
程式設計師需要了解的硬核知識之組合語言(一)
之前的系列文章從 CPU 和記憶體方面簡單介紹了一下組合語言,但是還沒有系統的瞭解一下組合語言,組合語言作為第二代計算機語言,會用一些容易理解和記憶的字母,單詞來代替一個特定的指令,作為高階程式語言的基礎,有必要系統的瞭解一下組合語言,那麼本篇文章希望大家跟我一起來了解一下組合語言。
組合語言和原生代碼
我們在之前的文章中探討過,計算機 CPU 只能執行原生代碼(機器語言)程式,用 C 語言等高階語言編寫的程式碼,需要經過編譯器編譯後,轉換為原生代碼才能夠被 CPU 解釋執行。
但是原生代碼的可讀性非常差,所以需要使用一種能夠直接讀懂的語言來替換原生代碼,那就是在各原生代碼中,附帶上表示其功能的英文縮寫,比如在加法運算的原生代碼加上add(addition)
cmp(compare)的縮寫等,這些通過縮寫來表示具體原生代碼指令的標誌稱為 助記符,使用助記符的語言稱為組合語言。這樣,通過閱讀組合語言,也能夠了解原生代碼的含義了。
不過,即使是使用匯編語言編寫的原始碼,最終也必須要轉換為原生代碼才能夠執行,負責做這項工作的程式稱為編譯器,轉換的這個過程稱為彙編。在將原始碼轉換為原生代碼這個功能方面,彙編器和編譯器是同樣的。
用匯編語言編寫的原始碼和原生代碼是一一對應的。因而,原生代碼也可以反過來轉換成組合語言編寫的程式碼。把原生代碼轉換為彙編程式碼的這一過程稱為反彙編,執行反彙編的程式稱為反彙編程式。

哪怕是 C 語言編寫的原始碼,編譯後也會轉換成特定 CPU 用的原生代碼。而將其反彙編的話,就可以得到組合語言的原始碼,並對其內容進行調查。不過,原生代碼變成 C 語言原始碼的反編譯,要比原生代碼轉換成彙編程式碼的反彙編要困難,這是因為,C 語言程式碼和原生代碼不是一一對應的關係。
通過編譯器輸出組合語言的原始碼
我們上面提到原生代碼可以經過反彙編轉換成為彙編程式碼,但是隻有這一種轉換方式嗎?顯然不是,C 語言編寫的原始碼也能夠通過編譯器編譯稱為彙編程式碼,下面就來嘗試一下。
首先需要先做一些準備,需要先下載 Borland C++ 5.5 編譯器,為了方便,我這邊直接下載好了讀者直接從我的百度網盤提取即可 (連結:https://pan.baidu.com/s/19LqVICpn5GcV88thD2AnlA 密碼:hz1u)
下載完畢,需要進行配置,下面是配置說明 (https://wenku.baidu.com/view/22e2f418650e52ea551898ad.html),教程很完整跟著配置就可以,下面開始我們的編譯過程
首先用 Windows 記事本等文字編輯器編寫如下程式碼
// 返回兩個引數值之和的函式
int AddNum(int a,int b){
return a + b;
}
// 呼叫 AddNum 函式的函式
void MyFunc(){
int c;
c = AddNum(123,456);
}編寫完成後將其檔名儲存為 Sample4.c ,C 語言原始檔的副檔名,通常用.c 來表示,上面程式是提供兩個輸入引數並返回它們之和。
在 Windows 作業系統下開啟 命令提示符,切換到儲存 Sample4.c 的資料夾下,然後在命令提示符中輸入
bcc32 -c -S Sample4.cbcc32 是啟動 Borland C++ 的命令,-c 的選項是指僅進行編譯而不進行連結,-S 選項被用來指定生成組合語言的原始碼
作為編譯的結果,當前目錄下會生成一個名為Sample4.asm 的組合語言原始碼。組合語言原始檔的副檔名,通常用.asm 來表示,下面就讓我們用編輯器開啟看一下 Sample4.asm 中的內容
.386p
ifdef ??version
if ??version GT 500H
.mmx
endif
endif
model flat
ifndef ??version
?debug macro
endm
endif
?debug S "Sample4.c"
?debug T "Sample4.c"
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends
DGROUP group _BSS,_DATA
_TEXT segment dword public use32 'CODE'
_AddNum proc near
?live1@0:
;
; int AddNum(int a,int b){
;
push ebp
mov ebp,esp
;
;
; return a + b;
;
@1:
mov eax,dword ptr [ebp+8]
add eax,dword ptr [ebp+12]
;
; }
;
@3:
@2:
pop ebp
ret
_AddNum endp
_MyFunc proc near
?live1@48:
;
; void MyFunc(){
;
push ebp
mov ebp,esp
;
; int c;
; c = AddNum(123,456);
;
@4:
push 456
push 123
call _AddNum
add esp,8
;
; }
;
@5:
pop ebp
ret
_MyFunc endp
_TEXT ends
public _AddNum
public _MyFunc
?debug D "Sample4.c" 20343 45835
end這樣,編譯器就成功的把 C 語言轉換成為了彙編程式碼了。
不會轉換成原生代碼的偽指令
第一次看到彙編程式碼的讀者可能感覺起來比較難,不過實際上其實比較簡單,而且可能比 C 語言還要簡單,為了便於閱讀彙編程式碼的原始碼,需要注意幾個要點
組合語言的原始碼,是由轉換成原生代碼的指令(後面講述的操作碼)和針對彙編器的偽指令構成的。偽指令負責把程式的構造以及彙編的方法指示給彙編器(轉換程式)。不過偽指令是無法彙編轉換成為原生代碼的。下面是上面程式擷取的偽指令
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends
DGROUP group _BSS,_DATA
_AddNum proc near
_AddNum endp
_MyFunc proc near
_MyFunc endp
_TEXT ends
end由偽指令 segment 和 ends 圍起來的部分,是給構成程式的命令和資料的集合體上加一個名字而得到的,稱為段定義。段定義的英文表達具有區域的意思,在這個程式中,段定義指的是命令和資料等程式的集合體的意思,一個程式由多個段定義構成。
上面程式碼的開始位置,定義了3個名稱分別為 _TEXT、_DATA、_BSS 的段定義,_TEXT 是指定的段定義,_DATA 是被初始化(有初始值)的資料的段定義,_BSS 是尚未初始化的資料的段定義。這種定義的名稱是由 Borland C++ 定義的,是由 Borland C++ 編譯器自動分配的,所以程式段定義的順序就成為了 _TEXT、_DATA、_BSS ,這樣也確保了記憶體的連續性
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends段定義( segment ) 是用來區分或者劃分範圍區域的意思。組合語言的 segment 偽指令表示段定義的起始,ends 偽指令表示段定義的結束。段定義是一段連續的記憶體空間
而group 這個偽指令表示的是將 _BSS和_DATA 這兩個段定義彙總名為 DGROUP 的組
DGROUP group _BSS,_DATA圍起 _AddNum 和 _MyFun 的 _TEXT segment 和 _TEXT ends ,表示_AddNum 和 _MyFun 是屬於 _TEXT 這一段定義的。
_TEXT segment dword public use32 'CODE'
_TEXT ends因此,即使在原始碼中指令和資料是混雜編寫的,經過編譯和彙編後,也會轉換成為規整的原生代碼。
_AddNum proc 和 _AddNum endp 圍起來的部分,以及_MyFunc proc 和 _MyFunc endp 圍起來的部分,分別表示 AddNum 函式和 MyFunc 函式的範圍。
_AddNum proc near
_AddNum endp
_MyFunc proc near
_MyFunc endp編譯後在函式名前附帶上下劃線_ ,是 Borland C++ 的規定。在 C 語言中編寫的 AddNum 函式,在內部是以 _AddNum 這個名稱處理的。偽指令 proc 和 endp 圍起來的部分,表示的是 過程(procedure) 的範圍。在組合語言中,這種相當於 C 語言的函式的形式稱為過程。
末尾的 end 偽指令,表示的是原始碼的結束。
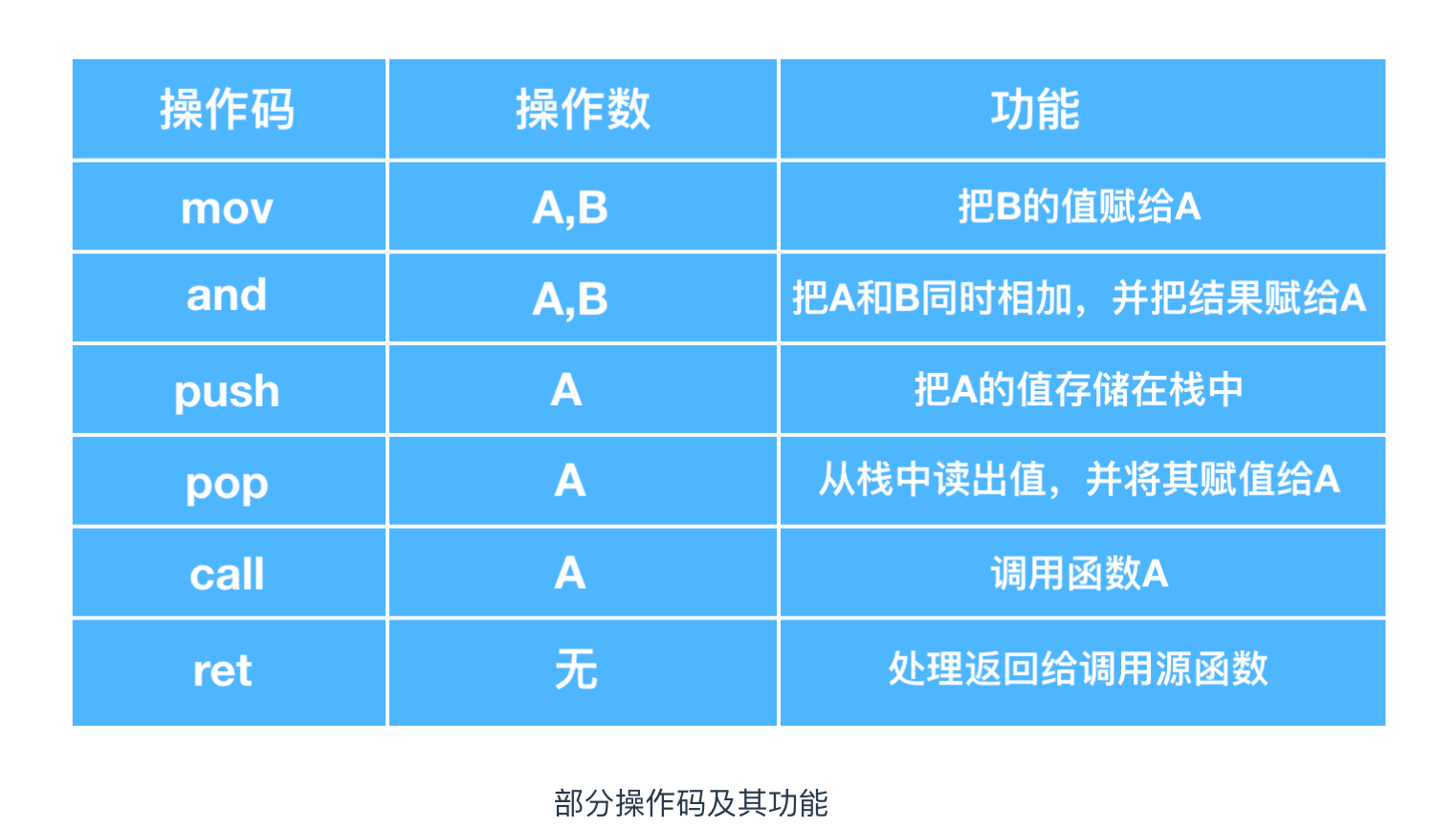
## 組合語言的語法是 操作碼 + 運算元
在組合語言中,一行表示一對 CPU 的一個指令。組合語言指令的語法結構是 操作碼 + 運算元,也存在只有操作碼沒有運算元的指令。
操作碼錶示的是指令動作,運算元表示的是指令物件。操作碼和運算元一起使用就是一個英文指令。比如從英語語法來分析的話,操作碼是動詞,運算元是賓語。比如這個句子 Give me money這個英文指令的話,Give 就是操作碼,me 和 money 就是運算元。組合語言中存在多個運算元的情況,要用逗號把它們分割,就像是 Give me,money 這樣。
能夠使用何種形式的操作碼,是由 CPU 的種類決定的,下面對操作碼的功能進行了整理。
原生代碼需要載入到記憶體後才能執行,記憶體中儲存著構成原生代碼的指令和資料。程式執行時,CPU會從記憶體中把資料和指令讀出來,然後放在 CPU 內部的暫存器中進行處理。
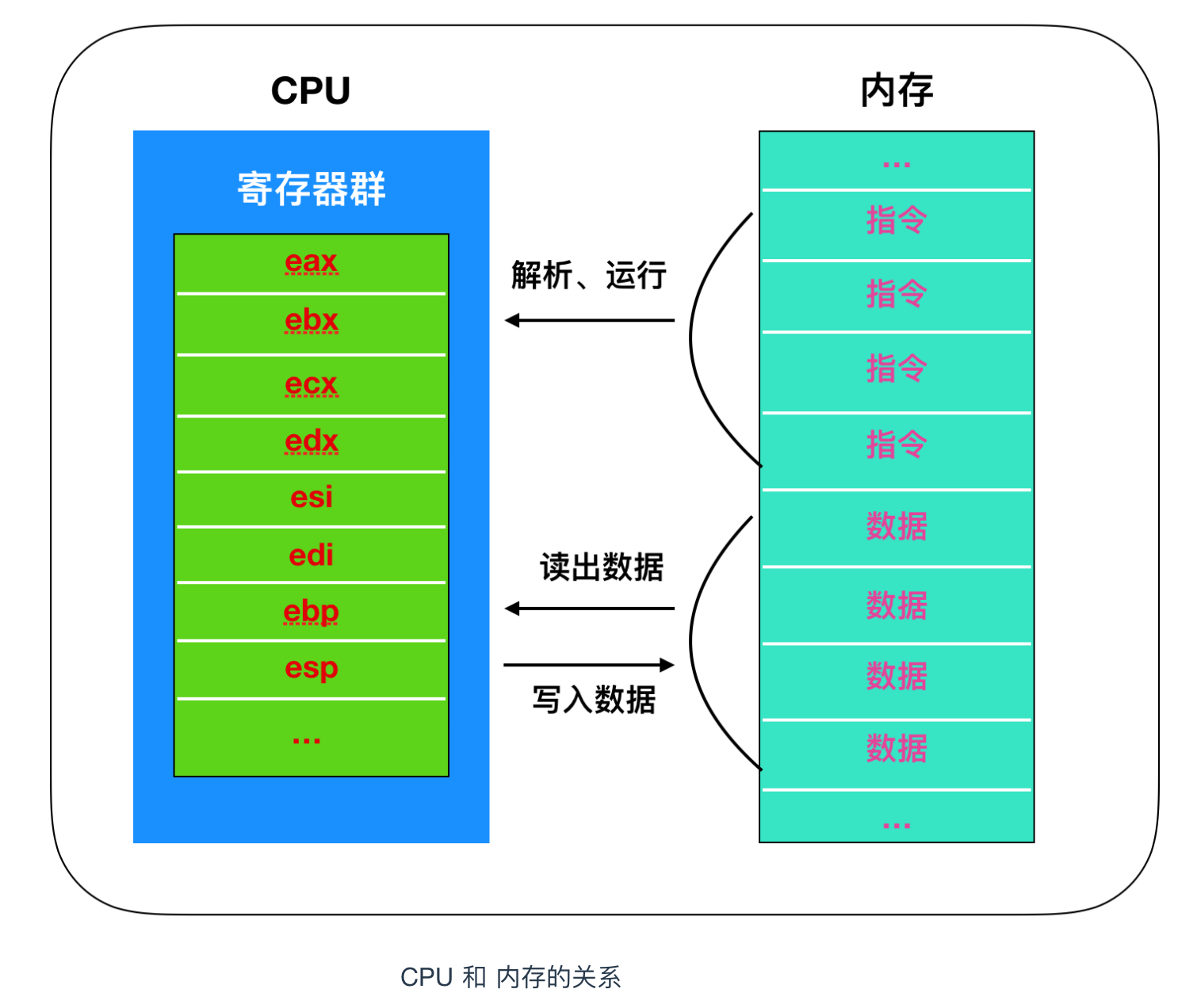
如果 CPU 和記憶體的關係你還不是很瞭解的話,請閱讀作者的另一篇文章 程式設計師需要了解的硬核知識之CPU 詳細瞭解。
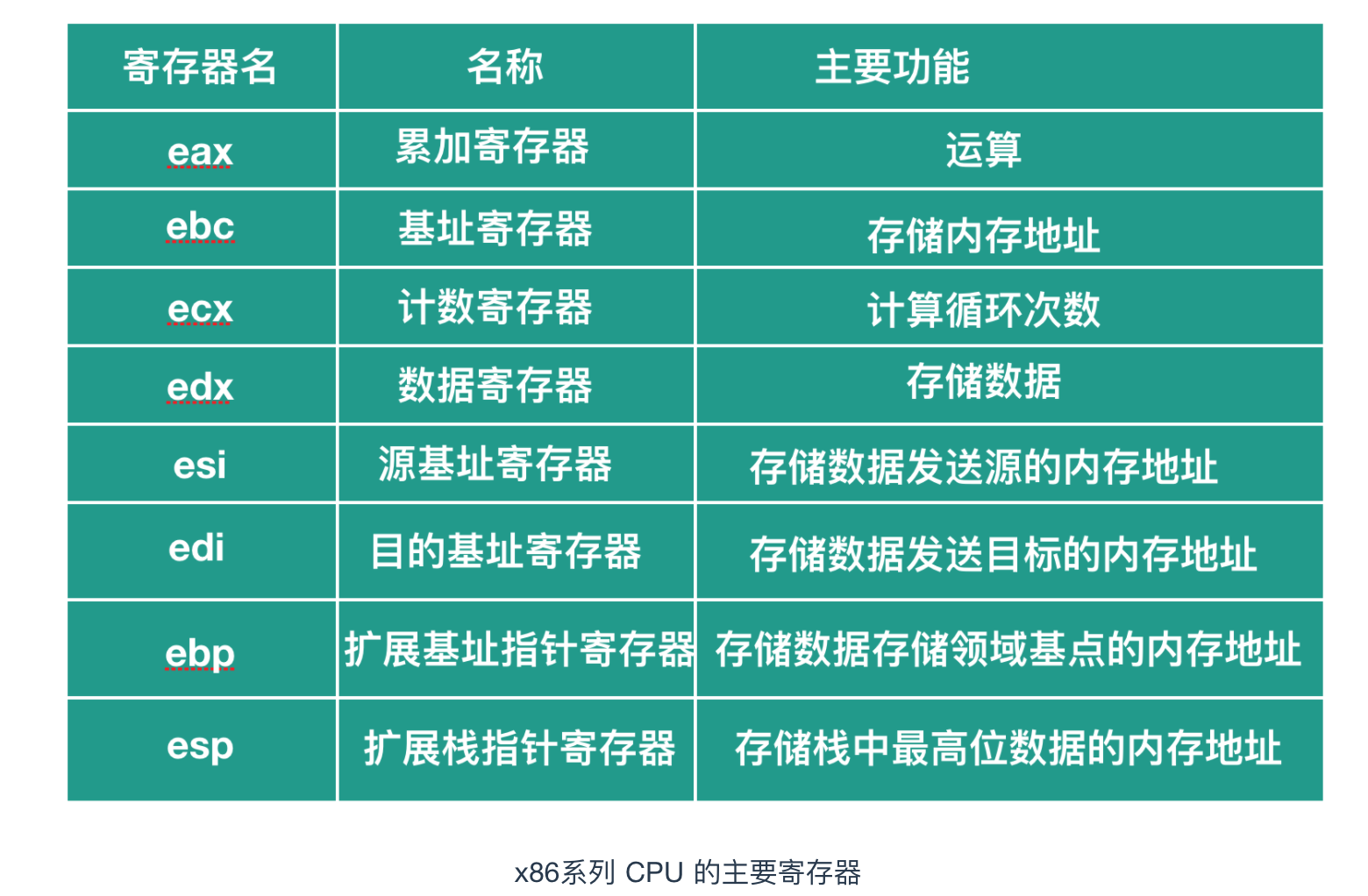
暫存器是 CPU 中的儲存區域,暫存器除了具有臨時儲存和計算的功能之外,還具有運算功能,x86 系列的主要種類和角色如下圖所示
指令解析
下面就對 CPU 中的指令進行分析
最常用的 mov 指令
指令中最常使用的是對暫存器和記憶體進行資料儲存的 mov 指令,mov 指令的兩個運算元,分別用來指定資料的儲存地和讀出源。運算元中可以指定暫存器、常數、標籤(附加在地址前),以及用方括號([]) 圍起來的這些內容。如果指定了沒有用([]) 方括號圍起來的內容,就表示對該值進行處理;如果指定了用方括號圍起來的內容,方括號的值則會被解釋為記憶體地址,然後就會對該記憶體地址對應的值進行讀寫操作。讓我們對上面的程式碼片段進行說明
mov ebp,esp
mov eax,dword ptr [ebp+8]mov ebp,esp 中,esp 暫存器中的值被直接儲存在了 ebp 中,也就是說,如果 esp 暫存器的值是100的話那麼 ebp 暫存器的值也是 100。
而在 mov eax,dword ptr [ebp+8] 這條指令中,ebp 暫存器的值 + 8 後會被解析稱為記憶體地址。如果 ebp
暫存器的值是100的話,那麼 eax 暫存器的值就是 100 + 8 的地址的值。dword ptr 也叫做 double word pointer 簡單解釋一下就是從指定的記憶體地址中讀出4位元組的資料
對棧進行 push 和 pop
程式執行時,會在記憶體上申請分配一個稱為棧的資料空間。棧(stack)的特性是後入先出,資料在儲存時是從記憶體的下層(大的地址編號)逐漸往上層(小的地址編號)累積,讀出時則是按照從上往下進行讀取的。
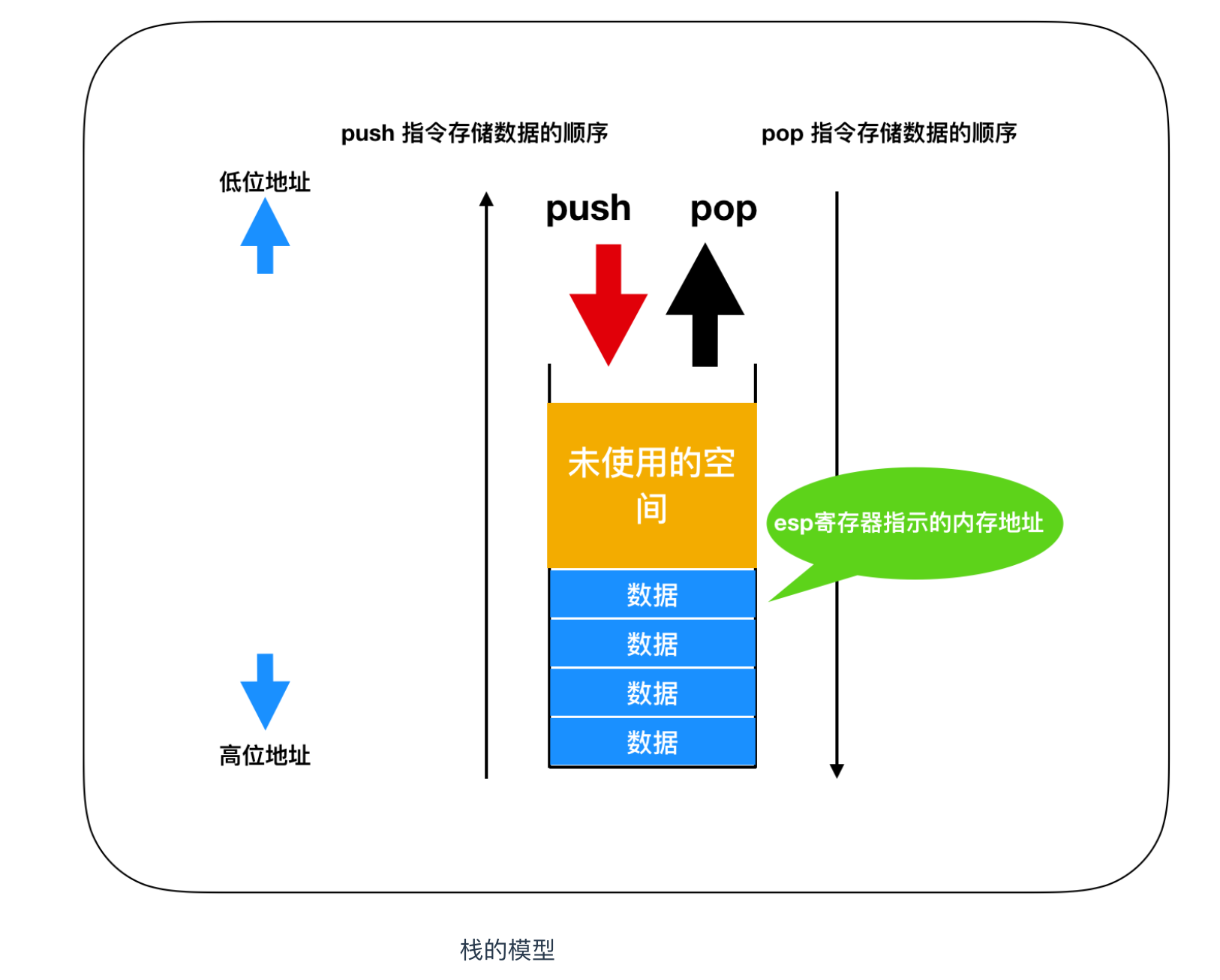
棧是儲存臨時資料的區域,它的特點是通過 push 指令和 pop 指令進行資料的儲存和讀出。向棧中儲存資料稱為 入棧 ,從棧中讀出資料稱為 出棧,32位 x86 系列的 CPU 中,進行1次 push 或者 pop,即可處理 32 位(4位元組)的資料。
函式的呼叫機制
下面我們一起來分析一下函式的呼叫機制,我們以上面的 C 語言編寫的程式碼為例。首先,讓我們從MyFunc 函式呼叫AddNum 函式的組合語言部分開始,來對函式的呼叫機制進行說明。棧在函式的呼叫中發揮了巨大的作用,下面是經過處理後的 MyFunc 函式的彙編處理內容
_MyFunc proc near
push ebp ; 將 ebp 暫存器的值存入棧中 (1)
mov ebp,esp ; 將 esp 暫存器的值存入 ebp 暫存器中 (2)
push 456 ; 將 456 入棧 (3)
push 123 ; 將 123 入棧 (4)
call _AddNum ; 呼叫 AddNum 函式 (5)
add esp,8 ; esp 暫存器的值 + 8 (6)
pop ebp ; 讀出棧中的數值存入 esp 暫存器中 (7)
ret ; 結束 MyFunc 函式,返回到呼叫源 (8)
_MyFunc endp程式碼解釋中的(1)、(2)、(7)、(8)的處理適用於 C 語言中的所有函式,我們會在後面展示 AddNum 函式處理內容時進行說明。這裡希望大家先關注(3) - (6) 這一部分,這對了解函式呼叫機制至關重要。
(3) 和 (4) 表示的是將傳遞給 AddNum 函式的引數通過 push 入棧。在 C 語言原始碼中,雖然記述為函式 AddNum(123,456),但入棧時則會先按照 456,123 這樣的順序。也就是位於後面的數值先入棧。這是 C 語言的規定。(5) 表示的 call 指令,會把程式流程跳轉到 AddNum 函式指令的地址處。在組合語言中,函式名表示的就是函式所在的記憶體地址。AddNum 函式處理完畢後,程式流程必須要返回到編號(6) 這一行。call 指令執行後,call 指令的下一行(也就指的是 (6) 這一行)的記憶體地址(呼叫函式完畢後要返回的記憶體地址)會自動的 push 入棧。該值會在 AddNum 函式處理的最後通過 ret 指令 pop 出棧,然後程式會返回到 (6) 這一行。
(6) 部分會把棧中儲存的兩個引數 (456 和 123) 進行銷燬處理。雖然通過兩次的 pop 指令也可以實現,不過採用 esp 暫存器 + 8 的方式會更有效率(處理 1 次即可)。對棧進行數值的輸入和輸出時,數值的單位是4位元組。因此,通過在負責棧地址管理的 esp 暫存器中加上4的2倍8,就可以達到和執行兩次 pop 命令同樣的效果。雖然記憶體中的資料實際上還殘留著,但只要把 esp 暫存器的值更新為資料儲存地址前面的資料位置,該資料也就相當於銷燬了。
我在編譯 Sample4.c 檔案時,出現了下圖的這條訊息

圖中的意思是指 c 的值在 MyFunc 定義了但是一直未被使用,這其實是一項編譯器優化的功能,由於儲存著 AddNum 函式返回值的變數 c 在後面沒有被用到,因此編譯器就認為 該變數沒有意義,進而也就沒有生成與之對應的組合語言程式碼。
下圖是呼叫 AddNum 這一函式前後棧記憶體的變化

函式的內部處理
上面我們用匯編程式碼分析了一下 Sample4.c 整個過程的程式碼,現在我們著重分析一下 AddNum 函式的原始碼部分,分析一下引數的接收、返回值和返回等機制
_AddNum proc near
push ebp -----------(1)
mov ebp,esp -----------(2)
mov eax,dword ptr[ebp+8] -----------(3)
add eax,dword ptr[ebp+12] -----------(4)
pop ebp -----------(5)
ret ----------------------------------(6)
_AddNum endpebp 暫存器的值在(1)中入棧,在(5)中出棧,這主要是為了把函式中用到的 ebp 暫存器的內容,恢復到函式呼叫前的狀態。
(2) 中把負責管理棧地址的 esp 暫存器的值賦值到了 ebp 暫存器中。這是因為,在 mov 指令中方括號內的引數,是不允許指定 esp 暫存器的。因此,這裡就採用了不直接通過 esp,而是用 ebp 暫存器來讀寫棧內容的方法。
(3) 使用[ebp + 8] 指定棧中儲存的第1個引數123,並將其讀出到 eax 暫存器中。像這樣,不使用 pop 指令,也可以參照棧的內容。而之所以從多個暫存器中選擇了 eax 暫存器,是因為 eax 是負責運算的累加暫存器。
通過(4) 的 add 指令,把當前 eax 暫存器的值同第2個引數相加後的結果儲存在 eax 暫存器中。[ebp + 12] 是用來指定第2個引數456的。在 C 語言中,函式的返回值必須通過 eax 暫存器返回,這也是規定。也就是 函式的引數是通過棧來傳遞,返回值是通過暫存器返回的。
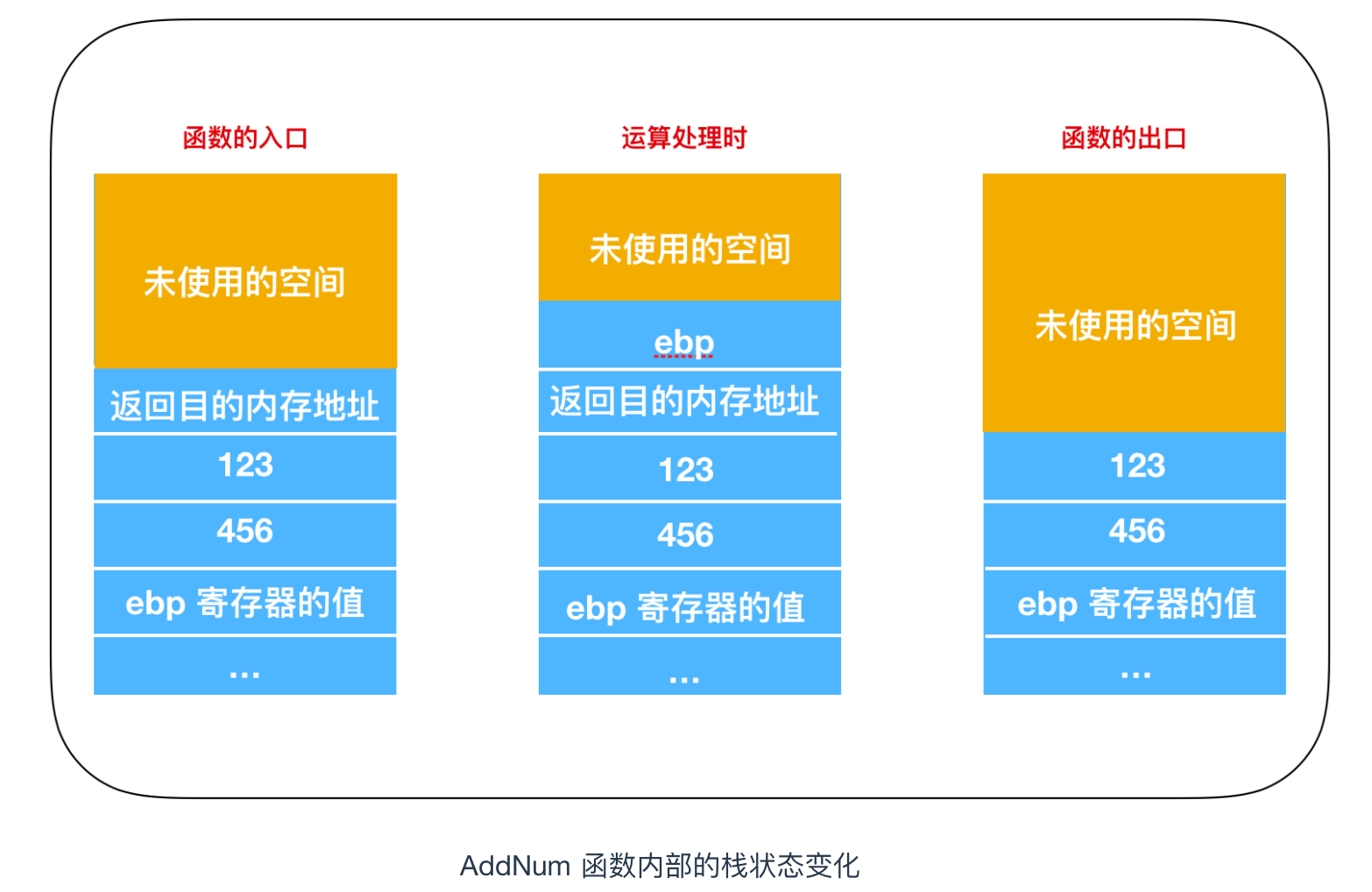
(6) 中 ret 指令執行後,函式返回目的地記憶體地址會自動出棧,據此,程式流程就會跳轉返回到(6) (Call _AddNum) 的下一行。這時,AddNum 函式入口和出口處棧的狀態變化,就如下圖所示
這是程式設計師需要了解的硬核知識之組合語言(一) 第一篇文章,下一篇文章我們會著重討論區域性變數和全域性變數以及迴圈控制語句的組合語言,防止斷更,請關注我

相關推薦
程式設計師需要了解的硬核知識之組合語言(一)
之前的系列文章從 CPU 和記憶體方面簡單介紹了一下組合語言,但是還沒有系統的瞭解一下組合語言,組合語言作為第二代計算機語言,會用一些容易理解和記憶的字母,單詞來代替一個特定的指令,作為高階程式語言的基礎,有必要系統的瞭解一下組合語言,那麼本篇文章希望大家跟我一起來了解一下組合語言。 組合語言和原生代碼 我們
程式設計師需要了解的硬核知識之CPU
大家都是程式設計師,大家都是和計算機打交道的程式設計師,大家都是和計算機中軟體硬體打交道的程式設計師,大家都是和CPU打交道的程式設計師,所以,不管你是玩兒硬體的還是做軟體的,你的世界都少不了計算機最核心的 - CPU CPU是什麼 CPU 的全稱是 Central Processing Unit,它是你的電
程式設計師需要了解的硬核知識之記憶體
我們都知道,計算機是處理資料的裝置,而資料的主要儲存位置就是磁碟和記憶體,並且對於程式設計師來講,CPU 和記憶體是我們必須瞭解的兩個物理結構,它是你通向高階程式設計師很重要的橋樑,那麼本篇文章我們就來介紹一下基本的記憶體知識。 什麼是記憶體 記憶體(Memory)是計算機中最重要的部件之一,它是程式與CPU
程式設計師需要了解的硬核知識之磁碟
此篇文章是 《程式設計師需要了解的硬核知識》系列第四篇,歷史文章請戳 程式設計師需要了解的硬核知識之記憶體 程式設計師需要了解的硬核知識之CPU 程式設計師需要了解的硬核知識之二進位制 我們大家知道,計算機的五大基礎部件是 儲存器、控制器、運算器、輸入和輸出裝置,其中從儲存功能的角度來看,可以把儲存器分為記憶
程式設計師需要了解的硬核知識之壓縮演算法
此篇文章是《程式設計師需要了解的硬核知識》第五篇文章,歷史文章請戳 程式設計師需要了解的硬核知識之記憶體 程式設計師需要了解的硬核知識之CPU 程式設計師需要了解的硬核知識之二進位制 程式設計師需要了解的硬核知識之磁碟 之前的文章更多的介紹了計算機的硬體知識,會有一些難度,本篇文章的門檻會低一些,一起來看一下
程式設計師需要了解的硬核知識之作業系統入門
對於程式設計師來說,最莫大的榮耀莫過於自己的軟體被大多數人使用了吧。 歷史文章請戳 程式設計師需要了解的硬核知識之記憶體 程式設計師需要了解的硬核知識之CPU 程式設計師需要了解的硬核知識之二進位制 程式設計師需要了解的硬核知識之磁碟 程式設計師需要了解的硬核知識之壓縮演算法 本篇文章作為作業系統的入門文章,
程式設計師需要了解的硬核知識之作業系統和應用
利用計算機執行程式大部分都是為了提高處理效率。例如,Microsoft Word 這樣的文書處理軟體,是用來提高文字檔案處理效率的程式,Microsoft Excel 等表格計算軟體,是用來提高賬本處理效率的程式。這種為了提高特定處理效率的程式統稱為 應用 程式設計師的工作就是編寫各種各樣的應用來提高工作效率
程式設計師需要了解的硬核知識之組合語言(全)
之前的系列文章從 CPU 和記憶體方面簡單介紹了一下組合語言,但是還沒有系統的瞭解一下組合語言,組合語言作為第二代計算機語言,會用一些容易理解和記憶的字母,單詞來代替一個特定的指令,作為高階程式語言的基礎,有必要系統的瞭解一下組合語言,那麼本篇文章希望大家跟我一起來了解一下組合語言。 組合語言和原生代碼 我們
程式設計師需要了解的硬核知識之控制硬體
應用和硬體的關係 我們作為程式設計師一般很少直接操控硬體,我們一般通過 C、Java 等高階語言編寫的程式起到間接控制硬體的作用。所以大家很少直接接觸到硬體的指令,硬體的控制是由 Windows 作業系統 全權負責的。 你一定猜到我要說什麼了,沒錯,我會說但是,任何事情沒有絕對性,環境的不同會造成結果的偏差。
程式設計師需要了解的硬核知識之二進位制
我們都知道,計算機的底層都是使用二進位制資料進行資料流傳輸的,那麼為什麼會使用二進位制表示計算機呢?或者說,什麼是二進位制數呢?在拓展一步,如何使用二進位制進行加減乘除?二進位制數如何表示負數呢?本文將一一為你揭曉。 ## 為什麼用二進位制表示 我們大家知道,計算機內部是由IC電子元件組成的,其中 `CP
每一個程式設計師需要了解的10個Linux命令
作為一個程式設計師,在軟體開發職業生涯中或多或少會用到Linux系統,並且可能會使用Linux命令來檢索需要的資訊。本文將為各位開發者分享10個有用的Linux命令,希望對你會有所幫助。 以下就是今天我們要介紹的Linux命令: man touch, cat an
Java程式設計師需要了解的兩種伺服器設計模型
我們在IO模型和Java網路程式設計模型中,對IO有了一定的理解。這一篇,主要講解基於事件驅動的兩種是在原來基礎上的擴充套件。在基於事件驅動的網路程式設計模型中,Reactor和Proactor模型是兩種常用的IO設計模型。 我們知道BIO(阻塞IO)只有等待阻塞方法結束了,操作權才會交還給呼叫
程式設計師不得不瞭解的硬核知識大全
我們每個程式設計師或許都有一個夢,那就是成為大牛,我們或許都沉浸在各種框架中,以為框架就是一切,以為應用層才是最重要的,你錯了。在當今計算機行業中,會應用是基本素質,如果你懂其原理才能讓你在行業中走的更遠,而計算機基礎知識又是重中之重。下面,跟隨我的腳步,為你介紹一下計算機底層知識。 CPU 還不瞭解 CPU
程式設計師需要了解依賴衝突的原因以及解決方案
0x00. 前言 依賴衝突是日常開發中經常碰到的過程,如果運氣好,並不會有什麼問題。偏偏小黑哥有點背,碰到好幾次生產問題,排查一整晚,最後發現卻是依賴衝突的引起的問題。 沒碰到過這個問題同學可能沒什麼感覺,小黑哥舉兩個最近碰到例子,讓大家感受一些。 例子 1: 我們公司有個古老的業務基礎包 A。B,C 業
你需要了解的HTTP知識都在這裏了!
gem agent pre 基本 語法 lan 重要 詳細 thead 前言 HTTP網絡通信協議在任何的開發工作中都起到非常重要的作用,今天,我們來講解下關於HTTP的相關知識。 目錄 5分鐘全面了解HTTP相關知識.png 計算機網絡相關知識 計算機網絡體
Android開發中需要了解的session知識
Cookie和Session都為了用來儲存狀態資訊,都是儲存客戶端狀態的機制,它們都是為了解決HTTP無狀態的問題而所做的努力 Session可以用Cookie來實現,也可以用URL回寫的機制來實現 Cookie和Session有以下明顯的不同點: 1)Cookie將狀態儲存
Java入門需要了解的一些知識
目錄 Java各版本的含義 Java的特性和優勢 Java應用程式的執行機制 JVM、JRE和JDK Java各版本的含義 JavaSE(Java Standard Edition):標準版,定位在個人計算
前端需要了解的http知識
一、五層協議1. OSI(Open System Interconnection 開放式系統互聯)七層協議 1)應用層 2)表示層 3)會話層 4)傳輸層 5)網路層 6)資料鏈接層 7)物理層2. TCP/IP四層網路協議 (Transmission Control Protocol 傳輸控制協議) 1)應
學資料結構的意義和需要了解的基礎知識
本人為初學者,此文為學習的一些總結,如有不當之處,還請多多包涵。 要說起學習資料結構的意義,不得不先說一下,CPU,記憶體,磁碟(硬碟或固態硬碟)。 首先,CPU中的儲存空間很小,基本可以忽略不計,(造價太貴),其次是記憶體(造價也很貴),再其次是磁碟(硬碟一般很大,因為造價最便宜)
需要了解的Smbios知識
什麼是Smbios Smbios(system management bios)是主機板或者系統製造廠商以標準格式顯示產品資訊所遵循的統一規範,Smbios規範標準定義了收集的電腦資訊都包含哪方面的資訊?其實就是包含很多c語言中的結構體,每一個結構體代表一種資訊。 每個主機板廠商或者