
selenium+谷歌無頭瀏覽器爬取網易新聞國內板塊
阿新 • • 發佈:2019-04-22
quest alt 新聞列表 body lac windows text 分享 encoding
網頁分析
首先來看下要爬取的網站的頁面
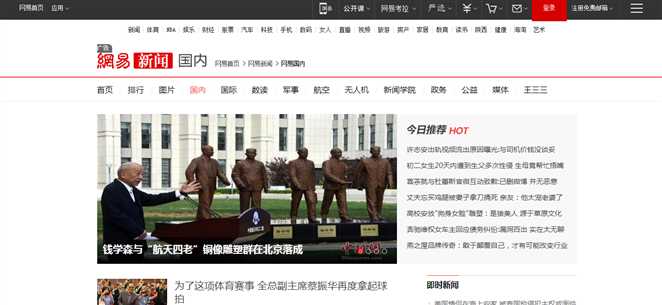
查看網頁源代碼:你會發現它是由js動態加載顯示的
所以采用selenium+谷歌無頭瀏覽器來爬取它
1 加載網站,並拖動到底,發現其還有個加載更多
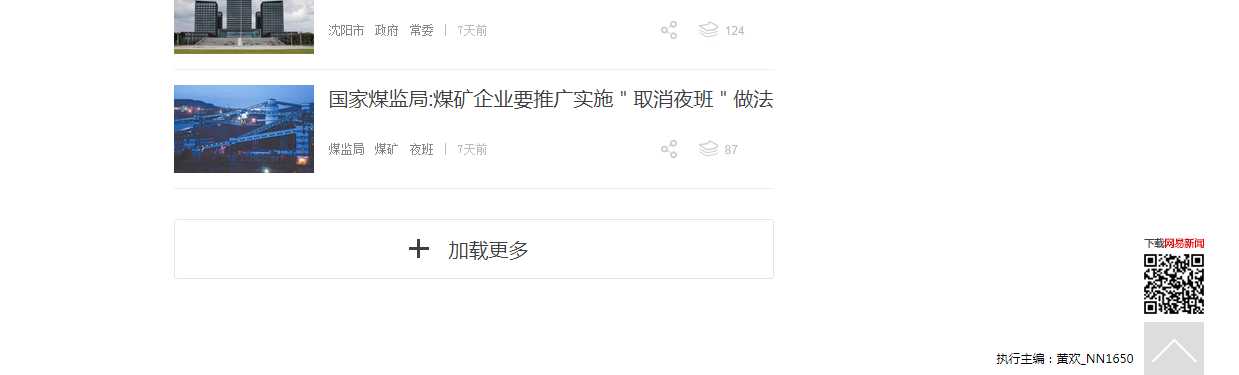
2 模擬點擊它,然後再次拖動到底,,就可以加載完整個頁面
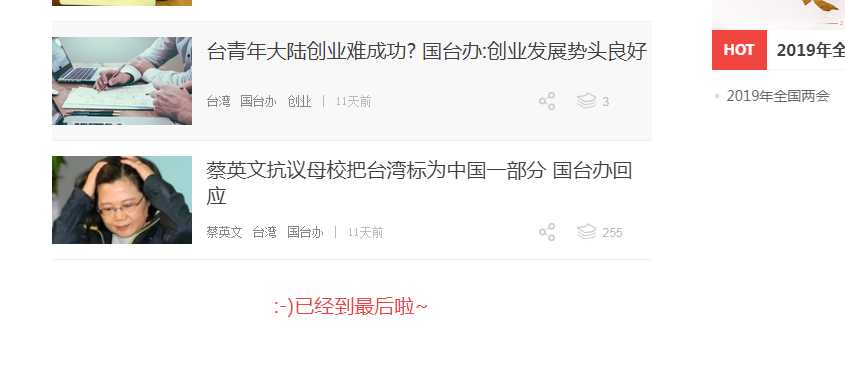
示例代碼
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from time import sleep
得到結果:
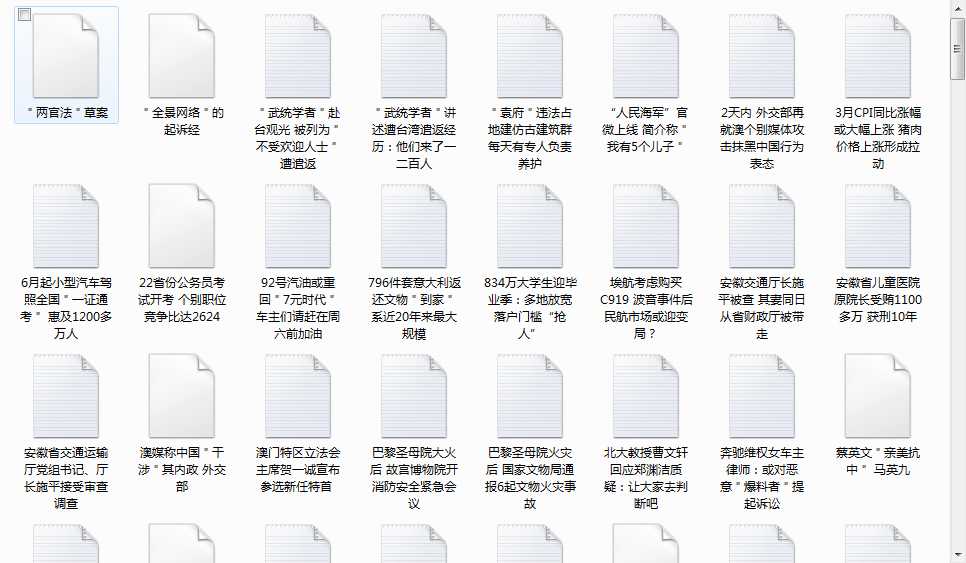
隨意打開一個txt:

總結:
1 其實主要的工作還是模擬瀏覽器來進行操作。
2 處理動態的js其實還有其他辦法。
3 爬蟲的方法有好多種,主要還是選擇適合自己的。
4 自己的代碼寫的太爛了。
selenium+谷歌無頭瀏覽器爬取網易新聞國內板塊