
瀏覽器工作原理(四):HTML解析器 HTML Parser
HTML解析器的工作是將html標識解析為解析樹。
HTML文法定義(The HTML grammar definition)
W3C組織制定規範定義了HTML的詞彙表和語法。非上下文無關文法(Not a context free grammar)
正如在解析簡介中提到的,上下文無關文法的語法可以用類似BNF的格式來定義。不幸的是,所有的傳統解析方式都不適用於html(當然我提出它們並不只是因為好玩,它們將用來解析css和js),html不能簡單的用解析所需的上下文無關文法來定義。
Html有一個正式的格式定義——DTD(Document Type Definition文件型別定義)——但它並不是上下文無關文法,html更接近於xml,現在有很多可用的xml解析器,html有個xml的變體——xhtml,它們間的不同在於,html更寬容,它允許忽略一些特定標籤,有時可以省略開始或結束標籤。總的來說,它是一種soft語法,不像xml呆板、固執。
顯然,這個看起來很小的差異卻帶來了很大的不同。一方面,這是html流行的原因——它的寬容使web開發人員的工作更加輕鬆,但另一方面,這也使很難去寫一個格式化的文法。所以,html的解析並不簡單,它既不能用傳統的解析器解析,也不能用xml解析器解析。
HTML DTD
Html適用DTD格式進行定義,這一格式是用於定義SGML家族的語言,包括了對所有允許元素及它們的屬性和層次關係的定義。正如前面提到的,html DTD並沒有生成一種上下文無關文法。
DTD有一些變種,標準模式只遵守規範,而其他模式則包含了對瀏覽器過去所使用標籤的支援,這麼做是為了相容以前內容。最新的標準DTD在http://www.w3.org/TR/html4/strict.dtd
DOM
輸出的樹,也就是解析樹,是由DOM元素及屬性節點組成的。DOM是文件物件模型的縮寫,它是html文件的物件表示,作為html元素的外部介面供js等呼叫。
樹的根是“document”物件。
DOM和標籤基本是一一對應的關係,例如,如下的標籤:
<html>
<body>
<p>
Hello DOM
</p>
<div><img src=”example.png” /></div>
</body>
</html>將會被轉換為下面的DOM樹:

圖8:示例標籤對應的DOM樹
解析演算法(The parsing algorithm)
正如前面章節中討論的,hmtl不能被一般的自頂向下或自底向上的解析器所解析。
原因是:
1. 這門語言本身的寬容特性
2. 瀏覽器對一些常見的非法html有容錯機制
3. 解析過程是往復的,通常原始碼不會在解析過程中發生改變,但在html中,指令碼標籤包含的“document.write”可能新增標籤,這說明在解析過程中實際上修改了輸入。
不能使用正則解析技術,瀏覽器為html定製了專屬的解析器。
Html5規範中描述了這個解析演算法,演算法包括兩個階段——符號化及構建樹。
符號化是詞法分析的過程,將輸入解析為符號,html的符號包括開始標籤、結束標籤、屬性名及屬性值。
符號識別器識別出符號後,將其傳遞給樹構建器,並讀取下一個字元,以識別下一個符號,這樣直到處理完所有輸入。
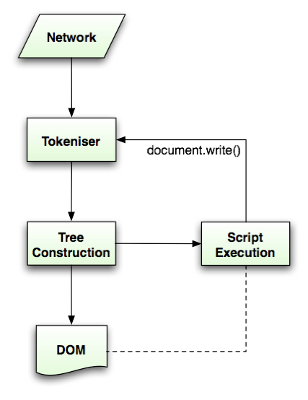 圖9:HTML解析流程
圖9:HTML解析流程符號識別演算法(The tokenization algorithm)
演算法輸出html符號,該演算法用狀態機表示。每次讀取輸入流中的一個或多個字元,並根據這些字元轉移到下一個狀態,當前的符號狀態及構建樹狀態共同影響結果,這意味著,讀取同樣的字元,可能因為當前狀態的不同,得到不同的結果以進入下一個正確的狀態。
這個演算法很複雜,這裡用一個簡單的例子來解釋這個原理。
基本示例——符號化下面的html:
<html>
<body>
Hello world
</body>
</html>
初始狀態為“Data State”,當遇到“<”字元,狀態變為“Tag open state”,讀取一個a-z的字元將產生一個開始標籤符號,狀態相應變為“Tag name state”,一直保持這個狀態直到讀取到“>”,每個字元都附加到這個符號名上,例子中建立的是一個html符號。
當讀取到“>”,當前的符號就完成了,此時,狀態回到“Data state”,“<body>”重複這一處理過程。到這裡,html和body標籤都識別出來了。現在,回到“Data state”,讀取“Hello world”中的字元“H”將建立並識別出一個字元符號,這裡會為“Hello world”中的每個字元生成一個字元符號。
這樣直到遇到“</body>”中的“<”。現在,又回到了“Tag open state”,讀取下一個字元“/”將建立一個閉合標籤符號,並且狀態轉移到“Tag name state”,還是保持這一狀態,直到遇到“>”。然後,產生一個新的標籤符號並回到“Data state”。後面的“</html>”將和“</body>”一樣處理。
 圖10:符號化示例輸入
圖10:符號化示例輸入樹的構建演算法(Tree construction algorithm)
在樹的構建階段,將修改以Document為根的DOM樹,將元素附加到樹上。每個由符號識別器識別生成的節點將會被樹構造器進行處理,規範中定義了每個符號相對應的Dom元素,對應的Dom元素將會被建立。這些元素除了會被新增到Dom樹上,還將被新增到開放元素堆疊中。這個堆疊用來糾正巢狀的未匹配和未閉合標籤,這個演算法也是用狀態機來描述,所有的狀態採用插入模式。
來看一下示例中樹的建立過程:
<html>
<body>
<span style="white-space:pre"> </span>Hello world
</body>
</html>構建樹這一階段的輸入是符號識別階段生成的符號序列。
首先是“initial mode”,接收到html符號後將轉換為“before html”模式,在這個模式中對這個符號進行再處理。此時,建立了一個HTMLHtmlElement元素,並將其附加到根Document物件上。
狀態此時變為“before head”,接收到body符號時,即使這裡沒有head符號,也將自動建立一個HTMLHeadElement元素並附加到樹上。
現在,轉到“in head”模式,然後是“after head”。到這裡,body符號會被再次處理,將建立一個HTMLBodyElement並插入到樹中,同時,轉移到“in body”模式。
然後,接收到字串“Hello world”的字元符號,第一個字元將導致建立並插入一個text節點,其他字元將附加到該節點。
接收到body結束符號時,轉移到“after body”模式,接著接收到html結束符號,這個符號意味著轉移到了“after after body”模式,當接收到檔案結束符時,整個解析過程結束。

圖11:示例html樹的構建過程
解析結束時的處理(Action when the parsing is finished)
在這個階段,瀏覽器將文件標記為可互動的,並開始解析處於延時模式中的指令碼——這些指令碼在文件解析後執行。文件狀態將被設定為完成,同時觸發一個load事件。
Html5規範中有符號化及構建樹的完整演算法(http://www.w3.org/TR/html5/syntax.html#html-parser)。
瀏覽器容錯(Browsers error tolerance)
你從來不會在一個html頁面上看到“無效語法”這樣的錯誤,瀏覽器修復了無效內容並繼續工作。
以下面這段html為例:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
瀏覽器都具有錯誤處理的能力,但是,另人驚訝的是,這並不是html最新規範的內容,就像書籤及前進後退按鈕一樣,它只是瀏覽器長期發展的結果。一些比較知名的非法html結構,在許多站點中出現過,瀏覽器都試著以一種和其他瀏覽器一致的方式去修復。
Html5規範定義了這方面的需求,webkit在html解析類開始部分的註釋中做了很好的總結。
解析器將符號化的輸入解析為文件並建立文件,但不幸的是,我們必須處理很多沒有很好格式化的html文件,至少要小心下面幾種錯誤情況。
1. 在未閉合的標籤中新增明確禁止的元素。這種情況下,應該先將前一標籤閉合
2. 不能直接新增元素。有些人在寫文件的時候會忘了中間一些標籤(或者中間標籤是可選的),比如HTML HEAD BODY TR TD LI等
3. 想在一個行內元素中新增塊狀元素。關閉所有的行內元素,直到下一個更高的塊狀元素
4. 如果這些都不行,就閉合當前標籤直到可以新增該元素。
下面來看一些webkit容錯的例子:
</br>替代<br>
一些網站使用</br>替代<br>,為了相容IE和Firefox,webkit將其看作<br>。
程式碼:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}Note -這裡的錯誤處理在內部進行,使用者看不到。
迷路的表格
這指一個表格巢狀在另一個表格中,但不在它的某個單元格內。
比如下面這個例子:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
程式碼:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);webkit使用堆疊存放當前的元素內容,它將從外部表格的堆疊中彈出內部的表格,則它們變為了兄弟表格。
巢狀的表單元素
使用者將一個表單巢狀到另一個表單中,則第二個表單將被忽略。
程式碼:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag,m_document);
}太深的標籤繼承
www.liceo.edu.mx是一個由巢狀層次的站點的例子,最多隻允許20個相同型別的標籤巢狀,多出來的將被忽略。
程式碼:
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}放錯了地方的html、body閉合標籤
又一次不言自明。
支援不完整的html。我們從來不閉合body,因為一些愚蠢的網頁總是在還未真正結束時就閉合它。我們依賴呼叫end方法去執行關閉的處理。
程式碼:
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;所以,web開發者要小心了,除非你想成為webkit容錯程式碼的範例,否則還是寫格式良好的html吧。
------------------------------------下一節,CSS解析(CSS parsing)------------------------------------
<html>
<body>
Hello world
</body>
</html>