
梯度下降原理及線上性迴歸、邏輯迴歸中的應用
1 基本概念
1)定義
梯度下降法,就是利用負梯度方向來決定每次迭代的新的搜尋方向,使得每次迭代能使待優化的目標函式逐步減小。
梯度下降法是2範數下的最速下降法。 最速下降法的一種簡單形式是:x(k+1)=x(k)-a*g(k),其中a稱為學習速率,可以是較小的常數。g(k)是x(k)的梯度。
梯度其實就是函式的偏導數。
2)舉例
對於函式z=f(x,y),先對x求偏導,再對y求偏導
,則梯度為(
,
)。
比如,偏導
=4x,
=6y。則在(2,4)點的梯度(8,24)。
2 梯度下降線上性迴歸中的應用
假定函式為如下形式:
cost function採用最小均方損失函式:
這個錯誤估計函式是對x(i)的估計值與真實值y(i)差的平方和(梯度下降要考慮所有樣本)作為錯誤估計函式,前面乘上的1/2是為了在求導的時候,這個係數就不見了。
我們的目標是選擇合適的,使得cost
function的值最小。
接下來介紹梯度減少的過程,即對函式求偏導。因為是線性函式,對每個分量\theta _{i}求編導的時候,其它項為0。

更新的過程,也就是θi會向著梯度最小的方向進行減少。θi表示更新之前的值,-後面的部分表示按梯度方向減少的量,α表示步長,也就是每次按照梯度減少的方向變化多少。
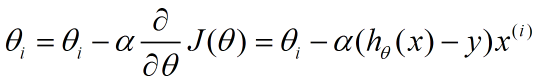
一個很重要的地方值得注意的是,梯度是有方向的,對於一個向量θ,每一維分量θi都可以求出一個梯度的方向,我們就可以找到一個整體的方向,在變化的時候,我們就朝著下降最多的方向進行變化就可以達到一個最小點,不管它是區域性的還是全域性的。
3 梯度下降在邏輯迴歸中的應用
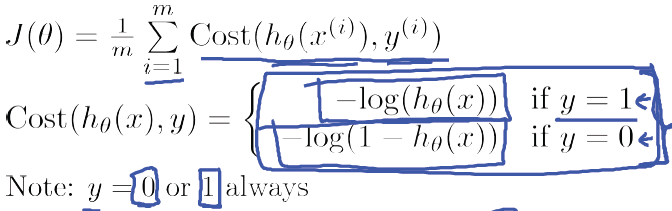
由於y 只能等於0或1,所以可以將邏輯迴歸中的Cost function的兩個公式合併,具體推導如下:
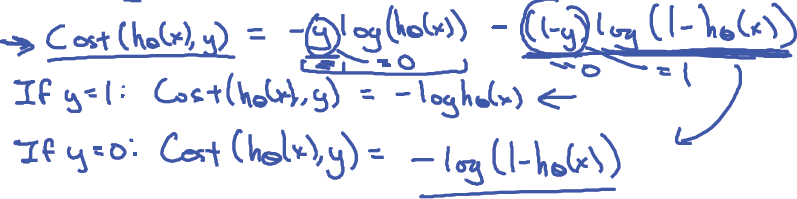
故邏輯迴歸的Cost function可簡化為:

注意中括號中的公式正是對邏輯迴歸進行最大似然估計中的最大似然函式,對於最大似然函式求最大值,從而得到引數(\theta\)的估計值。反過來,這裡為了求一個合適的引數,需要最小化Cost function,也就是:
minθJ(θ)
而對於新的變數x來說,就是根據hθ(x)的公式輸出結果:
與線性迴歸相似,這裡我們採用梯度下降演算法來學習引數θ,對於J(θ):
目標是最小化J(θ),則梯度下降演算法的如下:
對J(θ)求導後,梯度下降演算法如下:
4 參考文獻:
梯度下降演算法,http://blog.sina.com.cn/s/blog_62339a2401015jyq.html
梯度下降法,http://deepfuture.iteye.com/blog/1593259
斯坦福大學機器學習第六課“邏輯迴歸,http://52opencourse.com/125/coursera%E5%85%AC%E5%BC%80%E8%AF%BE%E7%AC%94%E8%AE%B0-%E6%96%AF%E5%9D%A6%E7%A6%8F%E5%A4%A7%E5%AD%A6%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AC%AC%E5%85%AD%E8%AF%BE-%E9%80%BB%E8%BE%91%E5%9B%9E%E5%BD%92-logistic-regression
BP演算法淺談,http://blog.csdn.net/pennyliang/article/details/6695355
5 收穫
1)瞭解了梯度的概念;
2) 複習了導數公式、偏導數的概念;
3)對梯度下降公式進行了推導,掌握更牢固。