
Linux下fork函式及pthread函式的總結
fork
Linux多程序程式設計中的可以使用fork函式來建立子程序。fork函式定義在標頭檔案unistd.h中(uni表示unix,std當然是標準庫,所以很好記),該函式的宣告為pid_t
fork(void)其中函式的返回值型別為pid_t,可以理解為一個整型,返回值具體為:
- 在父程序中,fork返回新建立的子程序的程序ID;
- 在子程序中,fork返回0;
- 如果建立子程序失敗,則返回一個負值
具體建立的子程序與父程序的關係,很顯示fork函式不能接受任何引數,它只簡單地將父程序的幾乎所有資源全部複製給子程序,然後就相當於父程序的一個副本執行,且無法與父進行共享資料。
具體 來說使用fork函式得到的子程序從父程序繼承了整個程序的地址空間,包括:程序上下文、程序堆疊、記憶體資訊、開啟的檔案描述符、訊號控制設定、程序優先順序、程序組號、當前工作目錄、根目錄、資源限制、控制終端等。
子程序與父程序的區別在於:
- 父程序設定的鎖,子程序不繼承(因為如果是排它鎖,被繼承的話,矛盾了)
- 各自的程序ID和父程序ID不同
- 子程序的未決告警被清除;
- 子程序的未決訊號集設定為空集。
當然linux下的標頭檔案sched.h中有一個fork升級版本的程序建立函式clone。clone是fork的升級版本,不僅可以建立程序或者執行緒,還可以指定建立新的名稱空間(namespace)、有選擇的繼承父程序的記憶體、甚至可以將創建出來的程序變成父程序的兄弟程序等。clone() 函式則可以將部分父程序的資源通過引數設定有選擇地複製給子程序,沒有複製的資源可以通過指標共享給子程序
下面主要分析fork函式建立程序數及執行情況
獲取程序ID的相關函式有:
- getppid()返回當前程序的父程序ID
- getpid()返回當前程序ID
這兩個函式都在標頭檔案unistd.h中,不接受引數,返回值型別為pid_t
網上關於fork函式建立多少個子程序的分析有很多,這裡說一個簡單分析方法,其實fork就是為父程序建立子程序,也就是說一個程序,執行fork之後就會變成2個程序,僅此而已。當執行多次fork函式時與二叉樹很像,從根結點往葉子節點,每次一個變2個,可以很好地用二叉樹來分析建立的子程序樹,以及涉及到迴圈時,迴圈執行的次數。首先說一下結論:假定根結點為二叉樹的第0層(為了方便後面分析),每執行一次fork,就增加一層,如果使用迴圈執行n個fork,則共有n層,相應滿二叉樹的葉子結點數2^n即為總共建立的子程序數(根為第0層),滿二叉樹除了根結點之外的總結點數2^(n+1)-2就是迴圈執行的總次數。也就是說
下面使用幾個例項分析根據fork的原理和二叉樹方法(其實也是根據原理)來分析:
fork()用法
#include <iostream>
#include <unistd.h>
int main(void)
{
pid_t fpid; //建立一個臨時變數用於存放fork的返回值
int count = 0;
fpid = fork(); //建立子程序,父程序與子程序將分別執行此後的程式碼
if (fpid < 0) //建立子程序失敗時將返回負值
¦ std::cout << "Error in fork!" << std::endl;
else if (fpid == 0) { //子程序中fork的返回值為0,所以將由子程序執行該分支
¦ std::cout << "Child: parent_pid:" << getppid() << " pid:" << getpid() << " child_pid:" << fpid << std::endl;
¦ count++; //子程序複製來的count值為0,++之後將為1
}
else { //父程序中fork的返回值為子程序的pid,所以將由父程序執行該分支
¦ std::cout << "Parent: parent_pid:" << getppid() << " pid:" << getpid() << " child_pid:" << fpid << std::endl;
¦ count++; //父程序中count為0,父子程序中的變數等資料是完全獨立的
}
std::cout << "count: " << count << std::endl; //最後輸出count的當前值,顯示該句父子程序都要執行
return 0;
}
輸出結果為:
| 1234 | Parent: parent_pid:3084 pid:3087 child_pid:3088count: 1Child: parent_pid:3087 pid:3088 child_pid:0count: 1 |
可以看到父程序的中建立的子程序的pid:3088剛好是子程序當前的pid,兩個程序輸出的count都是1,也就是隻進行了一次累加
套用上面關於二叉樹方法分析的情況,執行一次fork,即2^1=2兩個程序
通過迴圈執行多個fork-1
不看輸出的話考慮輸出結果是什麼,會輸出多少次
#include <iostream>
#include <unistd.h>
int main(void)
{
int count = 0;
for (int i = 1; i < 4; ++i) { //通過for迴圈執行3次fork
¦ fork();
}
std::cout << ++count << std::endl;
return 0;
}
輸出結果為:
| 12345678 | 11111111 |
二叉樹法分析:
一共8個1,for迴圈中執行了3次fork,共建立了2^3=8個子程序,所以共有8個1輸出。如下二叉樹圖中葉子結點所示:
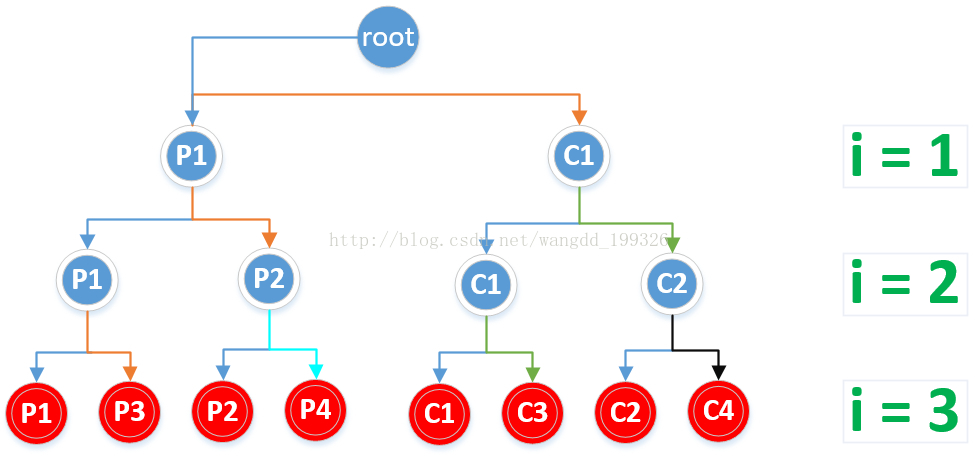
紅色結點(即葉子結點)為建立的所有子程序
如圖中標識,C1、P2、P3都是P1的子程序,只是它們創建於p1的不同時期,同樣P4是P2的子程序,從C1建立的子程序有C2,C3。其中來自不同顏色的箭頭表示不同的關係,箭頭表示父程序->子程序,相同顏色的線表示來自同一個程序。
可以通過以下程式碼來驗證:
#include <iostream>
#include <unistd.h>
int main(void)
{
int count = 0;
for (int i = 1; i < 4; ++i) {
¦ fork();
}
//分別輸出各程序的父程序PID:當前程序PID:子程序PID
std::cout << getppid() << " : " << getpid() << " : " << fpid << std::endl;
return 0;
}
某一次的執行結果為(每次執行的結果都不一樣,因為程序號肯定不同,當然有可能會出現程序號為1的情況,由於當獲取父程序時,如果父程序此時已經執行完成並退出,那麼系統中就不存在此程序,此時就返回其程序號為1):
| 12345678 | 3628 : 3630 : 36333630 : 3633 : 03629 : 3634 : 03628 : 3629 : 36343625 : 3628 : 36323628 : 3632 : 03629 : 3631 : 36353631 : 3635 : 0 |
可以根據類似連結串列的關係畫出如下圖:
!()[fork-1-1.jpg]
再根據上圖的分析,很容易推斷出各程序的ID在二叉樹圖上的對應關係
通過迴圈執行多個fork-2
注意下面的程式碼與上面fork-1中的唯一區別是將輸出放在了for迴圈裡面
不看輸出的話考慮輸出結果是什麼,會輸出多少次
#include <iostream>
#include <unistd.h>
int main(void)
{
int count = 0;
for (int i = 1; i < 4; ++i) { //通過for迴圈執行3次fork
¦ fork();
std::cout << ++count << std::endl;
}
return 0;
}
輸出結果為:
| 1234567891011121314 | 11222233333333 |
建立的子程序數分析與fork-1中一樣,都是8個子程序。關於for迴圈中的輸出執行次數,當i=1時,執行一次fork,建立2個子程序,記為p1, c1(px表示父程序,cx表示子程序),程序p1,c1將分別從i=1執行到i=3,在for迴圈內部共執行2*3=6次,即這兩個子程序會分別輸出1,2,3各一次。由於這兩個程序在執行for迴圈時還會繼續建立程序,所以它們的2個1會首先輸出在前面。當i=2時,執行第二次fork,之前的2個程序p1, c1將分別再建立一個程序,記為p2、c2(假設p2來自p1,c2來自c1),p2、c2將從i=2開始執行到i=3,這兩個程序for迴圈內部共執行2*2=4次。當前執行到i=2時共有4個程序,分別為p1、c1、p2、c2,它們會分別輸出一次2,共輸出4個2。當i=3時,當前的4個程序將再分別建立一個程序,共建立4個程序,新建立的4個程序將各自執行一次for迴圈內部,for迴圈即結束了,共執行4次for迴圈內部。此時共有8個程序,每個程序都會輸出一次3,共8個3。再綜合各個程序中for迴圈執行的次數,可知6+4+4=14次,所以共有14個輸出。
二叉樹分析如下圖所示:
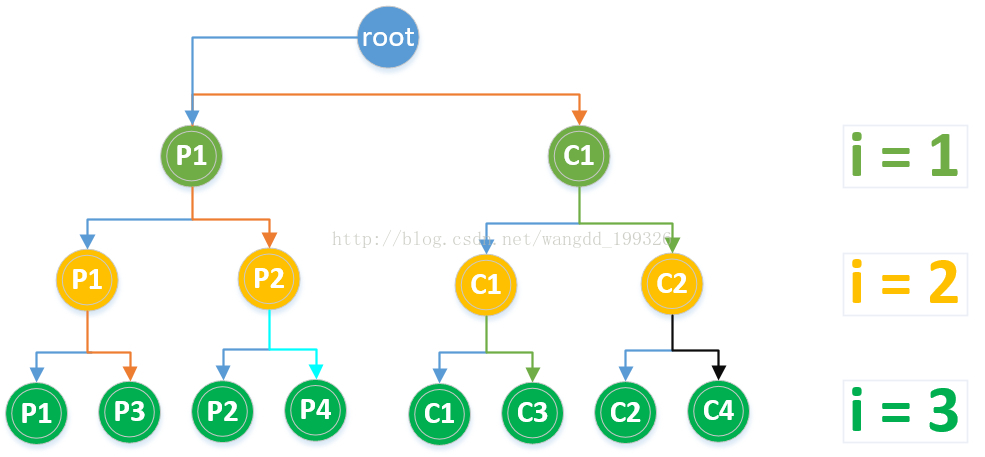
從上圖可以看出i的取值為1,2,3階段,各階段執行的程序數分別為2,4,8,雖然一共只有8個程序,但for迴圈各階段的程序都會進行一次輸出,所以共輸出14次,即為二叉樹除根節點的結點總數2^4-2=14。
fork()||fork()程序數
分析如下程式碼建立的程序數:
#include <iostream>
#include <unistd.h>
int main(void)
{
int count = 0;
fork() || fork();
std::cout << count << std::endl;
return 0;
}
輸出結果為:
| 123 | 111 |
由於fork函式在不同程序中的返回值不同,在子程序中返回為0,所以第一個fork執行完之後會有兩個程序,父程序中fork返回值為真,||後面的程式碼不會執行,直接返回。子程序中fork()返回值為0,需要繼續執行後面一個fork,再次為子程序建立一個子程序,所以共有3個子程序。
畫二叉樹分析:
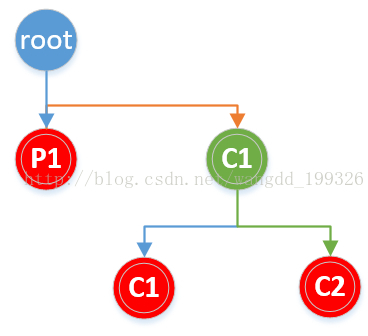
圖中葉子節點數即為程序數。
fork()&&fork()||fork()
分析以下程式碼建立的程序數:
#include <iostream>
#include <unistd.h>
int main(void)
{
int count = 0;
(fork() && fork()) || fork();
std::cout << count << std::endl;
return 0;
}
輸出結果為:
| 12345 | 11111 |
首先第一個fork執行完之後為父程序(記為p1)建立一個子程序,記為c1,由於子程序fork返回值為0,所以子程序中第一個括號&&後面的表示式不需要再執行。父程序p1需要繼續執行第二個fork,再次建立一個子程序p2,父程序p1的fork返回為真,||後面的不需要再執行。第二個子程序p2需要繼續執行第三個fork,再次為第二子程序建立一個子程序p3,同樣由於c1程序fork返回值為0,所以也還需要執行第三個fork,為其建立一個子程序c2,所以一共會建立5個程序。
畫二叉樹分析,如下圖:
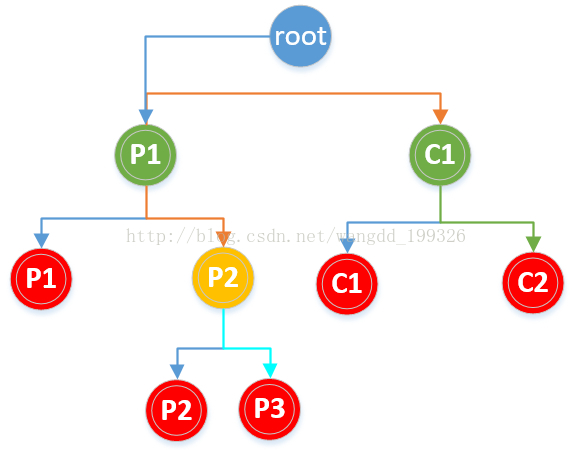
對於以下程式碼建立的程序數為多少?
#include <iostream>
#include <unistd.h>
int main(void)
{
int count = 0;
fork(); //執行完後將有2個程序
(fork() && fork()) || fork(); //根據上面分析,這部分會建立5個程序,執行完成會有2*5=10個程序
fork(); //執行完這句程序數會再次翻倍
std::cout << count << std::endl;
return 0;
}結果為252=20,自行分析,這類問題只需要分步分析即可,如果涉及到一些輸出的情況,最好畫圖看看
迴圈fork,不重新整理輸出緩衝區的情況
考慮以下程式會輸出多少個*:
#include <iostream>
#include <unistd.h>
int main(void)
{
int i;
for (i = 0; i < 3; i++) {
fork();
std::cout << "*";
}
return 0;
}
輸出結果為:
| 1 | ************************ |
按照通常的的想法,比如我們之前的公式,應該輸出2^4-2=14個,實際上輸出結果去是38=24個。
因為std::cout後面沒有輸出\n或者std::endl,也就是說在輸出時沒有重新整理輸出緩衝區,會導致父程序中的輸出緩衝區內容依然是上次的內容,子程序在複製時同樣會複製輸出緩衝區中的內容,導致子程序輸出緩衝區的內容實際上與父程序是一樣的。由於第一個父程序的for迴圈會執行3次,輸出緩衝區中會有3個,雖然有的子程序的迴圈只能執行2次或1次,但輸出緩衝區中的內容並沒有少,所以同樣最終也都會輸出3個。一共有8個程序,所以共有38=24個*輸出。
fork與虛擬地址空間
思考下面這段程式的輸出中父程序與子程序中的num及num地址是否相同:
#include <iostream>
#include <unistd.h>
int main(){
int pid;
int num=1;
pid=fork();
if(pid>0){
¦ num++;
¦ std::cout << "in parent:num:" << num << " addr:" << &num << std::endl;
}
else if(pid==0){
¦ std::cout << "in child:num:" << num << " addr:" << &num << std::endl;
}
return 0;
}
輸出結果為:
| 12 | in parent:num:2 addr:0x7fffed819768in child:num:1 addr:0x7fffed819768 |
竟然num的地址為父程序與子程序中是一樣的,但num的值卻是不同的,之所以會出現這種情況是因為linu的虛擬地址空間策略下,所有程序都以為自己獨享整個地址空間,所以每個程序都可以有0x01地址空間,但其實際對映到的真實地址空間並不相同。就像本文剛開始時說的一樣,fork在複製時會繼承父程序的整個地址空間,所以num的輸出地址是一樣的。
pthread
最後說一下Linux下的pthread函式,該函式屬於POSIX執行緒(POSIX threads)標準,該標準定義了一套用於執行緒的API,pthread函式包含在標頭檔案pthread.h中。
執行緒 VS 程序
執行緒也稱為輕量級的程序(lightweight process, LWP),在支援執行緒的系統中,執行緒是CPU排程和分派的基本單元;傳統作業系統中CPU高度和分派的基本單位是程序,傳統上的程序(相當於只含有一個執行緒的程序)也被稱為重量級程序(heavyweight
process, HWP)。當一個程序包含多個執行緒時,相當於將程序的任務劃分成多個子任務,由執行緒同時執行多個任何。
程序中引入執行緒後,執行緒即作為CPU排程和分派的基本單位,而程序則作為資源擁有的基本單位,同一程序中的執行緒切換不會引起程序切換,可以避免昂貴的系統呼叫。
因為程序之間可以併發執行,而同一程序中的執行緒之間也可以併發執行,所以執行緒提高了作業系統的併發性,能更有效的使用系統資源和提高系統的吞吐量。
執行緒擁有自己獨立的棧、排程優先順序和策略、訊號遮蔽字(建立時繼承)、errno變數以及執行緒私有資料,這些資源相對於程序佔用的資源來說很少。程序的其他地址空間(包含程序的程式碼段、資料段以及其他系統資源,如已開啟的檔案、IO裝置等)均被所有執行緒所共享,因此執行緒可以訪問程序的全域性變數和堆中分配的資料,並通過同步機制保證對資料訪問的一致性。這樣多執行緒相對於程序可以降低系統開銷。
pthread執行緒操作相關的函式或型別
- pthread_t 是pthread的執行緒ID
- pthread_create()用於建立新的執行緒
- pthread_equal()用於比較兩個執行緒id是否相等
- pthread_self() 用於獲取當前執行緒的id
- pthread_exit() 執行緒呼叫該函式主動退出執行緒
- pthread_join() 用於執行緒同步,以阻塞的方式等待指定執行緒結束