
redis入門(一)
目錄
- redis入門(一)
- 前言
- 特性
- 速度快
- 簡單穩定
- 豐富的功能
- 歷史
- 歷史版本
- 安裝與啟動
- 安裝
- 資料型別與內部編碼
- 資料結構
- 內部編碼
- 常用API與使用場景
- 常用命令
- 字串
- 列表
- 雜湊
- 集合
- 有序集合
- 總結
- 參考文件
redis入門(一)
前言
Redis是什麼?
redis是一種基於鍵值對(key-value)的NoSQL資料庫。Redis會將所有資料都存放在記憶體中,所以它的讀寫效能非常驚人。不僅如此,Redis還可以將記憶體的資料利用快照和日誌的形式儲存到硬碟上,這樣在發生類似斷電或者機器故障的時候,記憶體中的資料不會“丟失”。Redis還提供了鍵過期、釋出訂閱、事務、流水線、Lua指令碼等附加功能。- Redis能做什麼
在談為什麼需要redis之前,先要清楚redis可以做什麼。
- 快取。通過引入快取加快資料的訪問速度,降低後端資料來源的壓力。
- 排行榜。redis提供給列表和有序幾何資料結構可以很方便的構建各種排行榜系統。
- 計數器。redis原生支援高效能的計數功能,可以為視訊播放量、網頁瀏覽數等提供支援。
- 訊息佇列。redis提供釋出訂閱功能。
特性
我們為什麼選擇redis?
速度快
官方給出的讀寫速度可以達到10W/s,以下是我本機雙核四執行緒低壓i7上測試的對字串的讀寫速度。
C:\Users\Dm_ca> redis-benchmark -n 100000 -t set,get -q -a test1 SET: 11993.28 requests per second GET: 57603.69 requests per second
若使用redis管道技術可以得到更高的讀寫速度
C:\Users\Dm_ca> redis-benchmark -n 100000 -t set,get -q -a test1 -P 2
SET: 19466.62 requests per second
GET: 133155.80 requests per secondRedis 管道技術可以在服務端未響應時,客戶端可以繼續向服務端傳送請求,並最終一次性讀取所有服務端的響應。
下表是谷歌公司給出的各層級硬體執行速度,記憶體的響應速度是100ns,redis將資料全部從記憶體載入可以更快的讀寫資料。

簡單穩定
早期版本程式碼在2W行左右,3.0添加了叢集等特性增值5W行。相比其他NoSQL資料庫來說程式碼量少得多。
豐富的功能
支援釋出訂閱、持久化、叢集及管道等其他常用的功能。
歷史
2008年,Redis的作者Salvatore Sanfilippo在開發一個叫LLOOGG的網站時,需要實現一個高效能的佇列功能,最開始是使用MySQL來實現的,但後來發現無論怎麼優化SQL語句都不能使網站的效能提高上去,於是他決定自己做一個專屬於LLOOGG的資料庫,這個就是Redis的前身。後來,Salvatore Sanfilippo將Redis1.0的原始碼開放到GitHub上,可能連他自己都沒想到,Redis後來如此受歡迎。
歷史版本
Redis借鑑了Linux作業系統對於版本號的命名規則:版本號第二位如果是奇數,則為非穩定版本(例如2.7、2.9、3.1),如果是偶數,則為穩定版本(例如2.6、2.8、3.0、3.2)。當前奇數版本就是下一個穩定版本的開發版本。
- Redis 2.6
Redis 2.6在2012年正式釋出,經歷了17個版本,到 2.6.17版本,相比於Redis2.4,主要特性如下:- 服務端支援Lua指令碼。
- 從節點提供只讀功能。
- 重構了大量的核心程式碼,所有叢集相關的程式碼都去掉了,cluster功能將會是3.0版本最大的亮點。
- 其他若干修復與優化
- Redis 2.8
Redis2.8在2013年11月22日正式釋出,經歷了24個版本,到2.8.24版本,相比於Redis2.6,主要特性如下:- 新增部分主從複製的功能,在一定程度上降低了由於網路問題,造成頻繁全量複製生成RDB對系統造成的壓力。
- 可以通過
config set命令設定maxclients。 - 可以用bind命令繫結多個IP地址。
configre write命令可以將config set持久化到Redis配置檔案中。- 其他若干修復與優化
- Redis 3.0
- Redis Cluster:Redis的官方分散式實現。
- 全新的embedded string物件編碼結果,優化小物件記憶體訪問,在特定的工作負載下速度大幅提升。
config set設定maxmemory時候可以設定不同的單位單位(之前只能是位元組)- incr命令效能提升。
- 其他若干修復與優化
- Redis 3.2
- 新的List編碼型別:quicklist。
- 從節點讀取過期資料保證一致性。
- 新的RDB格式,但是仍然相容舊的RDB。
- 加速RDB的載入速度。
- 其他若干修復與優化
- Redis 4.0
- 提供了模組系統,方便第三方開發者拓展Redis的功能
- PSYNC2.0:優化了之前版本中,主從節點切換必然引起全量複製的問題。
- 提供了RDB-AOF混合持久化格式,充分利用了AOF和RDB各自優勢。
- Redis Cluster相容NAT和Docker。
- 其他若干修復與優化
更多細節可以檢視Redis版本歷史介紹
安裝與啟動
redis編譯後,有許多可執行檔案,我們先了解一下各個檔案的用途。在windows版本和官方redis版的檔案都是差不多的。
| 可執行檔案 | 作用 |
|---|---|
| redis-server | 啟動redis服務 |
| redis-cli | redis命令列客戶端 |
| redis-benchmark | redis基準測試工具 |
| redis-check-aof | redis AOF持久化檔案檢測和修復工具 |
| redis-check-dump | redis RDB持久化檔案檢測和修復工具 |
| redis-sentinel | 啟動redis哨兵服務 |
windows版本是沒有redis-sentinel,在啟動的時候可以通過
--sentinel引數以哨兵模式啟動。
安裝
windows版本
下載
Redis官方並不支援Windows作業系統,但是Redis作為一款優秀的開源技術吸引到了微軟的注意,微軟的開源技術組在GitHub上維護一個Redis的分支。
目前在windows版本最新的redis是3.2.100,可以到這裡下載下載的壓縮檔案內容如下圖所示。
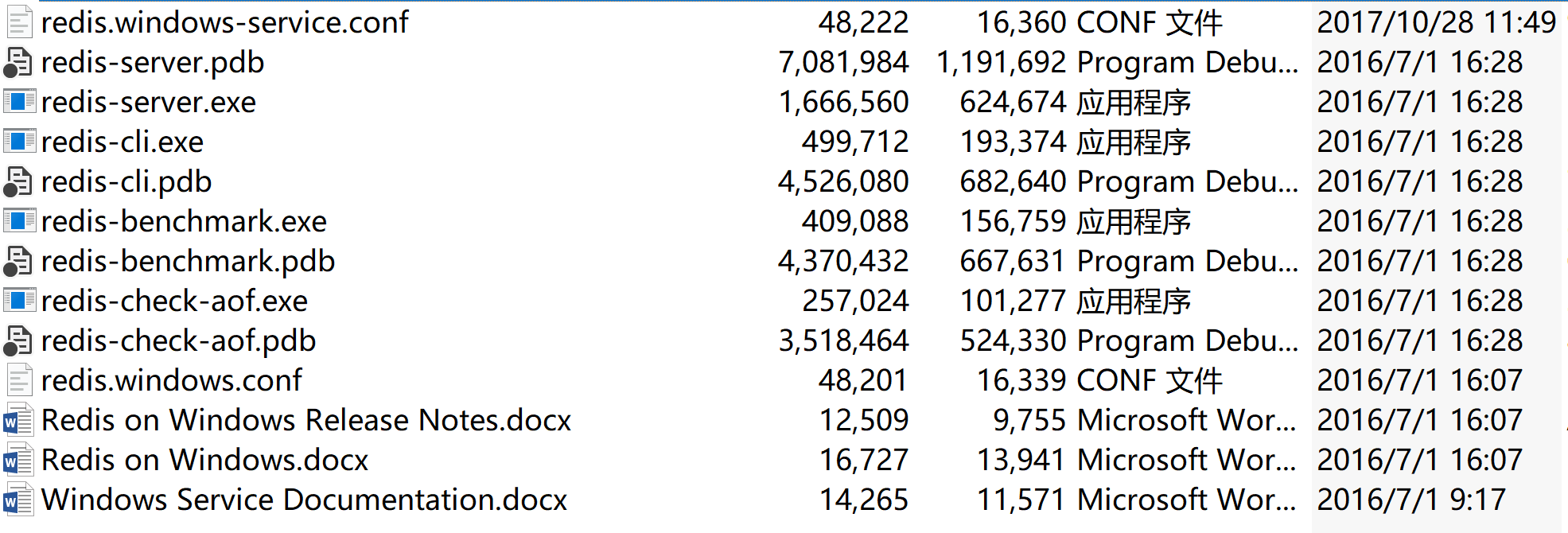
windows版本的redis可以以2種方式執行,一種是通過cmd命令框啟動redis服務程序。另一種是將redis安裝為windows服務,並以windows服務執行。
.config是redis配置檔案。在服務安裝的時候我們可以指定配置檔案,若沒有指定,則使用redis預設配置。直接啟動
通過
redis-server 配置名可以直接啟動redis服務。
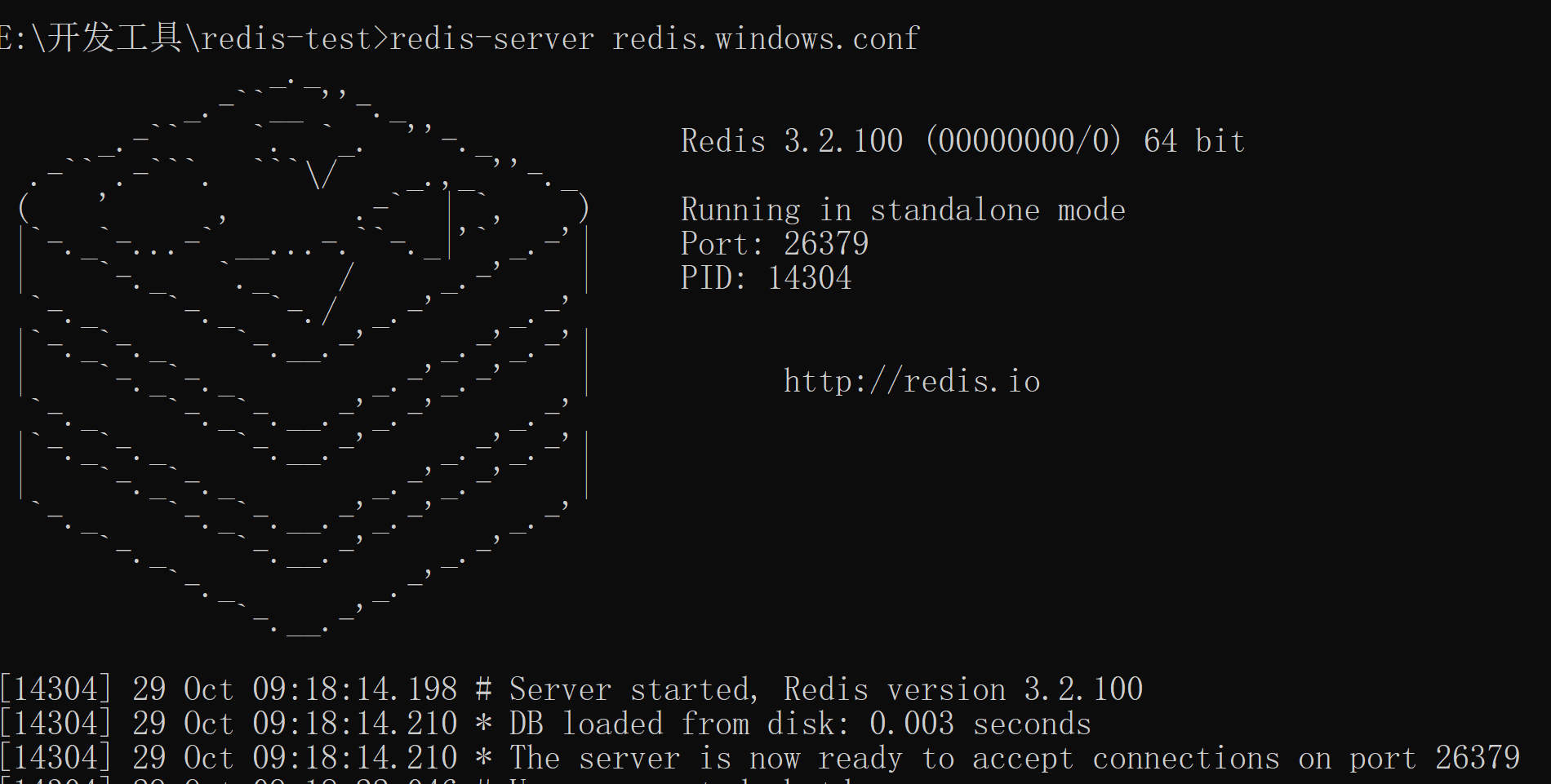
安裝服務
生產環境建議將redis安裝為windows服務,避免cmd框不小心被關掉。
開啟cmd視窗,通過redis-server --service-install 配置檔案路徑 --service-name 服務名安裝服務。如redis-server --service-install redis.windows-service.conf --service-name redis-test
若配置格式沒有問題,安裝成功後再windows服務中則會有名為redis-test的服務。安裝windows服務時必須指定配置檔案
若沒有指定服務名,則使用Redis作為預設的服務名稱。啟動服務
通過
redis-server --service-start --service-name 服務名啟動指定的redis服務。停止服務
通過
redis-server --service-stop --service-name 服務名停止指定的redis服務。解除安裝
通過
redis-server --service-install --service-name 服務名解除安裝Redis服務。解除安裝服務前需要先停止服務。
linux版本
下載
在Linux安裝軟體通常有兩種方法,第一種是通過各個作業系統的軟體管理軟體進行安裝,例如CentOS有yum管理工具,Ubuntu有 apt。但是由於Redis的更新速度相對較快,而這些管理工具不一定能更新到最新的版本,同時Redis的安裝本身不是很複雜,所以一推薦使用第二種方式:原始碼的方式進行安裝,整個安裝只需以下四步即可完成。
1) 下載Redis指定版本的原始碼壓縮包到當前目錄。
2) 解壓縮Redis原始碼壓縮包。
3) 編譯(編譯之前確保作業系統已經安裝gcc)。
4) 安裝。wget http://download.redis.io/releases/redis-5.0.5.tar.gz tar xzf redis-5.0.5.tar.gz cd redis-5.0.5 make編譯
我本機是在windows的Linux子系統上執行,安裝的是Ubuntu,windows商店中的ubuntu是最小化安裝,因此許多必要的開發包都是沒有的,比如
make,因此需要安裝make,而編譯redis原始碼還要依賴gcc,因此確保自己本地的linux已經安裝了gcc和make.在ubuntu下可以使用
sudo apt-get install build-essential安裝gcc相關的包,使用sudo apt-get install make安裝make包。
若都安裝完成,則可以在redis目錄下通過make命令進行原始碼編譯啟動
通過
src/redis-server啟動redis-server,通過src/redis-server 配置名以指定的配置檔案啟動。若直接啟動預設以前臺服務程序執行,將會阻塞命令列。修改配置檔案daemonize no改為daemonize yes以守護程序的方式執行。守護程序(Daemon Process),也就是通常說的 Daemon 程序(精靈程序),是 Linux 中的後臺服務程序。它是一個生存期較長的程序,通常獨立於控制終端並且週期性地執行某種任務或等待處理某些發生的事件。
可以通過修改配置檔案中的port修改繫結指定埠客戶端連線
通過
src/redis-cli連線redis服務,通過src/redis-server -v或src/redis-cli -v可以檢視redis的版本號。
資料型別與內部編碼
資料結構
redis可以儲存string(字串)、hash(雜湊)、list(列表)、set(集合)、zset(有序集合)。在後面的版本逐步又添加了Bitmaps(點陣圖)、HyperLogLog、GEO(地理資訊定位)等資料結構。
通過type命令可以檢視當前鍵的資料型別。
127.0.0.1:26379> type key1
string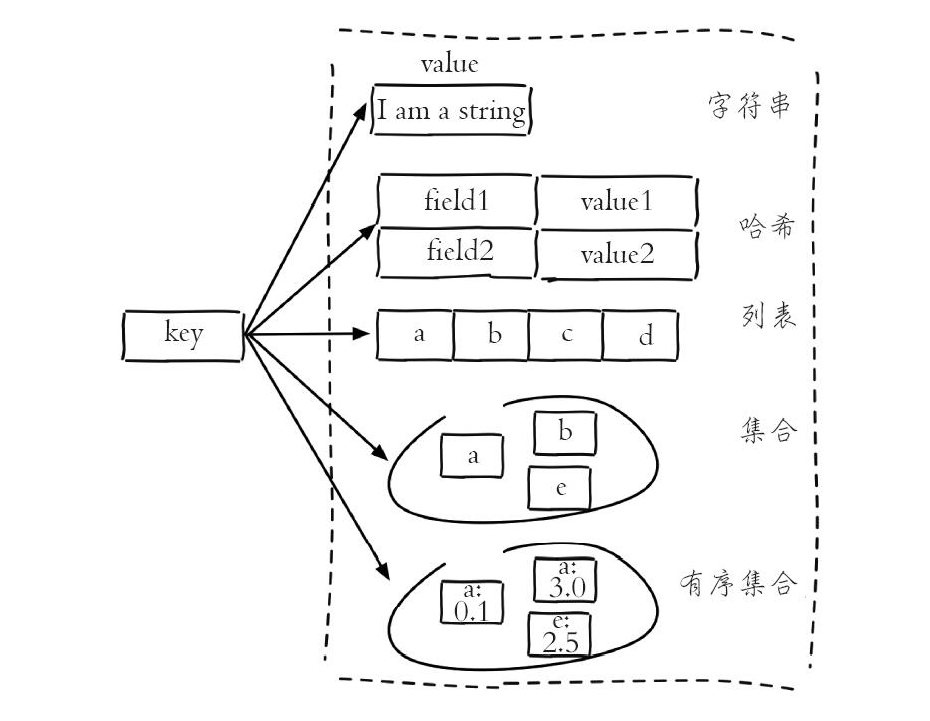
內部編碼
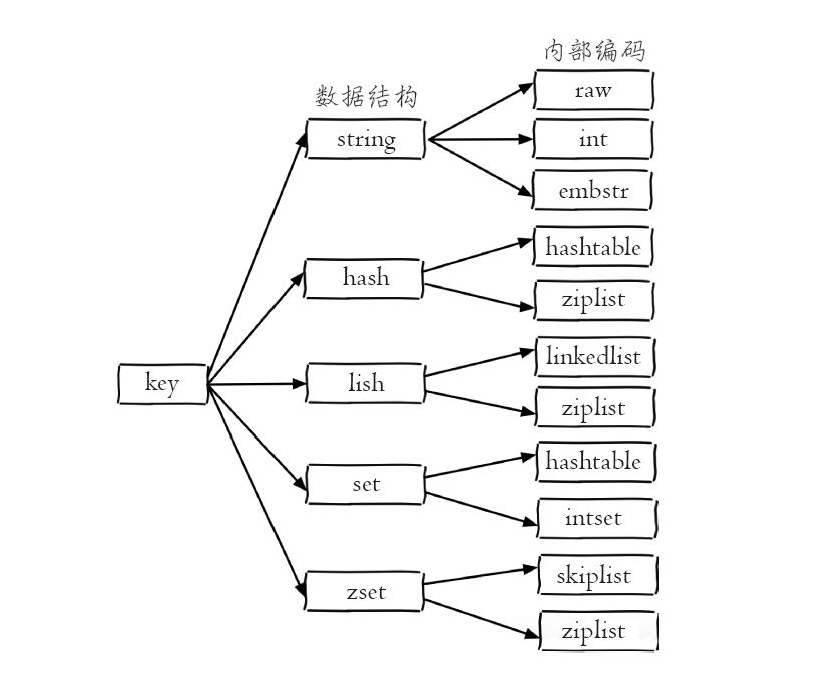
通過type返回的僅僅是對外的資料結構,實際上每種資料結構都有自己底層的內部編碼實現,而且是多種實現。
redis通過構建簡單動態字串、連結串列、壓縮列表、整數集合、雜湊表(字典)、跳躍表等內部編碼構造出進行組合實現了各種資料結構,通過這種方式 ,Redis會在合適的場景選擇合適的內部編碼。從而優化不同場景下的使用效率。
如果一個字串物件儲存的是整數值,並且這個整數值可以用long型別來表示,需要注意的是long或double型別表示的浮點數在Redis中也是作為字串值來儲存的。如果我們要儲存一個浮點數到字串物件裡面,那麼程式會先將這個浮點數轉換成字串值,然後再儲存轉換所得的字串值。
embstr編碼是專門用於儲存短字串的一種優化編碼方式,embstr編碼通過呼叫一次記憶體分配函式來分配一塊連續的空間,而raw編碼會呼叫兩次記憶體分配函式。同理釋放embstr編碼的字串只需要呼叫一次記憶體釋放函式來分配一塊連續的空間,而釋放raw編碼的字串會呼叫兩次記憶體釋放函式。
embstr編碼的字串物件實際上是隻讀的。當我們對embstr編碼的字串物件執行任何修改命令時,程式會先將物件的編碼從embstr轉換成raw,然後再執行修改命令。因為這個原因,embstr編碼的字串物件在執行修改命令之後,總會變成一個raw編碼的字串物件。
- Redis的字典使用雜湊表作為底層實現,一個雜湊表裡面可以有多個雜湊表節點,而每個雜湊表節點就儲存了字典中的一個鍵值對。
- 壓縮列表是Redis為了節約記憶體而開發的,是由一系列特殊編碼的連續記憶體塊組成的順序型(sequential)資料結構。一個壓縮列表可以包含任意多個節點(entry),每個節點可以儲存一個位元組陣列或者一個整數值。
- 連結串列提供了高效的節點重排能力,以及順序性的節點訪問方式,並且可以通過增刪節點來靈活地調整連結串列的長度。
- 整數集合(intset)是Redis用於儲存整數值的集合抽象資料結構,它可以儲存型別為int16_t、int32_t或者int64_t的整數值,並且保證集合中不會出現重複元素。
跳躍表(skiplist)是一種有序資料結構,它通過在每個節點中維持多個指向其他節點的指標,從而達到快速訪問節點的目的。
常用API與使用場景
常用命令
檢視所有鍵:
keys *127.0.0.1:26379> set key1 1 OK 127.0.0.1:26379> set key2 2 OK 127.0.0.1:26379> set key3 3 OK 127.0.0.1:26379> set key22 22 OK 127.0.0.1:26379> keys * 1) "key22" 2) "key3" 2) "key2" 3) "key1"該命令還支援模糊查詢
shell 127.0.0.1:26379> keys *2* 1) "key22" 2) "key2"鍵總數:
dbsize127.0.0.1:26379> dbsize (integer) 3檢查鍵是否存在:
exists key,可以傳入多個key,返回存在key的個數127.0.0.1:26379> exists key1 (integer) 1 127.0.0.1:26379> exists key4 (integer) 0 127.0.0.1:26379> exists key1 key2 (integer) 2刪除鍵:
del key,可以同時刪除多個key,返回成功刪除key的數量127.0.0.1:26379> del key1 key2 (integer) 2鍵過期:
expire key seconds127.0.0.1:26379> expire key3 2 (integer) 1查詢鍵剩餘過期時間:
ttl key。大於等於0則是鍵剩餘的過期時間,-1表示未設定過期時間。127.0.0.1:26379> ttl key3 (integer) 2 127.0.0.1:26379> ttl key1 (integer) -1查詢redis服務狀態:
info [section]。可以通過info查詢redis所有資訊,或者通過info section查詢指定的部分資訊。127.0.0.1:26379> info # Server redis_version:5.0.6 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:6f31570182dc95d9 redis_mode:standalone ... # Keyspace db0:keys=3,expires=0,avg_ttl=0 127.0.0.1:26379> info keyspace # Keyspace db0:keys=3,expires=0,avg_ttl=
字串
字串型別是Redis最基礎的資料結構。首先鍵都是字串型別,而且其他幾種資料結構都是在字串型別基礎上構建的,所以字串型別能為其他四種資料結構的學習奠定基礎。字串型別的值實際可以是字串(簡單的字串、複雜的字串(例如JSON、XML))、數字(整數、浮點數),甚至是二進位制(圖片、音訊、視訊),但是值最大不能超過512MB。
常用API
- 設定鍵
set key value [ex seconds] [px milliseconds] [nx| xx]- ex seconds:為鍵設定秒級過期時間。
- px milliseconds:為鍵設定毫秒級過期時間。
- nx:鍵必須不存在,才可以設定成功,用於新增。
- xx:與nx相反,鍵必須存在,才可以設定成功,用於更新。
由於nx和xx的特性,只有一個客戶端能設定成功,因此可以做為分散式鎖的一種實現。
- 讀取鍵:
get key - 批量設定:
mset key value [key value ...] - 批量讀取:
mget key [key ...]
內部編碼
字串型別的內部編碼有3種:
- int:8個位元組的長整型。
- embstr:小於等於44個位元組的字串。
raw:大於44個位元組的字串。
redis3.0以前是以39個字元為邊界,由於redis3.0對embstr效能做了優化導致長度邊界發生變化。詳情可以看Redis的embstr與raw編碼方式不再以39位元組為界了!
使用場景
快取
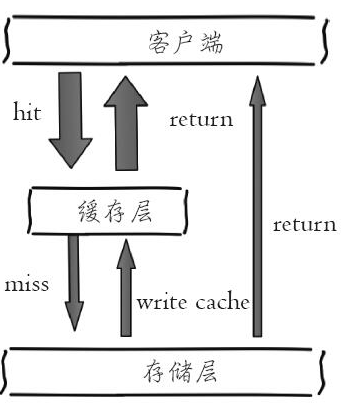
與關係型資料庫不同的是,Redis沒有命令空間,而且也沒有對鍵名有強制要求(除了不能使用一些特殊字元)。但設計合理的鍵名,有利於防止鍵衝突和專案的可維護性,比較推薦的方式是使用
業務名:物件名:id:[屬性]作為鍵名(也可以不是分號)。例如資料庫名為vs,使用者表名為user,那麼對應的鍵可以用vs:user:1,vs:user:1:name來表示,如果當前Redis只被一個業務使用,甚至可以去掉vs:。如果鍵名比較長,例如user:{uid}:friends:messages:{mid},可以在能描述鍵含義的前提下適當減少鍵的長度,例如變為u:{uid}:fr:m:{mid},從而減少由於鍵過長的記憶體浪費。計數
通過
incr key對計數進行累加,可用於播放量,訪問量等場景。限速
通過set 和 incr組合使用實現1分鐘內最多傳送5條簡訊。
127.0.0.1:26379> set 182XXXXXXXX 1 ex 60 nx OK 127.0.0.1:26379> set 182XXXXXXXX 1 ex 60 nx (nil) 127.0.0.1:26379> incr 182XXXXXXXX (integer) 2可以看到通過nx引數只有在不存在的時候才會設定成功。
分散式鎖
可以通過set加nx或xx引數實現分散式鎖。關於Redis實現分散式鎖可以參考Distributed locks with Redis
列表
列表(list)型別是用來儲存多個有序的字串,一個列表最多可以儲存2^32^-1個元素。在Redis中,可以對列表兩端插入(push)和彈出(pop),還可以獲取指定範圍的元素列表、獲取指定索引下標的元素等。列表是有序的,且可以插入重複資料。
常用API
- 從右邊插入資料:
rpush key value [value ...] - 從左邊插入資料:
lpush key value [value ...] - 從右邊彈出資料:
rpop key - 從左邊彈入資料:
lpop key - 從左側阻塞彈出:
blpop key [key ...] timeout 從右側阻塞彈出:
brpop key [key ...] timeout當使用阻塞彈出時,若列表為空,則將會阻塞指定的時間,若傳遞的timeout為0,會一致阻塞;若個客戶端同時阻塞時,有資料插入列表時,先阻塞的先可以獲取到值。
- 獲取指定範圍內的元素列表:
lrange key start end - 獲取列表指定索引下標的元素:
lindex key index - 獲取列表長度:
llen key 修改指定索引下標的元素:
lset key index newValue
內部編碼
列表型別的內部編碼有兩種:
- ziplist(壓縮列表):當列表的元素個數小於
list-max-ziplist-entries配置(預設512個),同時列表中每個元素的值都小於list-max-ziplist-value配置時(預設64位元組),Redis會選用ziplist來作為列表的內部實現來減少記憶體的使用。 linkedlist(連結串列):當列表型別無法滿足ziplist的條件時,Redis會使用linkedlist作為列表的內部實現。
Redis3.2版本提供了quicklist內部編碼,簡單地說它是以一個ziplist為節點的linkedlist,它結合了ziplist和linkedlist兩者的優勢,為列表型別提供了一種更為優秀的內部編碼實現
使用場景
- 訊息佇列
Redis的lpush+brpop命令組合即可實現阻塞佇列,生產者客戶端使用lrpush從列表左側插入元素,多個消費者客戶端使用brpop命令阻塞式的“搶”列表尾部的元素,多個客戶端保證了消費的負載均衡和高可用性。
- lpush+lpop=Stack(棧)
- lpush+rpop=Queue(佇列)
- lpsh+ltrim=CappedCollection(有限集合)
- lpush+brpop=MessageQueue(訊息佇列)
雜湊
在Redis中,雜湊型別是指鍵值本身又是一個鍵值對結構,形如value={{field1,value1},...{fieldN,valueN}}。
常用API
- 設定值:
hset key field value - 獲取指定鍵的field值:
hget key field - 刪除指定鍵的field:
hdel key field [field ...] - 計算指定鍵的field的個數:
hlen key - 批量獲取:
hmget key field [field ...] - 批量設定:
hmset key field value [field value ...] - 判斷field是否存在:
hexists key field - 獲取指定鍵的所有內容:
hexists key field
內部編碼
雜湊型別的內部編碼有兩種:
- ziplist(壓縮列表):當雜湊型別元素個數小於
hash-max-ziplist-entries配置(預設512個)、同時所有值都小於hash-max-ziplist-value配置(預設64位元組)時,Redis會使用ziplist作為雜湊的內部實現,ziplist使用更加緊湊的結構實現多個元素的連續儲存,所以在節省記憶體方面比hashtable更加優秀。 - hashtable(雜湊表):當雜湊型別無法滿足ziplist的條件時,Redis會使用hashtable作為雜湊的內部實現,因為此時ziplist的讀寫效率會下降,而hashtable的讀寫時間複雜度為O(1)。
使用場景
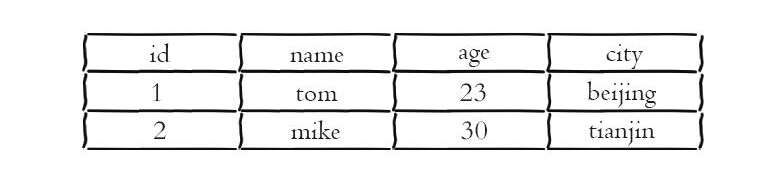
快取關係型資料庫的使用者資訊
關係型資料庫儲存方式
hash型別儲存方式
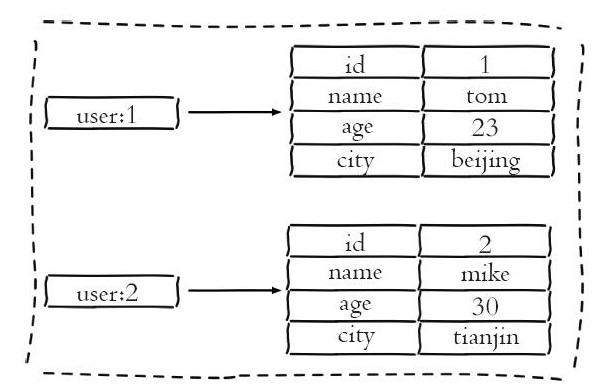
需要注意的是,關係型資料庫是結構化的,每一列都要為其設定值(即使未空也可能包括NULL或特殊的標識表示NULL),而NOSQL則是稀疏的,有欄位的才需要設定值。因此關係型資料庫需要佔用更大的記憶體空間。
Redis不適合去模擬複雜的查詢關係。- 儲存關係型資料的常用方式。
- 每個記錄每條屬性一個鍵。
- 優點:簡單直觀,每個屬性都可以更新,互不影響。
- 缺點:佔用了太多的key。查詢一個使用者的資訊比較麻煩,要獲取n次key。
- 將使用者序列化後儲存到一個鍵中。
- 優點:合理的序列化提高redis記憶體使用效率。
- 缺點:序列化和反序列化有一定的開銷。同時每次更新一個屬性都需要獲取全部資料反序列化更新後再重新序列化儲存到redis。
- 每個使用者欄位用對應一個field-value。
- 優點:簡單直觀,合理使用可以減少redis記憶體使用。每個屬性互不影響。
- 缺點:要控制hash的內部編碼轉換,若使用hashtable,會消耗更多記憶體。
- 每個記錄每條屬性一個鍵。
集合
集合(set)型別也是用來儲存多個的字串元素,但和列表型別不一樣的是,集合中不允許有重複元素,並且集合中的元素是無序的,不能通過索引下標獲取元素。
常用API
- 新增元素:
sadd key element [element ...] 刪除元素:
srem key element [element ...]新增和刪除可以對多個元素進行操作,返回的是執行成功的數量。
- 計算元素個數:
scard key - 計算指定鍵的field的個數:
hlen key - 判斷元素是否在集合中:
sismember key element 還有一些集合的操作這裡不做具體講解
內部編碼
集合型別的內部編碼有兩種:
- intset(整數集合):當集合中的元素都是整數且元素個數小於
set-max-intset-entries配置(預設512個)時,Redis會選用intset來作為集合的內部實現,從而減少記憶體的使用。 - hashtable(雜湊表):當集合型別無法滿足intset的條件時,Redis會使用hashtable作為集合的內部實現。
使用場景
儲存去重後的使用者資訊,比如IP白名單等
有序集合
有序集合它保留了集合不能有重複成員的特性,但不同的是,有序集合中的元素可以排序。但是它和列表使用索引下標作為排序依據不同的是,它給每個元素設定一個分數(score)作為排序的依據。有序集合提供了獲取指定分數和元素範圍查詢、計算成員排名等功能,合理的利用有序集合,能幫助我們在實際開發中解決很多問題。
常用API
有序集合在集合基礎上多了一個分值,並通過分支排序。
- 新增成員:
zadd key score member [score member ...]。Redis3.2為zadd命令添加了nx、xx、ch、incr四個選項:- nx:member必須不存在,才可以設定成功,用於新增。
- xx:member必須存在,才可以設定成功,用於更新。
- ch:返回此次操作後,有序集合元素和分數發生變化的個數。
- incr:對score做增加,相當於後面介紹的zincrby。
- 計算成員個數:
zcard key - 計算 某個 成員 的 分數 zscore key member
- 計算 成員 的 排名 zrank key member zrevrank key member
- zrank是從分數從低到高返回排名。
- zrevrank是從分數從高到低返回排名。
- 刪除成員:
zrem key member [member ...] - 增加成員的分數:
zincrby key increment member - 返回指定排名範圍的成員:
zrange key start end [withscores]或zrevrange key start end [withscores] - 返回指定分數範圍的成員:
zrangebyscore key min max [withscores] [limit offset count]或zrevrangebyscore key max min [withscores] [limit offset count] - 返回指定分數範圍成員個數:
zcount key min max - 刪除指定排名內的升序元素:
zremrangebyrank key start end - 刪除指定分數範圍的成員:
zremrangebyscore key min max
內部編碼
有序集合型別的內部編碼有兩種:
- ziplist(壓縮列表):當有序集合的元素個數小於
zset-max-ziplist-entries配置(預設128個),同時每個元素的值都小於zset-max-ziplist-value配置(預設64位元組)時,Redis會用ziplist來作為有序集合的內部實現,ziplist可以有效減少記憶體的使用。 - skiplist(跳躍表):當ziplist條件不滿足時,有序集合會使用skiplist作為內部實現,因為此時ziplist的讀寫效率會下降。
使用場景
根據某個資訊排序,比如一些排行榜功能,外賣的根據距離或綜合評分排序等。
總結
本節簡單介紹了redis歷史。同時介紹了redis的安裝部署的相關知識,最後介紹了開發常用的一些API和使用場景。
參考文件
- redis
- redis開發與運維
- Redis版本歷史介紹
- redis配置檔案詳解
- linux下/var/run目錄下.pid檔案的作用
- Redis的embstr與raw編碼方式不再以39位元組為界了
- Distributed locks with Redis
本文地址:https://www.cnblogs.com/Jack-Blog/p/11776146.html
作者部落格:傑哥很忙
歡迎轉載,請在明顯位置給出出處及連結