
HBase資料模型解析和基本的表設計分析
最近在學習HBase的使用,並仔細閱讀了一篇官方推薦的部落格,在這裡就以一邊翻譯一邊總結的方式和大家一起梳理一下HBase的資料模型和基本的表設計思路。
官方推薦的部落格原文地址:http://0b4af6cdc2f0c5998459-c0245c5c937c5dedcca3f1764ecc9b2f.r43.cf2.rackcdn.com/9353-login1210_khurana.pdf點選開啟連結
HBase是一個開源可伸縮的針對海量資料儲存的分散式nosql資料庫,它根據Google Bigtable資料模型來建模並構建在hadoop的hdfs儲存系統之上。它和關係型資料庫Mysql, Oracle等有明顯的區別,HBase的資料模型犧牲了關係型資料庫的一些特性但是卻換來了極大的可伸縮性和對錶結構的靈活操作。在一定程度上,Hbase又可以看成是以行鍵(Row Key),列標識(column qualifier),時間戳(timestamp)標識的有序Map資料結構的資料庫,具有稀疏,分散式,持久化,多維度等特點。
Base的資料模型介紹
HBase的資料模型也是由一張張的表組成,每一張表裡也有資料行和列,但是在HBase資料庫中的行和列又和關係型資料庫的稍有不同。下面統一介紹HBase資料模型中一些名詞的概念:
表(Table): HBase會將資料組織進一張張的表裡面,但是需要注意的是表名必須是能用在檔案路徑裡的合法名字,因為HBase的表是對映成hdfs上面的檔案。
行(Row): 在表裡面,每一行代表著一個數據物件,每一行都是以一個行鍵(Row Key)來進行唯一標識的,行鍵並沒有什麼特定的資料型別,以二進位制的位元組來儲存。
列族(Column Family): 在定義HBase表的時候需要提前設定好列族, 表中所有的列都需要組織在列族裡面,列族一旦確定後,就不能輕易修改,因為它會影響到HBase真實的物理儲存結構,但是列族中的列標識(Column Qualifier)以及其對應的值可以動態增刪。表中的每一行都有相同的列族,但是不需要每一行的列族裡都有一致的列標識(Column Qualifier)和值,所以說是一種稀疏的表結構,這樣可以一定程度上避免資料的冗餘。例如:{row1, userInfo: telephone —> 137XXXXX869 }{row2, userInfo: fax phone —> 0898-66XXXX } 行1和行2都有同一個列族userinfo,但是行1中的列族只有列標識(Column Qualifier):行動電話號碼,而行2中的列族中只有列標識(Column Qualifier):傳真號碼。
列標識(Column Qualifier): 列族中的資料通過列標識來進行對映,其實這裡大家可以不用拘泥於“列”這個概念,也可以理解為一個鍵值對,Column Qualifier就是Key。列標識也沒有特定的資料型別,以二進位制位元組來儲存。
單元(Cell): 每一個 行鍵,列族和列標識共同組成一個單元,儲存在單元裡的資料稱為單元資料,單元和單元資料也沒有特定的資料型別,以二進位制位元組來儲存。
時間戳(Timestamp): 預設下每一個單元中的資料插入時都會用時間戳來進行版本標識。讀取單元資料時,如果時間戳沒有被指定,則預設返回最新的資料,寫入新的單元資料時,如果沒有設定時間戳,預設使用當前時間。每一個列族的單元資料的版本數量都被HBase單獨維護,預設情況下HBase保留3個版本資料。
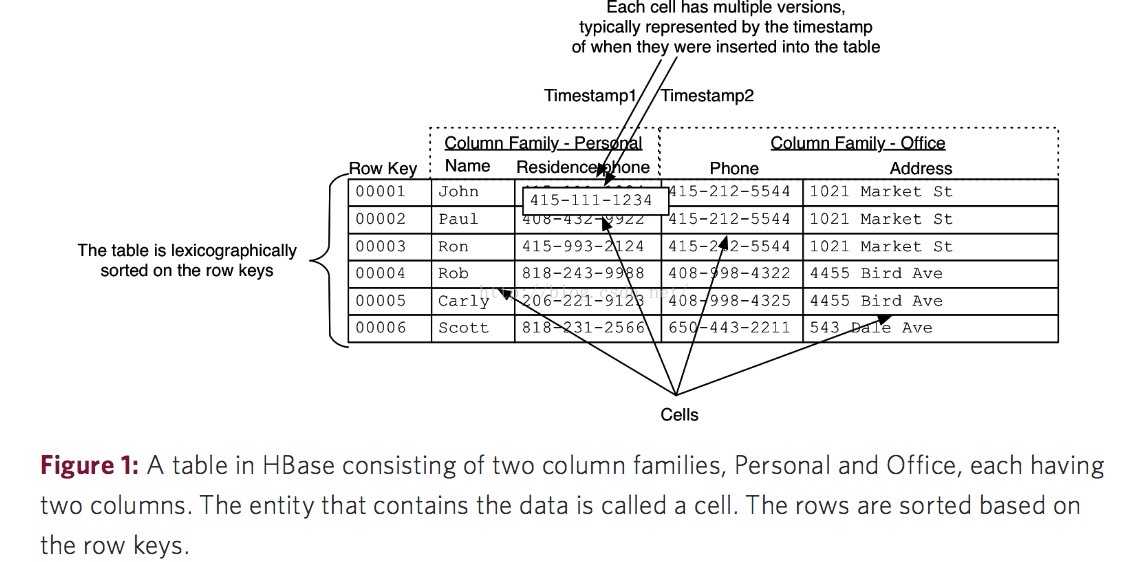
圖片來自:http://0b4af6cdc2f0c5998459-c0245c5c937c5dedcca3f1764ecc9b2f.r43.cf2.rackcdn.com/9353-login1210_khurana.pdf
有時候,你也可以把HBase看成一個多維度的Map模型去理解它的資料模型。正如下圖,一個行鍵對映一個列族陣列,列族陣列中的每個列族又對映一個列標識陣列,列標識陣列中的每一個列標識(Column Qualifier)又對映到一個時間戳陣列,裡面是不同時間戳對映下不同版本的值,但是預設取最近時間的值,所以可以看成是列標識(Column Qualifier)和它所對應的值的對映。使用者也可以通過HBase的API去同時獲取到多個版本的單元資料的值。Row Key在HBase中也就相當於關係型資料庫的主鍵,並且Row Key在建立表的時候就已經設定好,使用者無法指定某個列作為Row Key。
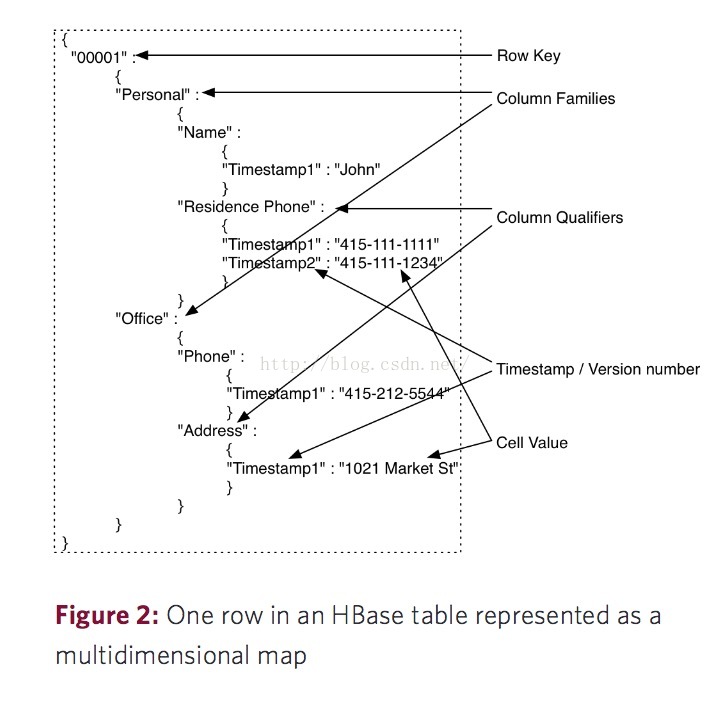
又有的時候,你也可以把HBase看成是一個類似Redis那樣的Key-Value資料庫。如下圖,當你要查詢某一行的所有資料時,Row Key就相當於Key,而Value就是單元中的資料(列族,列族裡的列和列中時間戳所對應的不同版本的值);當深入到HBase底層的儲存機制時,使用者要查詢指定行裡某一條單元資料時,HBase會去讀取一個數據塊,裡面除了有要查詢的單元資料,可能同時也會獲取到其它單元資料,因為這個資料塊還包含著這個Row Key所對應的其它列族或其它的列資訊,這些資訊實際也代表著另一個單元資料,這也是HBase的API內部實際的工作原理。

圖片來自:http://0b4af6cdc2f0c5998459-c0245c5c937c5dedcca3f1764ecc9b2f.r43.cf2.rackcdn.com/9353-login1210_khurana.pdf
HBase提供了豐富的API介面讓使用者去操作這些資料。主要的API介面有3個,Put,Get,Scan。Put和Get是操作指定行的資料的,所以需要提供行鍵來進行操作。Scan是操作一定範圍內的資料,通過指定開始行鍵和結束行鍵來獲取範圍,如果沒有指定開始行鍵和結束行鍵,則預設獲取所有行資料。
HBase的表設計中需要注意的問題
當開始設計HBase中的表的時候需要考慮以下的幾個問題:
1. Row Key的結構該如何設定,而Row Key中又該包含什麼樣的資訊(這個很重要,下面的例子會有說明)
2. 表中應該有多少的列族
3. 列族中應該儲存什麼樣的資料
4. 每個列族中儲存多少列資料
5. 列的名字分別是什麼,因為操作API的時候需要這些資訊
6. 單元中(cell)應該儲存什麼樣的資訊
7. 每個單元中儲存多少個版本資訊
在HBase表設計中最重要的就是定義Row-Key的結構,要定義Row-Key的結構時就不得不考慮表的接入樣本,也就是在真真實應用中會對這張表出現什麼樣的讀寫場景。除此之外,在設計表的時候我們也應該要考慮HBase資料庫的一些特性。
1. HBase中表的索引是通過Key來實現的
2. 在表中是通過Row Key的字典序來對一行行的資料來進行排序的,表中每一塊區域的劃分都是通過開始Row Key和結束Row Key來決定的。
3. 所有儲存在HBase表中的資料都是二進位制的位元組,並沒有資料型別。
4. 原子性只在行內保證,HBase表中並沒有多行事務。
5. 列族(Column Family)在表建立之前就要定義好
6. 列族中的列標識(Column Qualifier)可以在表建立完以後動態插入資料時新增。
接下來我們考慮一個這樣的場景,我們要設計一張表,用來儲存微博上使用者互粉的資訊。所以設計表之前,我們要考慮業務中的讀寫場景。
讀場景中我們要考慮:
1. 每個使用者都關注了誰
2. 使用者A有沒有關注使用者B
3. 誰關注了使用者A
寫場景中我們要考慮:
1. 使用者關注了另一個使用者
2. 使用者取消關注某個使用者
下面我們來看幾種表結構的設計:
第一種表結構設計中,在這種表結構設計中,每一行代表著某個使用者和所有他所關注的其它使用者。這個使用者ID就是Row Key,而每一個列標識(Column Qualifier)就是這個使用者所關注的其他使用者在列族裡的序號,單元資料就是這個使用者所關注的其他使用者的使用者ID。在這種表結構的設計下,“每個使用者都關注了誰”這個問題很好解決,但對於“使用者A有沒有關注使用者B”這個問題在列很多的時候,需要遍歷所有單元資料去找到使用者B,這樣的開銷會十分大。並且當新增新的被關注使用者時,因為不知道給這個新使用者分配什麼樣的列族序號,需要遍歷整個列族中的所有列找出最後一個列,並將最後一個列的序號+1給新的被關注使用者作為列族內的序號,這樣的開銷也十分大。
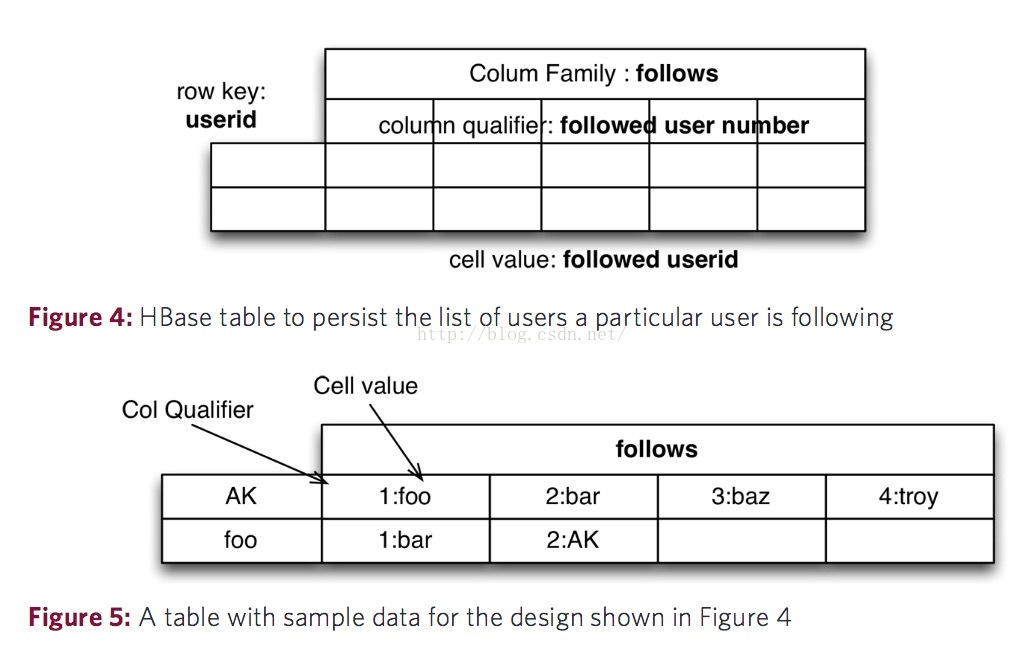
圖片來自:http://0b4af6cdc2f0c5998459-c0245c5c937c5dedcca3f1764ecc9b2f.r43.cf2.rackcdn.com/9353-login1210_khurana.pdf
所以衍生出了第二種表結構設計,如下圖,新增一個counter記錄列族中所有列的總數量,當新增新的被關注使用者時,這個新使用者的序號就是counter+1。但是當要取消關注某個使用者時,一樣得遍歷所有的列資料,而且最大的問題是在於HBase不支援事務處理,這種通過counter來新增被關注使用者的操作邏輯得寫在客戶端中。
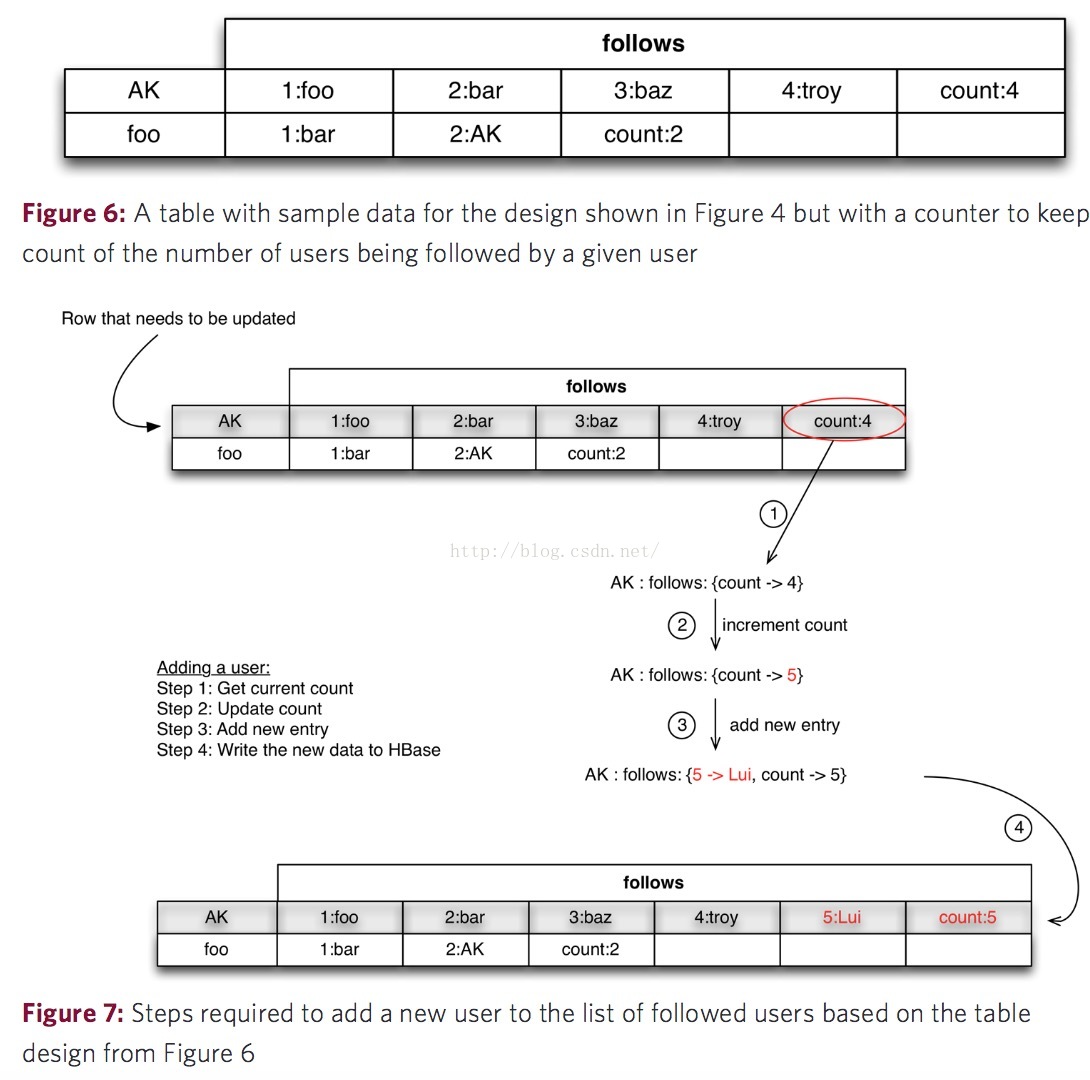
圖片來自:http://0b4af6cdc2f0c5998459-c0245c5c937c5dedcca3f1764ecc9b2f.r43.cf2.rackcdn.com/9353-login1210_khurana.pdf
回想一下,列標識(Column Qualifier)儲存的時候是二進位制的位元組,所以列標識可以儲存任何資料,而且列標識還是動態增添的,基於這個特性我們再改進表的設計,如下圖。這次以被關注的使用者ID做為列標識(Column Qualifier),然後單元資料可以是任意數字,比如全部統一成1。在這種表結構的設計下,新增新的被關注者,以及取消關注都會變得很簡單。但是對於讀場景中,誰關注了使用者A這個問題,因為HBase資料庫的索引只建立在Row Key上,這裡不得不掃描全表去統計所有關注了使用者A的使用者數量,所以下面的這個表結構設計也存在一定的效能問題。這裡也引出一個思路,被關注者需要以某種方式新增索引。

圖片來自:http://0b4af6cdc2f0c5998459-c0245c5c937c5dedcca3f1764ecc9b2f.r43.cf2.rackcdn.com/9353-login1210_khurana.pdf
針對上面的表結構有三種優化方案,第一種是新建另一張表,裡面儲存某個使用者和所有關注他的使用者。第二種解決方案就是在同一張表中也儲存某個使用者和所有關注他的使用者的資訊,並從Row Key中區分開來,比如:Row key為Jame_001_following的這行儲存著所有Jame關注的人的資訊,而Row_Key為Jame_001_followed的這行儲存著所有關注Jame的人的資訊。最後一種優化方案就是,如下圖,將Row Key設計成“followerID+followedID”的形式,比如:“Jame+Emma”,這裡的Row Key值就代表著Jame關注了Emma(其實這裡應該是“Jame的ID+Emma的ID”,只是為了解釋方便而直接用名字),同時包含了關注者和被關注者兩個資訊;還需要注意的一點就是列族的名字被設計成只有一個字母f,這樣設計的好處就是減少了HBase對資料的I/O操作壓力,同時減少了返回到客戶端的資料位元組,提高響應速度,因為每一個返回給客戶端的KeyValue物件都會包含列族名字。同時將被關注人的使用者名稱稱也儲存在了表中作為Column Qualifier,這樣做的好處就是節省了去使用者表查詢使用者名稱的資源。在這種表結構設計下,“使用者A取消關注某個使用者B”,“使用者A有沒有關注使用者B?”的業務處理就會變得簡單高效。
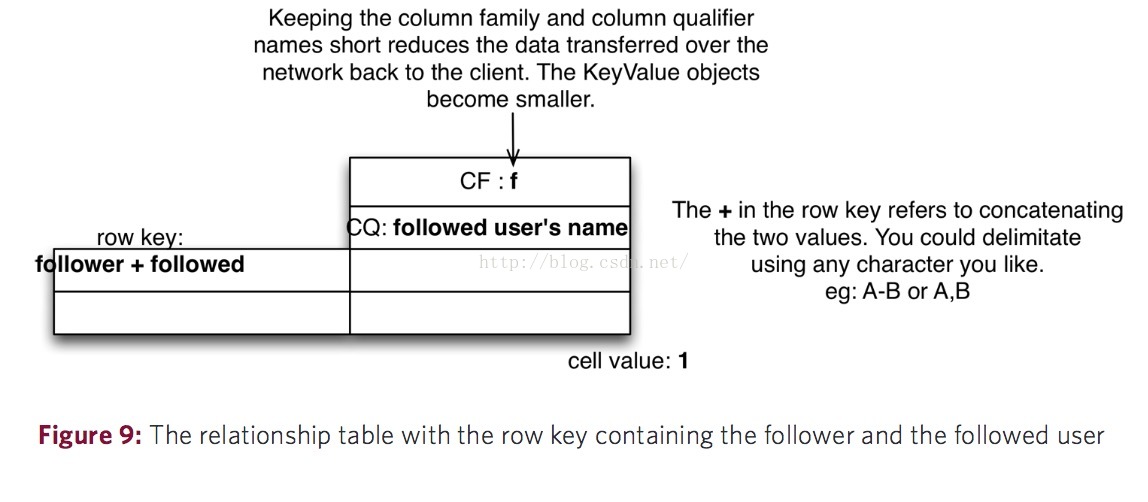
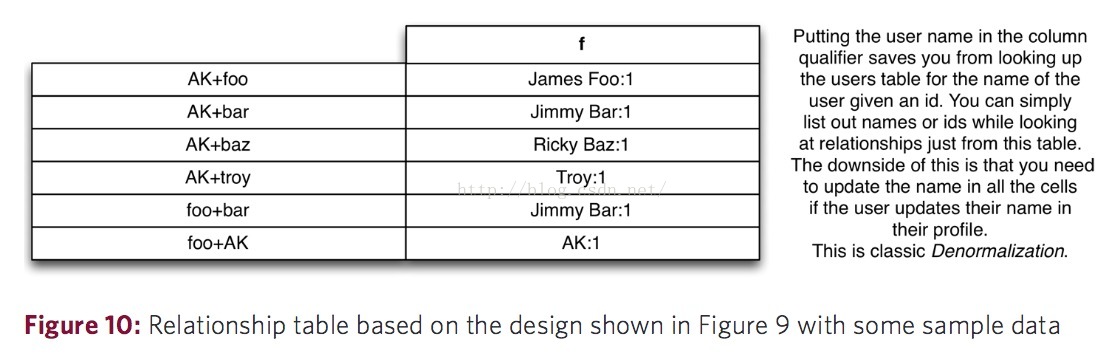
圖片來自:http://0b4af6cdc2f0c5998459-c0245c5c937c5dedcca3f1764ecc9b2f.r43.cf2.rackcdn.com/9353-login1210_khurana.pdf
還有一個需要注意的問題,就是在實際的生產環境中,還需要將Row Key使用MD5加密,一方面是使Row Key的長度都一致,能提高資料的存取效能。這方面的優化不在本文的討論範圍內。
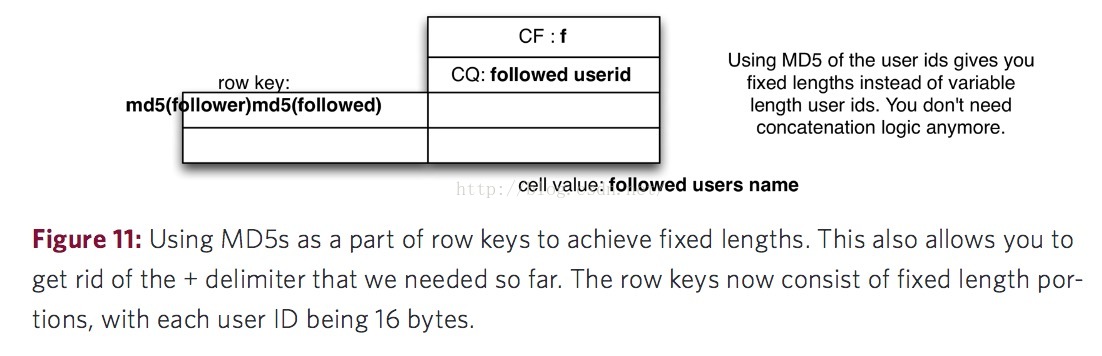
圖片來自:http://0b4af6cdc2f0c5998459-c0245c5c937c5dedcca3f1764ecc9b2f.r43.cf2.rackcdn.com/9353-login1210_khurana.pdf
總結:
整篇文章概述了HBase的資料模型和基本的表設計思路。下面是HBase一些關鍵特性的總結:
1. Row Key是HBase表結構設計中很重要的一環,它設計的好壞直接影響程式和HBase互動的效率和資料儲存的效能。
2. Base的表結構比傳統關係型資料庫更靈活,你能儲存任何二進位制資料在表中,而且無關資料型別。
3. 在相同的列族中所有資料都具有相同的接入模式
4. 主要是通過Row Key來建立索引
5. 以縱向擴張為主設計的表結構能快速簡單的獲取資料,但犧牲了一定的原子性,就比如上文中最後一種表結構;而以橫向擴張為主設計的表結構,也就是列族中有很多列,比如上文中第一種表結構,能在行裡面保持一定的原子性。
6. HBase並不支援事務,所有儘量在一次API請求操作中獲取到結果
7. 對Row Key的Hash優化能獲得固定長度的Row Key並使資料分佈更加均勻一些,而不是集中在一臺伺服器上,但是也犧牲了一定的資料排序和讀取效能。
8. 可以利用列標識(Column Qualifier)來儲存資料。
9. 列標識(Column Qualifier)名字的長度和列族名字的長度都會影響I/O的讀寫效能和傳送給客戶端的資料量,所以它們的命名應該簡潔!
References
[1] Amandeep Khurana Introduction To HBase Schema Design: http://0b4af6cdc2f0c5998459-c0245c5c937c5dedcca3f1764ecc9b2f.r43.cf2.rackcdn.com/9353-login1210_khurana.pdf