
分散式日誌收集系統 —— Flume
一、Flume簡介
Apache Flume 是一個分散式,高可用的資料收集系統。它可以從不同的資料來源收集資料,經過聚合後傳送到儲存系統中,通常用於日誌資料的收集。Flume 分為 NG 和 OG (1.0 之前) 兩個版本,NG 在 OG 的基礎上進行了完全的重構,是目前使用最為廣泛的版本。下面的介紹均以 NG 為基礎。
二、Flume架構和基本概念
下圖為 Flume 的基本架構圖:
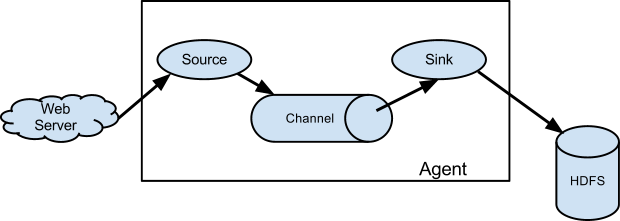
2.1 基本架構
外部資料來源以特定格式向 Flume 傳送 events (事件),當 source 接收到 events 時,它將其儲存到一個或多個 channel,channe 會一直儲存 events
sink 所消費。sink 的主要功能從 channel 中讀取 events,並將其存入外部儲存系統或轉發到下一個 source,成功後再從 channel 中移除 events。
2.2 基本概念
1. Event
Evnet 是 Flume NG 資料傳輸的基本單元。類似於 JMS 和訊息系統中的訊息。一個 Evnet 由標題和正文組成:前者是鍵/值對映,後者是任意位元組陣列。
2. Source
資料收集元件,從外部資料來源收集資料,並存儲到 Channel 中。
3. Channel
Channel 是源和接收器之間的管道,用於臨時儲存資料。可以是記憶體或持久化的檔案系統:
Memory Channel: 使用記憶體,優點是速度快,但資料可能會丟失 (如突然宕機);File Channel: 使用持久化的檔案系統,優點是能保證資料不丟失,但是速度慢。
4. Sink
Sink 的主要功能從 Channel 中讀取 Evnet,並將其存入外部儲存系統或將其轉發到下一個 Source,成功後再從 Channel 中移除 Event。
5. Agent
是一個獨立的 (JVM) 程序,包含 Source、 Channel、 Sink 等元件。
2.3 元件種類
Flume 中的每一個元件都提供了豐富的型別,適用於不同場景:
Source 型別 :內建了幾十種類型,如
Avro Source,Thrift Source,Kafka Source,JMS Source;Sink 型別 :
HDFS Sink,Hive Sink,HBaseSinks,Avro Sink等;Channel 型別 :
Memory Channel,JDBC Channel,Kafka Channel,File Channel等。
對於 Flume 的使用,除非有特別的需求,否則通過組合內建的各種型別的 Source,Sink 和 Channel 就能滿足大多數的需求。在 Flume 官網 上對所有型別元件的配置引數均以表格的方式做了詳盡的介紹,並附有配置樣例;同時不同版本的引數可能略有所不同,所以使用時建議選取官網對應版本的 User Guide 作為主要參考資料。
三、Flume架構模式
Flume 支援多種架構模式,分別介紹如下
3.1 multi-agent flow

Flume 支援跨越多個 Agent 的資料傳遞,這要求前一個 Agent 的 Sink 和下一個 Agent 的 Source 都必須是 Avro 型別,Sink 指向 Source 所在主機名 (或 IP 地址) 和埠(詳細配置見下文案例三)。
3.2 Consolidation
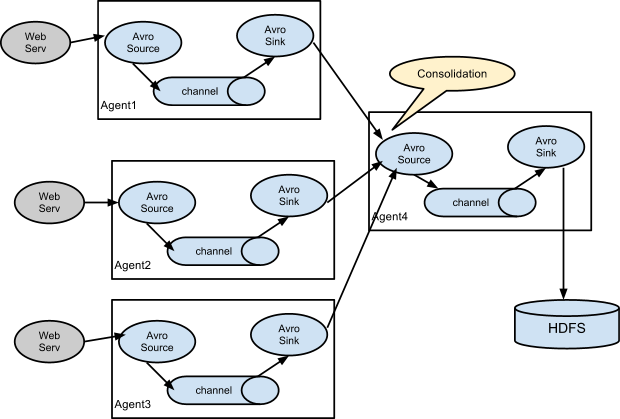
日誌收集中常常存在大量的客戶端(比如分散式 web 服務),Flume 支援使用多個 Agent 分別收集日誌,然後通過一個或者多個 Agent 聚合後再儲存到檔案系統中。
3.3 Multiplexing the flow
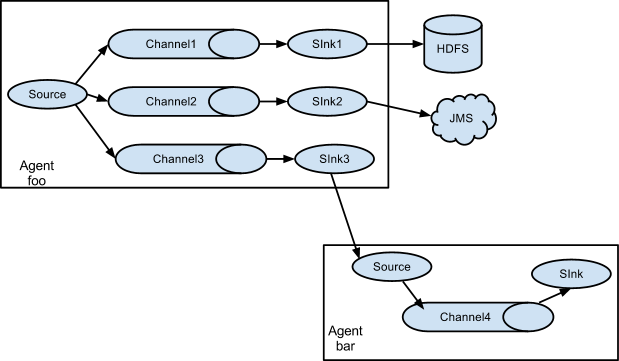
Flume 支援從一個 Source 向多個 Channel,也就是向多個 Sink 傳遞事件,這個操作稱之為 Fan Out(扇出)。預設情況下 Fan Out 是向所有的 Channel 複製 Event,即所有 Channel 收到的資料都是相同的。同時 Flume 也支援在 Source 上自定義一個複用選擇器 (multiplexing selector) 來實現自定義的路由規則。
四、Flume配置格式
Flume 配置通常需要以下兩個步驟:
- 分別定義好 Agent 的 Sources,Sinks,Channels,然後將 Sources 和 Sinks 與通道進行繫結。需要注意的是一個 Source 可以配置多個 Channel,但一個 Sink 只能配置一個 Channel。基本格式如下:
<Agent>.sources = <Source>
<Agent>.sinks = <Sink>
<Agent>.channels = <Channel1> <Channel2>
# set channel for source
<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...
# set channel for sink
<Agent>.sinks.<Sink>.channel = <Channel1>- 分別定義 Source,Sink,Channel 的具體屬性。基本格式如下:
<Agent>.sources.<Source>.<someProperty> = <someValue>
# properties for channels
<Agent>.channel.<Channel>.<someProperty> = <someValue>
# properties for sinks
<Agent>.sources.<Sink>.<someProperty> = <someValue>五、Flume的安裝部署
為方便大家後期查閱,本倉庫中所有軟體的安裝均單獨成篇,Flume 的安裝見:
Linux 環境下 Flume 的安裝部署
六、Flume使用案例
介紹幾個 Flume 的使用案例:
- 案例一:使用 Flume 監聽檔案內容變動,將新增加的內容輸出到控制檯。
- 案例二:使用 Flume 監聽指定目錄,將目錄下新增加的檔案儲存到 HDFS。
- 案例三:使用 Avro 將本伺服器收集到的日誌資料傳送到另外一臺伺服器。
6.1 案例一
需求: 監聽檔案內容變動,將新增加的內容輸出到控制檯。
實現: 主要使用 Exec Source 配合 tail 命令實現。
1. 配置
新建配置檔案 exec-memory-logger.properties,其內容如下:
#指定agent的sources,sinks,channels
a1.sources = s1
a1.sinks = k1
a1.channels = c1
#配置sources屬性
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /tmp/log.txt
a1.sources.s1.shell = /bin/bash -c
#將sources與channels進行繫結
a1.sources.s1.channels = c1
#配置sink
a1.sinks.k1.type = logger
#將sinks與channels進行繫結
a1.sinks.k1.channel = c1
#配置channel型別
a1.channels.c1.type = memory2. 啟動
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/exec-memory-logger.properties \
--name a1 \
-Dflume.root.logger=INFO,console3. 測試
向檔案中追加資料:

控制檯的顯示:

6.2 案例二
需求: 監聽指定目錄,將目錄下新增加的檔案儲存到 HDFS。
實現:使用 Spooling Directory Source 和 HDFS Sink。
1. 配置
#指定agent的sources,sinks,channels
a1.sources = s1
a1.sinks = k1
a1.channels = c1
#配置sources屬性
a1.sources.s1.type =spooldir
a1.sources.s1.spoolDir =/tmp/logs
a1.sources.s1.basenameHeader = true
a1.sources.s1.basenameHeaderKey = fileName
#將sources與channels進行繫結
a1.sources.s1.channels =c1
#配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H/
a1.sinks.k1.hdfs.filePrefix = %{fileName}
#生成的檔案型別,預設是Sequencefile,可用DataStream,則為普通文字
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#將sinks與channels進行繫結
a1.sinks.k1.channel = c1
#配置channel型別
a1.channels.c1.type = memory2. 啟動
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/spooling-memory-hdfs.properties \
--name a1 -Dflume.root.logger=INFO,console3. 測試
拷貝任意檔案到監聽目錄下,可以從日誌看到檔案上傳到 HDFS 的路徑:
# cp log.txt logs/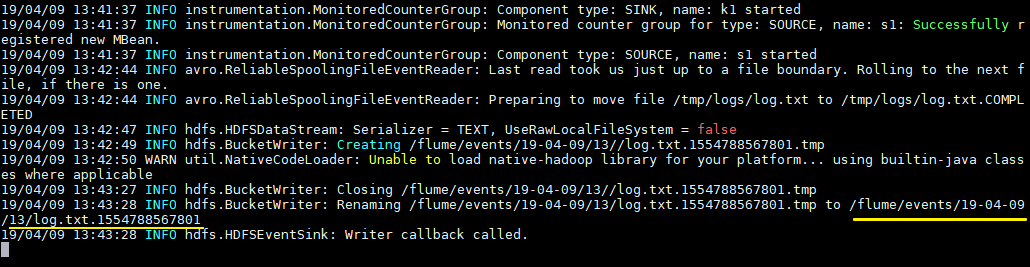
檢視上傳到 HDFS 上的檔案內容與本地是否一致:
# hdfs dfs -cat /flume/events/19-04-09/13/log.txt.1554788567801
6.3 案例三
需求: 將本伺服器收集到的資料傳送到另外一臺伺服器。
實現:使用 avro sources 和 avro Sink 實現。
1. 配置日誌收集Flume
新建配置 netcat-memory-avro.properties,監聽檔案內容變化,然後將新的檔案內容通過 avro sink 傳送到 hadoop001 這臺伺服器的 8888 埠:
#指定agent的sources,sinks,channels
a1.sources = s1
a1.sinks = k1
a1.channels = c1
#配置sources屬性
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /tmp/log.txt
a1.sources.s1.shell = /bin/bash -c
a1.sources.s1.channels = c1
#配置sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop001
a1.sinks.k1.port = 8888
a1.sinks.k1.batch-size = 1
a1.sinks.k1.channel = c1
#配置channel型別
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1002. 配置日誌聚合Flume
使用 avro source 監聽 hadoop001 伺服器的 8888 埠,將獲取到內容輸出到控制檯:
#指定agent的sources,sinks,channels
a2.sources = s2
a2.sinks = k2
a2.channels = c2
#配置sources屬性
a2.sources.s2.type = avro
a2.sources.s2.bind = hadoop001
a2.sources.s2.port = 8888
#將sources與channels進行繫結
a2.sources.s2.channels = c2
#配置sink
a2.sinks.k2.type = logger
#將sinks與channels進行繫結
a2.sinks.k2.channel = c2
#配置channel型別
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 1003. 啟動
啟動日誌聚集 Flume:
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/avro-memory-logger.properties \
--name a2 -Dflume.root.logger=INFO,console在啟動日誌收集 Flume:
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/netcat-memory-avro.properties \
--name a1 -Dflume.root.logger=INFO,console這裡建議按以上順序啟動,原因是 avro.source 會先與埠進行繫結,這樣 avro sink 連線時才不會報無法連線的異常。但是即使不按順序啟動也是沒關係的,sink 會一直重試,直至建立好連線。
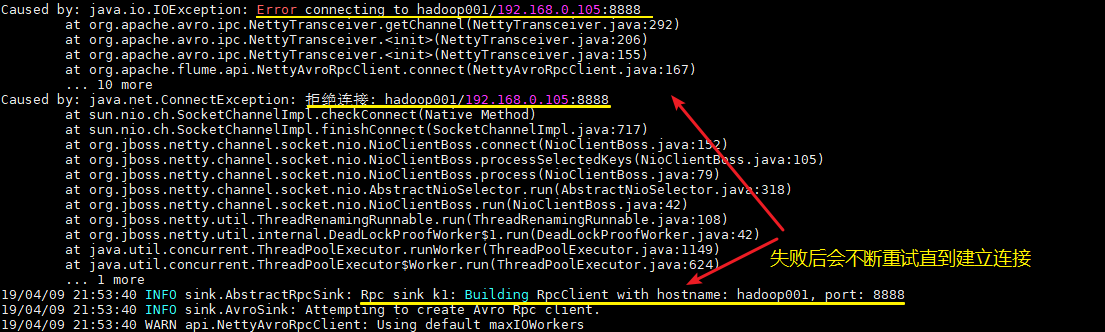
4.測試
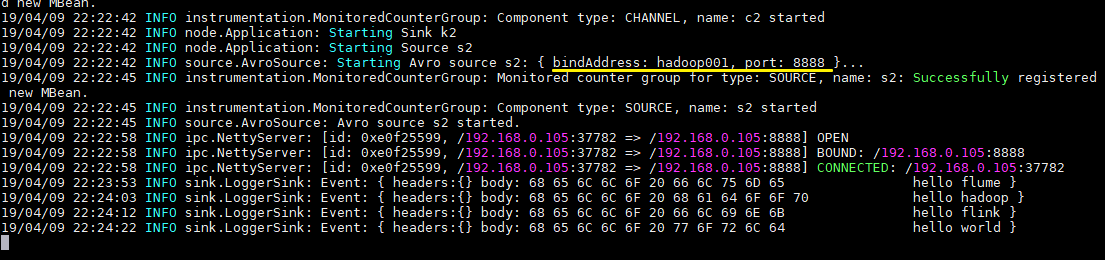
向檔案 tmp/log.txt 中追加內容:

可以看到已經從 8888 埠監聽到內容,併成功輸出到控制檯:
更多大資料系列文章可以參見 GitHub 開源專案: 大資料入門指南