用了Dropout。
Dropout應該是AlexNet網路中一個很大的創新,現在神經網路中的必備結構之一。Dropout也可以看做是一種模型組合,每次生成的網路結構都不一樣,通過組合多個模型的方式能夠有效地減少過擬合。Dropout只需要兩倍的訓練時間即可實現模型組合(類似去平均)的效果。非常高效。
(3)在CNN中使用重疊的最大池化層。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果,並且AlexNet中提出讓步長比池化核的尺寸小,這樣池化層的輸出之間會有重疊和覆蓋,提升了特徵的豐富性。
(4)提出了LRN層,對區域性神經元的活動建立競爭機制,使得其中響應比較大的值變得相對更大,並抑制其他反饋較小的神經元,增強了模型的泛化能力。
LRN層,全稱 Local Response Normalization(區域性響應歸一化)
ReLU具有良好性質:當輸入為正,其導數為1,有效的避免神經元停止學習,也就是死掉。
在神經網路中,我們用啟用函式將神經元的輸出做一個非線性對映,但tanh和sigmoid這些傳統的啟用函式的值域都是有範圍的,但是ReLU啟用函式得到的值域沒有一個區間,所以要對ReLU得到的結果進行歸一化。也就是Local Response Normalization。區域性響應歸一化的方法如下圖的公式:
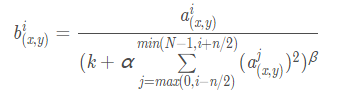
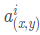 代表的時ReLU 在第 i 個 kernel 的(x,y)位置的輸出, n表示的是 的鄰居個數。N表示該 kernel 的總數量,
代表的時ReLU 在第 i 個 kernel 的(x,y)位置的輸出, n表示的是 的鄰居個數。N表示該 kernel 的總數量,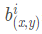 表示的時 LRN的結果。ReLU輸出的結果和他周圍一定範圍的鄰居做一個區域性的歸一化,怎麼理解呢?我覺得這裡有些類似於我們的最大最小歸一化,假設有一個向量 X = [X_1, X_2, ....X_n] 那麼將所有的數歸一化到 0~1之間的歸一化規則是:
表示的時 LRN的結果。ReLU輸出的結果和他周圍一定範圍的鄰居做一個區域性的歸一化,怎麼理解呢?我覺得這裡有些類似於我們的最大最小歸一化,假設有一個向量 X = [X_1, X_2, ....X_n] 那麼將所有的數歸一化到 0~1之間的歸一化規則是:

上面那個公式有著類似的功能,只不過稍微負載一些,首先運算略微複雜,其次還有一些其他的引數 alpah, beta, k。
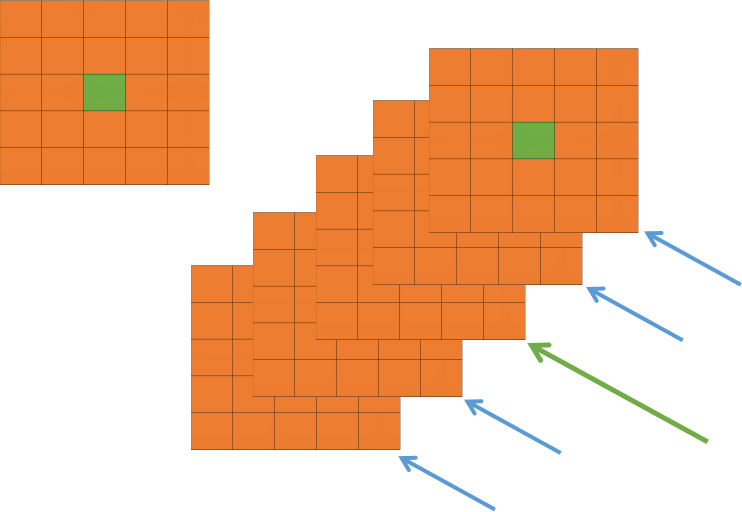
我們看看上圖,每一個矩陣表示的是一個卷積核生成的feature map,所有的pixel已經經過的了ReLU 啟用函式,現在我們都要對具體的 pixel進行區域性的歸一化。假設綠色箭頭指向的是第 i 個 kernel對應的map,其餘的四個藍色箭頭是它周圍的鄰居 kernel層對應的map,假設矩陣中間的綠色的 pixel 的位置為(x, y),那麼我們需要提取出來進行區域性歸一化的資料就是周圍鄰居 kernel 對應的 map(x, y) 位置的 pixel 的值。也就是上面式子的 ,然後把這些鄰居 pixel 的值平方再加和。乘以一個稀疏 alpha 再加上一個常數 k ,然後 beta 次冪,就算分母,分子就是第 i 個 kernel 對應的 map 的(x, y)位置的 pixel的值。這樣理解後我覺得不是那麼的複雜了。
關鍵是引數 alpha,beta,k 如何確定,論文中說是在驗證集中確定,最終確定的結果為:
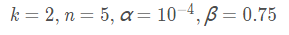
(5)使用CUDA加速神經卷積網路的訓練,利用GPU強大的平行計算能力,處理神經網路訓練時大量的矩陣運算。AlexNet 使用了兩塊 GTX 580 GPU 進行訓練,單個 CTX 580 只有3GB現存,這限制了可訓練的網路的最大規模。因此作者將AlexNet分佈在兩個GPU上,在每個GPU的視訊記憶體中儲存一半的神經元的引數。因此GPU之間通訊方便,可以互相訪問視訊記憶體,而不需要通過主機記憶體,所以同時使用多塊GPU也是非常高效的。同時,AlexNet的設計讓GPU之間的通訊只在網路的某些層進行,控制了通訊的效能損耗。
(6)資料增強,隨機的從256*256的原始影象中擷取224*224大小的區域(以及水平翻轉的映象),相當於增加了(256-224)2*2=2048倍的資料量。如果沒有資料增強,僅靠原始的資料量,引數眾多的CNN會陷入過擬閤中,使用了資料增強後可以大大減輕過擬合,提高泛化能力。進行預測時,則是取圖片的四個角加中間共5個位置,並進行左右翻轉,一共獲得10張圖片,對他們進行預測並對10次結果求均值。同時,AlexNet論文中提到了會對影象的RGB資料進行PCA處理,並對主成分做一個標準差為0.1的高斯擾動,增加了一些噪聲,這個Trick會讓錯誤率再降低1%。
- 隨機裁剪,對256×256的圖片進行隨機裁剪到224×224,然後進行水平翻轉。
- 測試的時候,對左上、右上、左下、右下、中間分別做了5次裁剪,然後翻轉,共10個裁剪,之後對結果求平均。
- 對RGB空間做PCA(主成分分析),然後對主成分做一個(0, 0.1)的高斯擾動,也就是對顏色、光照作變換,結果使錯誤率又下降了1%。
(7) Overlapping Pooling(重疊池化)
在傳統的CNN中,卷積之後一般連線一個池化層,這個池化運算是沒有重疊的池化運算。更加確切的說,池化可以被看作是由間隔為 s 的池化網路構成的,將 z*z 的池化單元的中心放在這個網路上以完成池化操作,如果 s = z ,那麼這個操作就是傳統的 CNN 池化操作,如果 s < z ,就是重疊池化操作,本文就是使用這個方法。
一般的池化層因為沒有重疊,所以pool_size 和 stride一般是相等的,例如8×8的一個影象,如果池化層的尺寸是2×2 ,那麼經過池化後的操作得到的影象是 4×4大小,這種設定叫做不覆蓋的池化操作,如果 stride < pool_size, 那麼就會產生覆蓋的池化操作,這種有點類似於convolutional化的操作,這樣可以得到更準確的結果。在top-1,和top-5中使用覆蓋的池化操作分別將error rate降低了0.4%和0.3%。論文中說,在訓練模型過程中,覆蓋的池化層更不容易過擬合。
2,AlexNet網路的網路結構
整個AlexNet有8個需要訓練引數的層(不包括池化層和LRN層),前5層為卷積層,後3層為全連線層,如下圖所示,ALexNet最後一層是有1000類輸出的Softmax層用作分類。LRN層出現在第一個及第二個卷積層後,而最大池化層出現在兩個LRN層及最後一個卷積層後,ReLU啟用函式則應用在這8層每一層的後面。因為AlexNet訓練時使用了兩塊GPU,因此這個結構圖中不少元件被拆為兩部分。現在我們GPU的視訊記憶體可以放下全部的模型引數,因此只考慮一塊GPU的情況即可。
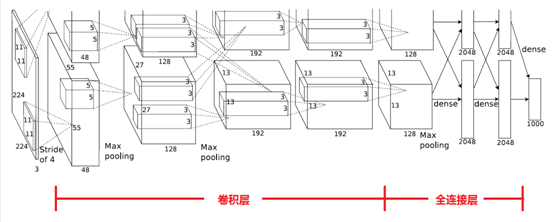
AlexNet 每層的超引數如上圖所示,其中輸入的圖片尺寸為224*224,第一個卷積層使用了較大的卷積核尺寸11*11,步長為4,有96個卷積核;緊接著一個LRN層;然後是一個3*3的最大池化層,步長為2,。這之後的卷積核尺寸都比較小,都是5*5 或者3*3 的大小,並且步長都為1,即會掃描全圖所有畫素;而最大池化層依然保持為3*3,並且步長為2。我們會發現一個比較有意思的現象,在前幾個卷積層,雖然計算量很大,但引數量很小,都在1M 左右甚至更小,只佔AlexNet 總引數量的很小一部分。這就是卷積層有用的地方,可以通過較小的引數量提取有效的特徵,而如果前幾層直接使用全連線層,那麼引數量和計算量將成為天文數字。雖然每一個卷積層佔整個網路的引數量的1%都不到,但是如果去掉任何一個卷積層,都會使網路的分類效能大幅的下降。
(注意:這個224,其實經過計算(224-11)/4=54.75,而不是論文中的55*55,而是227*227,所以假如使用224*224,就讓padding=2)
其實下圖更能讓人理解AlexNet網路結構:
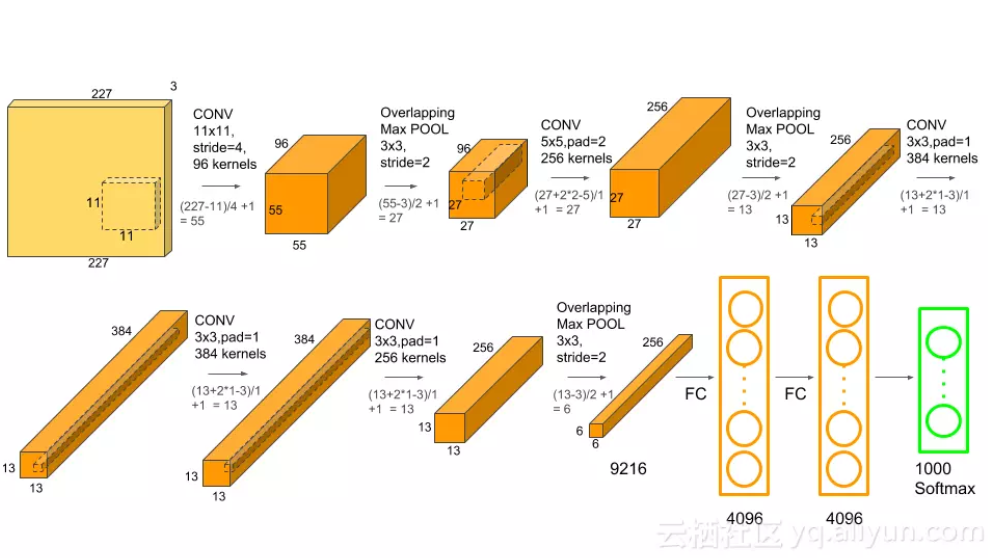
AlexNet 每層的超引數及引數數量:

那下面對照著圖,我們再詳細分析一波這個網路:
其實論文中是使用兩塊GPU來處理的,這就導致了第一個AlexNet的網路結構是分開的,那後面我們用一個架構網路來分析,現在也都9012年了,科技更發達了,所以使用一塊GPU完全可以運算,我們下面來詳細分析一下這8層網路,包括5層卷積,3層全連線。(論文中提到過,五層卷積,去掉任意一層都會使結果不好,所以這個網路的深度似乎比較重要。)
2.1 卷積C1
該層的處理流程是:卷積——》 ReLU ——》池化 ——》 歸一化
- 卷積:輸入的是227*227,使用96個11*11*3的卷積核,得到的FeatureMap為55*55*96
- ReLU:將卷積層輸出的FeatureMap 輸入到ReLU函式中。
- 池化:使用3*3 步長為2的池化單位(重疊池化,步長小於池化單元的寬度),輸出為27*27*96((55-3)/2+1=27)
- 區域性響應歸一化:使用k =2,n=5,alpha=10-4, beta=0.75進行區域性歸一化,輸出仍然是27*27*96,輸出分為兩組,每組為27*27*48。
卷積後的圖形大小是怎麼樣的呢?
width = (227 + 2 * padding - kerne_size)/ stride + 1 = 55
height = (227 + 2 * padding - kerne_size)/ stride + 1 = 55
dimention = 96
2.2 卷積層C2
該層的處理流程是:卷積——》 ReLU ——》池化 ——》 歸一化
- 卷積:輸入的是2組27*27*48,使用2組,每組128個尺寸為5*5*48的卷積核,並做了邊緣填充 padding=2,卷積的步長為1,則輸出的FeatureMap為2組,每組的大小為 27*27*128,((27 + 2*2-5)/1+1=27)
- ReLU:將卷積層輸出的FeatureMap 輸入到ReLU函式中。
- 池化:使用3*3 步長為2的池化單位(重疊池化,步長小於池化單元的寬度),池化後圖像的尺寸為(27-3)/2+1=12,輸出為13*13*256
- 區域性響應歸一化:使用k =2,n=5,alpha=10-4, beta=0.75進行區域性歸一化,輸出仍然是13*13*256,輸出分為兩組,每組為13*13*128。
2.3 卷積層C3
該層的處理流程是: 卷積——》ReLU
-
卷積,輸入是,13*13*256,使用2組共384尺寸為3*3*256的卷積核,做了邊緣填充padding=1,卷積的步長為1,則輸出的FeatureMap 為13*13*384
-
ReLU,將卷積層輸出的FeatureMap輸入到ReLU函式中
2.4 卷積層C4
該層的處理流程是: 卷積——》ReLU
-
卷積,輸入是13*13*384,分為兩組,每組13*13*192,做了邊緣填充padding=1,卷積的步長為1,則輸出的Featuremap為13*13*384
-
ReLU,將卷積層輸出的FeatureMap輸入到ReLU函式中
2.5 卷積層C5
該層的處理流程是:卷積——》 ReLU ——》池化
- 卷積:輸入的是13*13*384,分為兩組,每組13*13*192,使用兩組,每組為128,尺寸為3*3*192的卷積核,做了邊緣填充padding=1,卷積的步長為1,則輸出的FeatureMap為13*13*256
- ReLU:將卷積層輸出的FeatureMap 輸入到ReLU函式中。
- 池化:使用3*3 步長為2的池化單位(重疊池化,步長小於池化單元的寬度),池化後圖像的尺寸為(13-3)/2+1=12,輸出為6*6*256
2.6 全連線層FC6
流程為:(卷積)全連線——》 ReLU ——》 Dropout
- 卷積(全連線):輸入為6*6*256,該層有4096個卷積核,每個卷積核的大小為6*6*256.由於卷積核的尺寸剛好與待處理特徵圖(輸入)的尺寸相同,即卷積核中的每個係數只與特徵圖(輸入)尺寸的一個畫素值相乘,一一對應,因此,該層被稱為全連線層。由於卷積核與特徵圖的尺寸相同,卷積運算後只有一個值,因此,卷積後的畫素層尺寸為 4096*1*1,即有4096個神經元。
- ReLU:這4096個運算結果通過ReLU啟用函式生成4096個值
- Dropout:抑制過擬合,隨機的斷開某些神經元的連線或者是不啟用某些神經元
2.7 全連線層FC7
流程為:全連線——》 ReLU ——》 Dropout
- 全連線:輸入為4096的向量
- ReLU:這4096個運算結果通過ReLU啟用函式生成4096個值
- Dropout:抑制過擬合,隨機的斷開某些神經元的連線或者是不啟用某些神經元
2.8 輸出層
第七層的神經元的個數為 4096,第八層最終輸出 softmax為1000個。
3,AlexNet 引數數量
卷積層的引數 = 卷積核的數量 * 卷積核 + 偏置
- C1:96個11*11*3的卷積核,96*11*11*3 + 96 = 34848
- C2:2組,每組128個5*5*48的卷積核,(128*5*5*48+128)*2=307456
- C3:384個3*3*256的卷積核,3*3*256*384+384=885120
- C4:2組,每組192個3*3*192的卷積核,(3*3*192*192+192)*2=663936
- C5:2組,每組128個3*3*192的卷積核,(3*3*192*128+128)*2=442624
- FC6:4096個6*6*256的卷積核,6*6*256*4096+4096=37752832
- FC7:4096*4096+4096=16781312
- output:4096+1000=4096000
卷積層 C2,C4,C5中的卷積核只和位於同一GPU的上一層的FeatureMap相連。從上面可以看出,引數大多數集中在全連線層,在卷積層由於權值共享,權值引數較少。
4,AlexNet網路的TensorFlow實現
因為使用 ImageNet資料集訓練一個完整的AlexNet耗時非常長,因此下面學習的AlexNet的實現將不涉及實際資料的訓練。我們會建立一個完整的ALexNet卷積神經網路,然後對它每個batch的前饋計算(forward)和反饋計算(backward)的速度進行測試。這裡使用隨機圖片資料來計算每輪前饋,反饋的平均耗時。當然也可以下載ImageNet資料並使用AlexNet網路完成訓練,並在測試集上進行測試。
首先,定義一個用來顯示網路每一層結構的函式 print_actications,展示每一個卷積層或池化層輸出 tensor 的尺寸。這個函式一般接受一個 tensor作為輸入,並顯示其名稱(t.op.name)和 tensor尺寸(t.get_shape.as_list())。
# 定義一個用來顯示網路每一層結構的函式 print_actications 展示每一個卷積層或者輸出tensor的尺寸
# 此函式接受一個tensor作為輸入,並顯示其名稱(t.op.name)和tensor尺寸
def print_activations(t):
print(t.op.name, ' ', t.get_shape().as_list())
接下來設計AlexNet的網路結構,我們先定義函式 inference,它接受 images作為輸入,返回最後一層 pool5(第5個池化層)及 paramenters(AlexNet 中所有需要訓練的模型引數)。這個 inference 函式將會很大,包括多個卷積和池化層,因此下面將拆分學習。
首先是第一個卷積層 conv1,這裡使用 TensorFlow 中的 name_scope,通過 with.tf.name_scope('conv1') as scope 可以將 scope 內生成的 Variable 自動命名為 conv1/xxx,便於區分不同卷積層之間的元件。然後定義第一個卷積層,和之前一樣使用 tf.truncated_normal 截斷的正態分佈函式(標準差為0.1)初始化卷積核的引數 kernel。卷積核尺寸為11*11,顏色通道為 3 ,卷積核數量為64.準確好了 kernel ,再使用 tf.nn.conv2d 對輸入 images 完成卷積操作,我們將 strides 步長設定為4*4(即在圖片上每4*4 區域只取樣一次,橫向間隔是4,縱向間隔也為4,每次取樣的卷積核大小都是11*11),padding模式設為SAME。將卷積層的biases全部初始化為0,再使用 tf.nn.bias_add 將 conv 和 biases 加起來,並使用啟用函式 tf.nn.relu 對結果進行非線性處理。最後使用 print_actations 將這一層最後輸出的 tensor conv1 的結構打印出來,並將這一層可訓練的引數 kernel,biases 新增到 parameters中。
def inference(images):
parameters = []
with tf.name_scope('conv1') as scope:
kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 64],
dtype=tf.float32, stddev=1e-1), name='weights')
conv = tf.nn.conv2d(images, kernel, [1, 4, 4, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)
print_activations(conv1)
parameters += [kernel, biases]
在第一個卷積層後再新增LRN層和最大池化層。先使用 tf.nn.lrn 對前面輸出的 tensor conv1 進行 LRN 處理,這裡使用的 depth_radius 設為4,bias設為1,alpha為0.001/9,beta為0.75,基本都是AlexNet 的論文中的推薦值。不過目前除了 AlexNet,其他經典的卷積神經網路模型都放棄了 LRN (主要是效果不明顯),而我們使用 LRN 也會讓前饋,反饋的速度大大下降(整體速度降到1/3),大家可以支柱選擇是否使用 LRN。下面使用 tf.nn.max_pool 對前面的輸出 lrn1 進行最大池化處理,這裡的池化尺寸為 3*3,即將3*3大小的畫素塊降為 1*1 的畫素,取樣的步長為 2*2,padding 模式設為 VALID,即取樣時不能超過邊框,不像SAME模式那樣可以填充邊界外的點。最後將輸出結果 pool1 的結構打印出來。
lrn1 = tf.nn.lrn(conv1, 4, bias=1.0, alpha=0.001/9, beta=0.75, name='lrn1')
pool1 = tf.nn.max_pool(lrn1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='VALID', name='pool1')
print_activations(pool1)
接下來設計第二個卷積層,大部分步驟和第一個卷積層相同,只有幾個引數不同。主要區別在於我們的卷積核尺寸是 5*5,輸入通道數(即上一層輸出通道數,也就是上一層卷積核數量)為64,卷積核數量為192。同時,卷積的步長也全部設為1,即掃描全影象素。
with tf.name_scope('conv2') as scope:
kernel = tf.Variable(tf.truncated_normal([5, 5, 64, 192],
dtype=tf.float32, stddev=1e-1),
name='weights')
conv = tf.nn.conv2d(pool1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[192],
dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv2)
接下來對第二個卷積層的輸出 conv2 進行處理,同樣先做 LRN處理,再進行最大池化處理,引數和之前完全一樣,這裡不再贅述了。
# 接下來對第二個卷積層的輸出 conv2 進行處理,同樣是做了LRN處理,再進行最大池化處理
lrn2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001/9, beta=0.75, name='lrn2')
pool2 = tf.nn.max_pool(lrn2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='VALID', name='pool2')
print_activations(pool2)
接下來建立第三個卷積層,基本結構和前面兩個類似,也只是引數不同。這一層的卷積核尺寸為3*3,輸入的通道數為192,卷積核數量繼續擴大為384,同樣卷積的步長全部為1,其他地方和前面的保持一致。
# 第三個卷積層
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 384],
dtype=tf.float32,stddev=1e-1),
name='weights')
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384],
dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv3)
第四個卷積層和之前也類似,這一層的卷積核尺寸為3*3,輸入通道數為384,但是卷積核數量降為256。
# 第四個卷積層,核尺寸為3*3,輸入通道數為384, 但是卷積核數量降低為256
with tf.name_scope('conv4') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 256],
dtype=tf.float32, stddev=1e-1),
name='weights')
conv = tf.nn.conv2d(conv3, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256],
dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv4 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv4)
最後的第五個卷積層同樣是3*3 大小的卷積核,輸入通道數為256,卷積核數量也為256。
# 第五個卷積層同樣是3*3大小的卷積核,輸入通道數為256, 卷積核數量也是256
with tf.name_scope('conv5') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256],
dtype=tf.float32, stddev=1e-1),
name='weights')
conv = tf.nn.conv2d(conv4, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256],
dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv5 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv5)
在第五個卷積層之後,還有一個最大池化層,這個池化層和前兩個卷積層後的池化層一致,最後我們返回這個池化層的輸出 pool5。至此,inference函式就完成了,它可以建立 AlexNet 的卷積部分。在正式使用 AlexNet來訓練或預測時,還需要新增3個全連線層,隱含節點數分別為 4096,4096和1000。由於最後三個全連線層的計算量很小,就沒放到計算速度測評中,他們對計算耗時的影響非常小。大家在正式使用 AlexNet時需要自行新增這三個全連線層,全連線層在TensorFlow中的實現方法在之前已經學習過了,這裡不再贅述。
pool5 = tf.nn.max_pool(conv5, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='VALID', name='pool5')
print_activations(pool5)
return pool5, parameters
接下來實現一個評估 AlexNet每輪計算時間的函式 time_tensorflow_run。這個函式的第一個輸入是 TensorFlow的Session,第二個變數是需要評測的運算運算元,第三個變數是測試的名稱。先定義預測輪數 num_steps_burn_in=10,它的作用是給程式熱身,頭幾輪迭代有視訊記憶體載入,cache命中等問題因此可以跳過,我們只靠量10輪迭代之後的計算時間。同時,也記錄總時間 total_duration 和平方和 total_duration_squared 用以計算方差。
def time_tensorflow_run(session, target, info_string):
num_steps_burn_in = 10
total_duration = 0.0 # 記錄總時間
total_duration_squared = 0.0 # 記錄平方和total_duration_squared用於計算方差
我們進行 num_batches + num_steps_burn_in 次迭代計算,使用 time.time() 記錄時間,每次迭代通過 session.run(target)執行。在初始熱身的 num_steps_burn_in 次迭代後,每10輪迭代顯示當前迭代所需要的時間。同時每輪將 total_duration 和 total_duration_dquared累加,以便後面每輪耗時的均值和標準差。
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: stpe %d, duration=%.3f'%(datetime.now(),
i-num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
在迴圈結束後,計算每輪迭代的平均耗時 mn 和 標準差 sd,最後將結果顯示出來。這樣就完成了計算每輪迭代耗時的評測函式 time_tensorflow_run。
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn*mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch'%(datetime.now(),
info_string, num_batches, mn, sd))
接下來是主函式 run_benchmark。首先是要 with tf.Graph().as_default() 定義預設的 Graph 方便後面使用。如前面所說,我們這裡不使用 ImageNet 資料集來訓練,只使用隨機圖片資料測試前饋和反饋計算的耗時。我們使用 tf.random_normal 函式構造正態分佈(標準差為0.1)的隨機 tensor ,第一個維度是 batch_size,即每輪迭代的樣本數,第二個和第三個維度是圖片的尺寸 image_size = 224,第四個維度是圖片的顏色通道數。接下來,使用前面定義的 inference 函式構建整個 AlexNet網路,得到最後一個池化層的輸出 pool5 和網路中需要訓練的引數的集合 parameters。接下來,我們使用 tf.Session() 建立新的 Session 並通過 tf.global_variables_initializer() 初始化所有引數。
def run_benchmark():
with tf.Graph().as_default():
image_size = 224
images = tf.Variable(tf.random_normal([batch_size,
image_size,
image_size, 3],
dtype=tf.float32,
stddev=1e-1))
pool5, parameters = inference(images)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
下面進行 AlexNet的 forward 計算的測評,這裡直接使用 time_tensorflow_run 統計運算時間,傳入的 target 就是 pool5,即卷積網路最後一個池化層的輸出。然後進行 backward 即訓練過程的評測,這裡和 forward 計算有些不同,我們需要給最後的輸出 pool5 設定一個優化目標 loss。我們使用 tf.nn.l2_loss 計算 pool5的loss,再使用 tf.gradients求相對於 loss 的所有模型引數的梯度,這樣就模擬了一個訓練的額過程。當然,訓練時還有一個根據梯度更新引數的過程,不過這個計算量很小,就不統計在評測程式裡了。最後我們使用 time_tensorflow_run 統計 backward 的執行時間,這裡的 target 就是求整個網路梯度 grad 的操作。
time_tensorflow_run(sess, 'pool5', 'Forward') objective = tf.nn.l2_loss(pool5) grad = tf.gradients(objective, parameters) time_tensorflow_run(sess, grad, 'Forward-backward')
最後執行主函式:
if __name__ == '__main__':
run_benchmark()
程式顯示的結果有三段,首先是 AlexNet的網路結構,可以看到我們定義的 5個卷積層中第1 個,第二個和第五個卷積後面還連線著池化層,另外每一層輸出 tensor 的尺寸也顯示出來了。
conv1 [32, 56, 56, 64] pool1 [32, 27, 27, 64] conv2 [32, 27, 27, 192] pool2 [32, 13, 13, 192] conv3 [32, 13, 13, 384] conv4 [32, 13, 13, 256] conv5 [32, 13, 13, 256] pool5 [32, 6, 6, 256]
然後顯示的是 forward 計算的時間。我是在伺服器上執行,配置了GPU,所以在LRN層時每輪迭代時間大約為0.010s;去除LRN層後,每輪的迭代時間大約0.030s,速度也快了3倍多。因為 LRN層對最終準確率的影響不是很大,所以大家可以考慮是否使用 LRN。
2019-09-10 18:03:08.871731: stpe 0, duration=0.010 2019-09-10 18:03:08.969771: stpe 10, duration=0.010 2019-09-10 18:03:09.066901: stpe 20, duration=0.010 2019-09-10 18:03:09.163687: stpe 30, duration=0.010 2019-09-10 18:03:09.260273: stpe 40, duration=0.010 2019-09-10 18:03:09.356837: stpe 50, duration=0.010 2019-09-10 18:03:09.453185: stpe 60, duration=0.010 2019-09-10 18:03:09.549359: stpe 70, duration=0.010 2019-09-10 18:03:09.645590: stpe 80, duration=0.010 2019-09-10 18:03:09.741800: stpe 90, duration=0.010 2019-09-10 18:03:09.828454: Forward across 100 steps, 0.001 +/- 0.003 sec / batch
然後就是顯示的 backward 運算的時間。在使用 LRN 層時,每輪的迭代時間為 0.031s,在去除LRN層後,每輪迭代時間約為0.025s,速度也快了3倍多。另外可以發現不論是否有 LRN 層,我們 backward 運算的耗時大約是 forward 耗時的三倍。
2019-09-10 18:03:10.404082: stpe 0, duration=0.031 2019-09-10 18:03:10.712611: stpe 10, duration=0.031 2019-09-10 18:03:11.020057: stpe 20, duration=0.031 2019-09-10 18:03:11.326645: stpe 30, duration=0.031 2019-09-10 18:03:11.632946: stpe 40, duration=0.030 2019-09-10 18:03:11.940875: stpe 50, duration=0.031 2019-09-10 18:03:12.249667: stpe 60, duration=0.031 2019-09-10 18:03:12.556174: stpe 70, duration=0.031 2019-09-10 18:03:12.863977: stpe 80, duration=0.031 2019-09-10 18:03:13.172933: stpe 90, duration=0.031 2019-09-10 18:03:13.451794: Forward-backward across 100 steps, 0.003 +/- 0.009 sec / batch
CNN的訓練過程(即backward計算)通常都比較耗時,而且不想預測過程(即 forward計算),訓練通常需要過很多遍資料,進行大量的迭代。因此應用CNN的主要瓶頸還是在訓練,用 CNN 做預測問題不大。
至此,AlexNet的TensorFlow實現和運算時間評測就完成了。AlexNet為卷積神經網路和深度學習正名,以絕對優勢拿下ILSVRC 2012 冠軍,引起學術界的極大關注,為復興神經網路做出來很大的貢獻。ALexNet 在 ILSVRC 資料集上可達到 16.4% 的錯誤率(大家可以自行下載資料集測試,但是要注意 batch_size 可能要設為1 才能復現論文中的結果),其中用到的許多網路結構和 Trick 給深度學習的發展帶來了深刻地影響。當然,我們決不能忽略 ImageNet 資料集給深度學習帶來的 貢獻。訓練深度卷積神經網路,必須擁有一個像ImageNet這樣超大的資料集才能避免過擬合,發展深度學習的優勢。可以說,傳統機器學習模型適合學習一個小型資料集,但是對於大型資料集,我們需要有更大的學習容量(Learning Capacity)的模型,即深度學習模型。
完整程式碼如下:
from datetime import datetime
import math
import time
import tensorflow as tf
batch_size = 32
num_batches = 100
def print_activations(t):
print(t.op.name, ' ', t.get_shape().as_list())
def inference(images):
parameters = []
# conv1
with tf.name_scope('conv1') as scope:
kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 64], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(images, kernel, [1, 4, 4, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)
print_activations(conv1)
parameters += [kernel, biases]
# pool1
lrn1 = tf.nn.lrn(conv1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='lrn1')
pool1 = tf.nn.max_pool(lrn1,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool1')
print_activations(pool1)
# conv2
with tf.name_scope('conv2') as scope:
kernel = tf.Variable(tf.truncated_normal([5, 5, 64, 192], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[192], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv2)
# pool2
lrn2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='lrn2')
pool2 = tf.nn.max_pool(lrn2,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool2')
print_activations(pool2)
# conv3
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 384],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv3)
# conv4
with tf.name_scope('conv4') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 256],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv3, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv4 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv4)
# conv5
with tf.name_scope('conv5') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv4, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv5 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv5)
# pool5
pool5 = tf.nn.max_pool(conv5,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool5')
print_activations(pool5)
return pool5, parameters
def time_tensorflow_run(session, target, info_string):
# """Run the computation to obtain the target tensor and print timing stats.
#
# Args:
# session: the TensorFlow session to run the computation under.
# target: the target Tensor that is passed to the session's run() function.
# info_string: a string summarizing this run, to be printed with the stats.
#
# Returns:
# None
# """
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: step %d, duration = %.3f' %
(datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %
(datetime.now(), info_string, num_batches, mn, sd))
def run_benchmark():
# """Run the benchmark on AlexNet."""
with tf.Graph().as_default():
# Generate some dummy images.
image_size = 224
# Note that our padding definition is slightly different the cuda-convnet.
# In order to force the model to start with the same activations sizes,
# we add 3 to the image_size and employ VALID padding above.
images = tf.Variable(tf.random_normal([batch_size,
image_size,
image_size, 3],
dtype=tf.float32,
stddev=1e-1))
# Build a Graph that computes the logits predictions from the
# inference model.
pool5, parameters = inference(images)
# Build an initialization operation.
init = tf.global_variables_initializer()
# Start running operations on the Graph.
config = tf.ConfigProto()
config.gpu_options.allocator_type = 'BFC'
sess = tf.Session(config=config)
sess.run(init)
# Run the forward benchmark.
time_tensorflow_run(sess, pool5, "Forward")
# Add a simple objective so we can calculate the backward pass.
objective = tf.nn.l2_loss(pool5)
# Compute the gradient with respect to all the parameters.
grad = tf.gradients(objective, parameters)
# Run the backward benchmark.
time_tensorflow_run(sess, grad, "Forward-backward")
if __name__ == '__main__':
run_benchmark()
5,Keras實現AlexNet網路
下面貼上的是網友在Keras上實現的AlexNet網路程式碼。
由於AlexNet是使用兩塊顯示卡進行訓練的,其網路結構的實際是分組進行的。並且,在C2,C4,C5上其卷積核只和上一層的同一個GPU上的卷積核相連。 對於單顯示卡來說,並不適用,本文基於Keras的實現,忽略其關於雙顯示卡的的結構,並且將區域性歸一化操作換成了BN。其網路結構如下
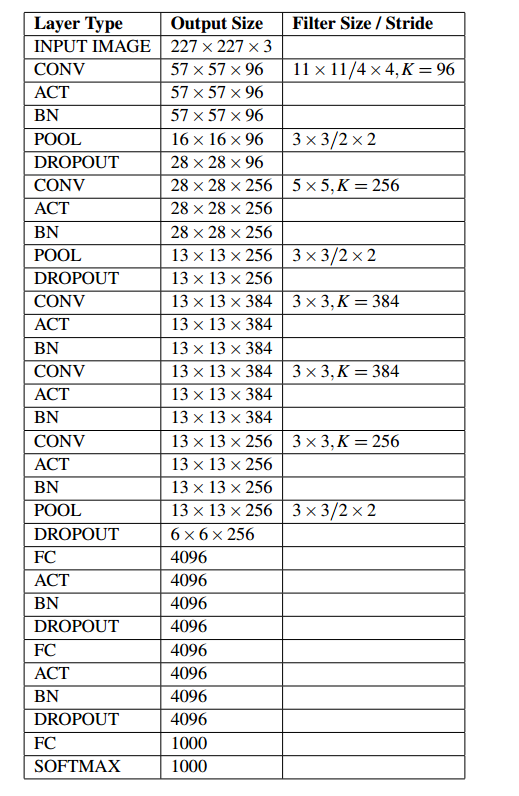
利用Keras實現AlexNet:
from keras.models import Sequential
from keras.layers import Dense, Flatten, Dropout
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.utils.np_utils import to_categorical
import numpy as np
seed = 7
np.random.seed(seed)
# 建立模型序列
model = Sequential()
#第一層卷積網路,使用96個卷積核,大小為11x11步長為4, 要求輸入的圖片為227x227, 3個通道,不加邊,啟用函式使用relu
model.add(Conv2D(96, (11, 11), strides=(1, 1), input_shape=(28, 28, 1), padding='same', activation='relu',
kernel_initializer='uniform'))
# 池化層
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
# 第二層加邊使用256個5x5的卷積核,加邊,啟用函式為relu
model.add(Conv2D(256, (5, 5), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
#使用池化層,步長為2
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
# 第三層卷積,大小為3x3的卷積核使用384個
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
# 第四層卷積,同第三層
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
# 第五層卷積使用的卷積核為256個,其他同上
model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
model.summary()
參考來源:(https://blog.csdn.net/qq_41559533/article/details/83718778 )
本文是學習AlexNet網路的筆記,參考了《tensorflow實戰》這本書中關於AlexNet的章節,寫的非常好,所以在此做了筆記,侵刪。
參考文獻:https://www.jianshu.com/p/00a53eb5f4b3
https://blog.csdn.net/luoluonuoyasuolong/article/details/81750190
https://www.cnblogs.com/wangguchangqing/p/10333370.