
Linux分頁機制之分頁機制的實現詳解--Linux記憶體管理(八)
[注意]
如果您當前使用的系統並不是linux,或者您的系統中只有一份linux原始碼,而您又期待能夠檢視或者檢索不同版本的linux原始碼
LXR (Linux Cross Reference)是比較流行的linux原始碼檢視工具,而這裡集成了全版本的linux原始碼的索引
1 linux的分頁機制
1.1 四級分頁機制
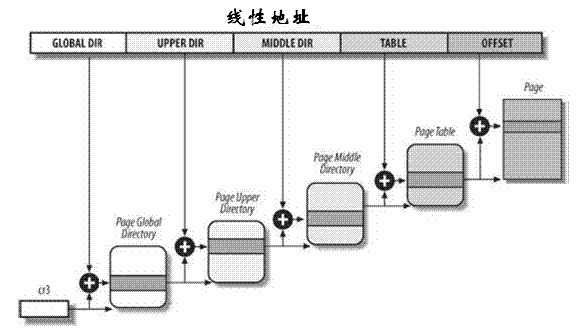
前面我們提到Linux核心僅使用了較少的分段機制,但是卻對分頁機制的依賴性很強,其使用一種適合32位和64位結構的通用分頁模型,該模型使用四級分頁機制,即
- 頁全域性目錄(Page Global Directory)
- 頁上級目錄(Page Upper Directory)
- 頁中間目錄(Page Middle Directory)
- 頁表(Page Table)
- 頁全域性目錄包含若干頁上級目錄的地址;
- 頁上級目錄又依次包含若干頁中間目錄的地址;
- 而頁中間目錄又包含若干頁表的地址;
- 每一個頁表項指向一個頁框。
因此線性地址因此被分成五個部分,而每一部分的大小與具體的計算機體系結構有關。
1.3 不同架構的分頁機制
對於不同的體系結構,Linux採用的四級頁表目錄的大小有所不同:對於i386而言,僅採用二級頁表,即頁上層目錄和頁中層目錄長度為0;對於啟用PAE的i386,採用了三級頁表,即頁上層目錄長度為0;對於64位體系結構,可以採用三級或四級頁表,具體選擇由硬體決定。
對於沒有啟用實體地址擴充套件的32位系統,兩級頁表已經足夠了。從本質上說Linux通過使“頁上級目錄”位和“頁中間目錄”位全為0,徹底取消了頁上級目錄和頁中間目錄欄位。不過,頁上級目錄和頁中間目錄在指標序列中的位置被保留,以便同樣的程式碼在32位系統和64位系統下都能使用。核心為頁上級目錄和頁中間目錄保留了一個位置,這是通過把它們的頁目錄項數設定為1,並把這兩個目錄項對映到頁全域性目錄的一個合適的目錄項而實現的。
啟用了實體地址擴充套件的32 位系統使用了三級頁表。Linux 的頁全域性目錄對應80x86 的頁目錄指標表(PDPT),取消了頁上級目錄,頁中間目錄對應80x86的頁目錄,Linux的頁表對應80x86的頁表。
最終,64位系統使用三級還是四級分頁取決於硬體對線性地址的位的劃分。
1.4 為什麼linux熱衷:分頁>分段
那麼,為什麼Linux是如此地熱衷使用分頁技術而對分段機制表現得那麼地冷淡呢,因為Linux的程序處理很大程度上依賴於分頁。事實上,線性地址到實體地址的自動轉換使下面的設計目標變得可行:
- 給每一個程序分配一塊不同的實體地址空間,這確保了可以有效地防止定址錯誤。
- 區別頁(即一組資料)和頁框(即主存中的實體地址)之不同。這就允許存放在某個頁框中的一個頁,然後儲存到磁碟上,以後重新裝入這同一頁時又被裝在不同的頁框中。這就是虛擬記憶體機制的基本要素。
每一個程序有它自己的頁全域性目錄和自己的頁表集。當發生程序切換時,Linux把cr3控制暫存器的內容儲存在前一個執行程序的描述符中,然後把下一個要執行程序的描述符的值裝入cr3暫存器中。因此,當新程序重新開始在CPU上執行時,分頁單元指向一組正確的頁表。
把線性地址對映到實體地址雖然有點複雜,但現在已經成了一種機械式的任務。
2 linux中頁表處理資料結構
2.1 頁表型別定義pgd_t、pmd_t、pud_t和pte_t
Linux分別採用pgd_t、pmd_t、pud_t和pte_t四種資料結構來表示頁全域性目錄項、頁上級目錄項、頁中間目錄項和頁表項。這四種 資料結構本質上都是無符號長整型unsigned long
Linux為了更嚴格資料型別檢查,將無符號長整型unsigned long分別封裝成四種不同的頁表項。如果不採用這種方法,那麼一個無符號長整型資料可以傳入任何一個與四種頁表相關的函式或巨集中,這將大大降低程式的健壯性。
pgprot_t是另一個64位(PAE啟用時)或32位(PAE禁用時)的資料型別,它表示與一個單獨表項相關的保護標誌。
首先我們檢視一下子這些型別是如何定義的
2.1.1 pteval_t,pmdval_t,pudval_t,pgdval_t
#ifndef __ASSEMBLY__
#include <linux/types.h>
/*
* These are used to make use of C type-checking..
*/
typedef unsigned long pteval_t;
typedef unsigned long pmdval_t;
typedef unsigned long pudval_t;
typedef unsigned long pgdval_t;
typedef unsigned long pgprotval_t;
typedef struct { pteval_t pte; } pte_t;
#endif /* !__ASSEMBLY__ */2.1.2 pgd_t、pmd_t、pud_t和pte_t
typedef struct { pgdval_t pgd; } pgd_t;
static inline pgd_t native_make_pgd(pgdval_t val)
{
return (pgd_t) { val };
}
static inline pgdval_t native_pgd_val(pgd_t pgd)
{
return pgd.pgd;
}
static inline pgdval_t pgd_flags(pgd_t pgd)
{
return native_pgd_val(pgd) & PTE_FLAGS_MASK;
}
#if CONFIG_PGTABLE_LEVELS > 3
typedef struct { pudval_t pud; } pud_t;
static inline pud_t native_make_pud(pmdval_t val)
{
return (pud_t) { val };
}
static inline pudval_t native_pud_val(pud_t pud)
{
return pud.pud;
}
#else
#include <asm-generic/pgtable-nopud.h>
static inline pudval_t native_pud_val(pud_t pud)
{
return native_pgd_val(pud.pgd);
}
#endif
#if CONFIG_PGTABLE_LEVELS > 2
typedef struct { pmdval_t pmd; } pmd_t;
static inline pmd_t native_make_pmd(pmdval_t val)
{
return (pmd_t) { val };
}
static inline pmdval_t native_pmd_val(pmd_t pmd)
{
return pmd.pmd;
}
#else
#include <asm-generic/pgtable-nopmd.h>
static inline pmdval_t native_pmd_val(pmd_t pmd)
{
return native_pgd_val(pmd.pud.pgd);
}
#endif
static inline pudval_t pud_pfn_mask(pud_t pud)
{
if (native_pud_val(pud) & _PAGE_PSE)
return PHYSICAL_PUD_PAGE_MASK;
else
return PTE_PFN_MASK;
}
static inline pudval_t pud_flags_mask(pud_t pud)
{
return ~pud_pfn_mask(pud);
}
static inline pudval_t pud_flags(pud_t pud)
{
return native_pud_val(pud) & pud_flags_mask(pud);
}
static inline pmdval_t pmd_pfn_mask(pmd_t pmd)
{
if (native_pmd_val(pmd) & _PAGE_PSE)
return PHYSICAL_PMD_PAGE_MASK;
else
return PTE_PFN_MASK;
}
static inline pmdval_t pmd_flags_mask(pmd_t pmd)
{
return ~pmd_pfn_mask(pmd);
}
static inline pmdval_t pmd_flags(pmd_t pmd)
{
return native_pmd_val(pmd) & pmd_flags_mask(pmd);
}
static inline pte_t native_make_pte(pteval_t val)
{
return (pte_t) { .pte = val };
}
static inline pteval_t native_pte_val(pte_t pte)
{
return pte.pte;
}
static inline pteval_t pte_flags(pte_t pte)
{
return native_pte_val(pte) & PTE_FLAGS_MASK;
}2.1.4 xxx_val和__xxx
五個型別轉換巨集(_ pte、_ pmd、_ pud、_ pgd和__ pgprot)把一個無符號整數轉換成所需的型別。
另外的五個型別轉換巨集(pte_val,pmd_val, pud_val, pgd_val和pgprot_val)執行相反的轉換,即把上面提到的四種特殊的型別轉換成一個無符號整數。
#define pgd_val(x) native_pgd_val(x)
#define __pgd(x) native_make_pgd(x)
#ifndef __PAGETABLE_PUD_FOLDED
#define pud_val(x) native_pud_val(x)
#define __pud(x) native_make_pud(x)
#endif
#ifndef __PAGETABLE_PMD_FOLDED
#define pmd_val(x) native_pmd_val(x)
#define __pmd(x) native_make_pmd(x)
#endif
#define pte_val(x) native_pte_val(x)
#define __pte(x) native_make_pte(x)這裡需要區別指向頁表項的指標和頁表項所代表的資料。以pgd_t型別為例子,如果已知一個pgd_t型別的指標pgd,那麼通過pgd_val(*pgd)即可獲得該頁表項(也就是一個無符號長整型資料),這裡利用了面向物件的思想。
2.2 頁表描述巨集
| 巨集欄位 | 描述 |
|---|---|
| XXX_SHIFT | 指定Offset欄位的位數 |
| XXX_SIZE | 頁的大小 |
| XXX_MASK | 用以遮蔽Offset欄位的所有位。 |
我們的四級頁表,對應的巨集分別由PAGE,PMD,PUD,PGDIR
| 巨集欄位字首 | 描述 |
|---|---|
| PGDIR | 頁全域性目錄(Page Global Directory) |
| PUD | 頁上級目錄(Page Upper Directory) |
| PMD | 頁中間目錄(Page Middle Directory) |
| PAGE | 頁表(Page Table) |
2.2.1 PAGE巨集–頁表(Page Table)
| 欄位 | 描述 |
|---|---|
| PAGE_SHIFT | 指定Offset欄位的位數 |
| PAGE_SIZE | 頁的大小 |
| PAGE_MASK | 用以遮蔽Offset欄位的所有位。 |
定義如下,在/arch/x86/include/asm/page_types.h 檔案中
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
#define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)
#define PAGE_MASK (~(PAGE_SIZE-1))當用於80x86處理器時,PAGE_SHIFT返回的值為12。
由於頁內所有地址都必須放在Offset欄位, 因此80x86系統的頁的大小PAGE_SIZE是
PAGE_MASK巨集產生的值為0xfffff000,用以遮蔽Offset欄位的所有位。
2.2.2 PMD-Page Middle Directory (頁目錄)
| 欄位 | 描述 |
|---|---|
| PMD_SHIFT | 指定線性地址的Offset和Table欄位的總位數;換句話說,是頁中間目錄項可以對映的區域大小的對數 |
| PMD_SIZE | 用於計算由頁中間目錄的一個單獨表項所對映的區域大小,也就是一個頁表的大小 |
| PMD_MASK | 用於遮蔽Offset欄位與Table欄位的所有位 |
當PAE 被禁用時,PMD_SHIFT 產生的值為22(來自Offset 的12 位加上來自Table 的10 位),
PMD_SIZE 產生的值為222 或 4 MB,
PMD_MASK產生的值為 0xffc00000。
相反,當PAE被啟用時,
PMD_SHIFT 產生的值為21 (來自Offset的12位加上來自Table的9位),
PMD_SIZE 產生的值為
PMD_MASK產生的值為 0xffe00000。
大型頁不使用最後一級頁表,所以產生大型頁尺寸的LARGE_PAGE_SIZE 巨集等於PMD_SIZE(2PMD_SHIFT),而在大型頁地址中用於遮蔽Offset欄位和Table欄位的所有位的LARGE_PAGE_MASK巨集,就等於PMD_MASK。
2.2.3 PUD_SHIFT-頁上級目錄(Page Upper Directory)
| 欄位 | 描述 |
|---|---|
| PUD_SHIFT | 確定頁上級目錄項能對映的區域大小的位數 |
| PUD_SIZE | 用於計算頁全域性目錄中的一個單獨表項所能對映的區域大小。 |
| PUD_MASK | 用於遮蔽Offset欄位,Table欄位,Middle Air欄位和Upper Air欄位的所有位 |
在80x86處理器上,PUD_SHIFT總是等價於PMD_SHIFT,而PUD_SIZE則等於4MB或2MB。
2.2.4 PGDIR_SHIFT-頁全域性目錄(Page Global Directory)
| 欄位 | 描述 |
|---|---|
| PGDIR_SHIFT | 確定頁全域性頁目錄項能對映的區域大小的位數 |
| PGDIR_SIZE | 用於計算頁全域性目錄中一個單獨表項所能對映區域的大小 |
| PGDIR_MASK | 用於遮蔽Offset, Table,Middle Air及Upper Air的所有位 |
當PAE 被禁止時,
PGDIR_SHIFT 產生的值為22(與PMD_SHIFT 和PUD_SHIFT 產生的值相同),
PGDIR_SIZE 產生的值為 222 或 4 MB,
PGDIR_MASK 產生的值為 0xffc00000。
相反,當PAE被啟用時,
PGDIR_SHIFT 產生的值為30 (12 位Offset 加 9 位Table再加 9位 Middle Air),
PGDIR_SIZE 產生的值為230 或 1 GB
PGDIR_MASK產生的值為0xc0000000
PTRS_PER_PTE, PTRS_PER_PMD, PTRS_PER_PUD以及PTRS_PER_PGD
用於計算頁表、頁中間目錄、頁上級目錄和頁全域性目錄表中表項的個數。當PAE被禁止時,它們產生的值分別為1024,1,1和1024。當PAE被啟用時,產生的值分別為512,512,1和4。
2.3 頁表處理函式
核心還提供了許多巨集和函式用於讀或修改頁表表項:
如果相應的表項值為0,那麼,巨集pte_none、pmd_none、pud_none和 pgd_none產生的值為1,否則產生的值為0。
巨集pte_clear、pmd_clear、pud_clear和 pgd_clear清除相應頁表的一個表項,由此禁止程序使用由該頁表項對映的線性地址。ptep_get_and_clear( )函式清除一個頁表項並返回前一個值。
set_pte,set_pmd,set_pud和set_pgd向一個頁表項中寫入指定的值。set_pte_atomic與set_pte作用相同,但是當PAE被啟用時它同樣能保證64位的值能被原子地寫入。
如果a和b兩個頁表項指向同一頁並且指定相同訪問優先順序,pte_same(a,b)返回1,否則返回0。
如果頁中間目錄項指向一個大型頁(2MB或4MB),pmd_large(e)返回1,否則返回0。
巨集pmd_bad由函式使用並通過輸入引數傳遞來檢查頁中間目錄項。如果目錄項指向一個不能使用的頁表,也就是說,如果至少出現以下條件中的一個,則這個巨集產生的值為1:
頁不在主存中(Present標誌被清除)。
頁只允許讀訪問(Read/Write標誌被清除)。
Acessed或者Dirty位被清除(對於每個現有的頁表,Linux總是
強制設定這些標誌)。
pud_bad巨集和pgd_bad巨集總是產生0。沒有定義pte_bad巨集,因為頁表項引用一個不在主存中的頁,一個不可寫的頁或一個根本無法訪問的頁都是合法的。
如果一個頁表項的Present標誌或者Page Size標誌等於1,則pte_present巨集產生的值為1,否則為0。
前面講過頁表項的Page Size標誌對微處理器的分頁部件來講沒有意義,然而,對於當前在主存中卻又沒有讀、寫或執行許可權的頁,核心將其Present和Page Size分別標記為0和1。
這樣,任何試圖對此類頁的訪問都會引起一個缺頁異常,因為頁的Present標誌被清0,而核心可以通過檢查Page Size的值來檢測到產生異常並不是因為缺頁。
如果相應表項的Present標誌等於1,也就是說,如果對應的頁或頁表被裝載入主存,pmd_present巨集產生的值為1。pud_present巨集和pgd_present巨集產生的值總是1。
2.3.1 查詢頁表項中任意一個標誌的當前值
下表中列出的函式用來查詢頁表項中任意一個標誌的當前值;除了pte_file()外,其他函式只有在pte_present返回1的時候,才能正常返回頁表項中任意一個標誌。
| 函式名稱 | 說明 |
|---|---|
| pte_user( ) | 讀 User/Supervisor 標誌 |
| pte_read( ) | 讀 User/Supervisor 標誌(表示 80x86 處理器上的頁不受讀的保護) |
| pte_write( ) | 讀 Read/Write 標誌 |
| pte_exec( ) | 讀 User/Supervisor 標誌( 80x86 處理器上的頁不受程式碼執行的保護) |
| pte_dirty( ) | 讀 Dirty 標誌 |
| pte_young( ) | 讀 Accessed 標誌 |
| pte_file( ) | 讀 Dirty 標誌(當 Present 標誌被清除而 Dirty 標誌被設定時,頁屬於一個非線性磁碟檔案對映) |
2.3.2 設定頁表項中各標誌的值
下表列出的另一組函式用於設定頁表項中各標誌的值
| 函式名稱 | 說明 |
|---|---|
| mk_pte_huge( ) | 設定頁表項中的 Page Size 和 Present 標誌 |
| pte_wrprotect( ) | 清除 Read/Write 標誌 |
| pte_rdprotect( ) | 清除 User/Supervisor 標誌 |
| pte_exprotect( ) | 清除 User/Supervisor 標誌 |
| pte_mkwrite( ) | 設定 Read/Write 標誌 |
| pte_mkread( ) | 設定 User/Supervisor 標誌 |
| pte_mkexec( ) | 設定 User/Supervisor 標誌 |
| pte_mkclean( ) | 清除 Dirty 標誌 |
| pte_mkdirty( ) | 設定 Dirty 標誌 |
| pte_mkold( ) | 清除 Accessed 標誌(把此頁標記為未訪問) |
| pte_mkyoung( ) | 設定 Accessed 標誌(把此頁標記為訪問過) |
| pte_modify(p,v) | 把頁表項 p 的所有訪問許可權設定為指定的值 |
| ptep_set_wrprotect() | 與 pte_wrprotect( ) 類似,但作用於指向頁表項的指標 |
| ptep_set_access_flags( ) | 如果 Dirty 標誌被設定為 1 則將頁的訪問權設定為指定的值,並呼叫flush_tlb_page() 函式 |
| ptep_mkdirty() | 與 pte_mkdirty( ) 類似,但作用於指向頁表項的指標。 |
| ptep_test_and_clear_dirty( ) | 與 pte_mkclean( ) 類似,但作用於指向頁表項的指標並返回 Dirty 標誌的舊值 |
| ptep_test_and_clear_young( ) | 與 pte_mkold( ) 類似,但作用於指向頁表項的指標並返回 Accessed標誌的舊值 |
2.3.3 巨集函式-把一個頁地址和一組保護標誌組合成頁表項,或者執行相反的操作
現在,我們來討論下表中列出的巨集,它們把一個頁地址和一組保護標誌組合成頁表項,或者執行相反的操作,從一個頁表項中提取出頁地址。請注意這其中的一些巨集對頁的引用是通過 “頁描述符”的線性地址,而不是通過該頁本身的線性地址。
| 巨集名稱 | 說明 |
|---|---|
| pgd_index(addr) | 找到線性地址 addr 對應的的目錄項在頁全域性目錄中的索引(相對位置) |
| pgd_offset(mm, addr) | 接收記憶體描述符地址 mm 和線性地址 addr 作為引數。這個巨集產生地址addr 在頁全域性目錄中相應表項的線性地址;通過記憶體描述符 mm 內的一個指標可以找到這個頁全域性目錄 |
| pgd_offset_k(addr) | 產生主核心頁全域性目錄中的某個項的線性地址,該項對應於地址 addr |
| pgd_page(pgd) | 通過頁全域性目錄項 pgd 產生頁上級目錄所在頁框的頁描述符地址。在兩級或三級分頁系統中,該巨集等價於 pud_page() ,後者應用於頁上級目錄項 |
| pud_offset(pgd, addr) | 引數為指向頁全域性目錄項的指標 pgd 和線性地址 addr 。這個巨集產生頁上級目錄中目錄項 addr 對應的線性地址。在兩級或三級分頁系統中,該巨集產生 pgd ,即一個頁全域性目錄項的地址 |
| pud_page(pud) | 通過頁上級目錄項 pud 產生相應的頁中間目錄的線性地址。在兩級分頁系統中,該巨集等價於 pmd_page() ,後者應用於頁中間目錄項 |
| pmd_index(addr) | 產生線性地址 addr 在頁中間目錄中所對應目錄項的索引(相對位置) |
| pmd_offset(pud, addr) | 接收指向頁上級目錄項的指標 pud 和線性地址 addr 作為引數。這個巨集產生目錄項 addr 在頁中間目錄中的偏移地址。在兩級或三級分頁系統中,它產生 pud ,即頁全域性目錄項的地址 |
| pmd_page(pmd) | 通過頁中間目錄項 pmd 產生相應頁表的頁描述符地址。在兩級或三級分頁系統中, pmd 實際上是頁全域性目錄中的一項 |
| mk_pte(p,prot) | 接收頁描述符地址 p 和一組訪問許可權 prot 作為引數,並建立相應的頁表項 |
| pte_index(addr) | 產生線性地址 addr 對應的表項在頁表中的索引(相對位置) |
| pte_offset_kernel(dir,addr) | 線性地址 addr 在頁中間目錄 dir 中有一個對應的項,該巨集就產生這個對應項,即頁表的線性地址。另外,該巨集只在主核心頁表上使用 |
| pte_offset_map(dir, addr) | 接收指向一個頁中間目錄項的指標 dir 和線性地址 addr 作為引數,它產生與線性地址 addr 相對應的頁表項的線性地址。如果頁表被儲存在高階儲存器中,那麼核心建立一個臨時核心對映,並用 pte_unmap 對它進行釋放。 pte_offset_map_nested 巨集和 pte_unmap_nested 巨集是相同的,但它們使用不同的臨時核心對映 |
| pte_page( x ) | 返回頁表項 x 所引用頁的描述符地址 |
| pte_to_pgoff( pte ) | 從一個頁表項的 pte 欄位內容中提取出檔案偏移量,這個偏移量對應著一個非線性檔案記憶體對映所在的頁 |
| pgoff_to_pte(offset ) | 為非線性檔案記憶體對映所在的頁建立對應頁表項的內容 |
2.3.4 簡化頁表項的建立和撤消
下面我們羅列最後一組函式來簡化頁表項的建立和撤消。當使用兩級頁表時,建立或刪除一個頁中間目錄項是不重要的。如本節前部分所述,頁中間目錄僅含有一個指向下屬頁表的目錄項。所以,頁中間目錄項只是頁全域性目錄中的一項而已。然而當處理頁表時,建立一個頁表項可能很複雜,因為包含頁表項的那個頁表可能就不存在。在這樣的情況下,有必要分配一個新頁框,把它填寫為 0 ,並把這個表項加入。
如果 PAE 被啟用,核心使用三級頁表。當核心建立一個新的頁全域性目錄時,同時也分配四個相應的頁中間目錄;只有當父頁全域性目錄被釋放時,這四個頁中間目錄才得以釋放。當使用兩級或三級分頁時,頁上級目錄項總是被對映為頁全域性目錄中的一個單獨項。與以往一樣,下表中列出的函式描述是針對 80x86 構架的。
| 函式名稱 | 說明 |
|---|---|
| pgd_alloc( mm ) | 分配一個新的頁全域性目錄。如果 PAE 被啟用,它還分配三個對應使用者態線性地址的子頁中間目錄。引數 mm( 記憶體描述符的地址 )在 80x86 構架上被忽略 |
| pgd_free( pgd) | 釋放頁全域性目錄中地址為 pgd 的項。如果 PAE 被啟用,它還將釋放使用者態線性地址對應的三個頁中間目錄 |
| pud_alloc(mm, pgd, addr) | 在兩級或三級分頁系統下,這個函式什麼也不做:它僅僅返回頁全域性目錄項 pgd 的線性地址 |
| pud_free(x) | 在兩級或三級分頁系統下,這個巨集什麼也不做 |
| pmd_alloc(mm, pud, addr) | 定義這個函式以使普通三級分頁系統可以為線性地址 addr 分配一個新的頁中間目錄。如果 PAE 未被啟用,這個函式只是返回輸入引數 pud 的值,也就是說,返回頁全域性目錄中目錄項的地址。如果 PAE 被啟用,該函式返回線性地址 addr 對應的頁中間目錄項的線性地址。引數 mm 被忽略 |
| pmd_free(x) | 該函式什麼也不做,因為頁中間目錄的分配和釋放是隨同它們的父全域性目錄一同進行的 |
| pte_alloc_map(mm, pmd, addr) | 接收頁中間目錄項的地址 pmd 和線性地址 addr 作為引數,並返回與 addr 對應的頁表項的地址。如果頁中間目錄項為空,該函式通過呼叫函式 pte_alloc_one( ) 分配一個新頁表。如果分配了一個新頁表, addr 對應的項就被建立,同時 User/Supervisor 標誌被設定為 1 。如果頁表被儲存在高階記憶體,則核心建立一個臨時核心對映,並用 pte_unmap 對它進行釋放 |
| pte_alloc_kernel(mm, pmd, addr) | 如果與地址 addr 相關的頁中間目錄項 pmd 為空,該函式分配一個新頁表。然後返回與 addr 相關的頁表項的線性地址。該函式僅被主核心頁表使用 |
| pte_free(pte) | 釋放與頁描述符指標 pte 相關的頁表 |
| pte_free_kernel(pte) | 等價於 pte_free( ) ,但由主核心頁表使用 |
| clear_page_range(mmu, start,end) | 從線性地址 start 到 end 通過反覆釋放頁表和清除頁中間目錄項來清除程序頁表的內容 |
3 線性地址轉換
3.1 分頁模式下的的線性地址轉換
線性地址、頁表和頁表項線性地址不管系統採用多少級分頁模型,線性地址本質上都是索引+偏移量的形式,甚至你可以將整個線性地址看作N+1個索引的組合,N是系統採用的分頁級數。在四級分頁模型下,線性地址被分為5部分,如下圖:
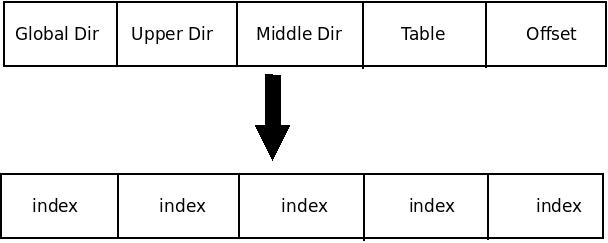
線上性地址中,每個頁表索引即代表線性地址在對應級別的頁表中中關聯的頁表項。正是這種索引與頁表項的對應關係形成了整個頁表對映機制。
3.1.1 頁表
多個頁表項的集合則為頁表,一個頁表內的所有頁表項是連續存放的。頁表本質上是一堆資料,因此也是以頁為單位存放在主存中的。因此,在虛擬地址轉化物理實體地址的過程中,每訪問一級頁表就會訪問一次記憶體。
3.1.2 頁表項
頁表項從四種頁表項的資料結構可以看出,每個頁表項其實就是一個無符號長整型資料。每個頁表項分兩大類資訊:頁框基地址和頁的屬性資訊。在x86-32體系結構中,每個頁表項的結構圖如下:
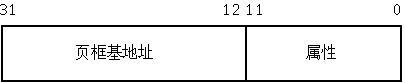
這個圖是一個通用模型,其中頁表項的前20位是物理頁的基地址。由於32位的系統採用4kb大小的 頁,因此每個頁表項的後12位均為0。核心將後12位充分利用,每個位都表示對應虛擬頁的相關屬性。
不管是那一級的頁表,它的功能就是建立虛擬地址和實體地址之間的對映關係,一個頁和一個頁框之間的對映關係體現在頁表項中。上圖中的物理頁基地址是 個抽象的說明,如果當前的頁表項位於頁全域性目錄中,這個物理頁基址是指頁上級目錄所在物理頁的基地址;如果當前頁表項位於頁表中,這個物理頁基地址是指最 終要訪問資料所在物理頁的基地址。
3.1.3 地址轉換過程
地址轉換過程有了上述的基本知識,就很好理解四級頁表模式下如何將虛擬地址轉化為邏輯地址了。基本過程如下:
1.從CR3暫存器中讀取頁目錄所在物理頁面的基址(即所謂的頁目錄基址),從線性地址的第一部分獲取頁目錄項的索引,兩者相加得到頁目錄項的實體地址。
2.第一次讀取記憶體得到pgd_t結構的目錄項,從中取出物理頁基址取出(具體位數與平臺相關,如果是32系統,則為20位),即頁上級頁目錄的物理基地址。
3.從線性地址的第二部分中取出頁上級目錄項的索引,與頁上級目錄基地址相加得到頁上級目錄項的實體地址。
4.第二次讀取記憶體得到pud_t結構的目錄項,從中取出頁中間目錄的物理基地址。
5.從線性地址的第三部分中取出頁中間目錄項的索引,與頁中間目錄基址相加得到頁中間目錄項的實體地址。
6.第三次讀取記憶體得到pmd_t結構的目錄項,從中取出頁表的物理基地址。
7.從線性地址的第四部分中取出頁表項的索引,與頁表基址相加得到頁表項的實體地址。
8.第四次讀取記憶體得到pte_t結構的目錄項,從中取出物理頁的基地址。
9.從線性地址的第五部分中取出物理頁內偏移量,與物理頁基址相加得到最終的實體地址。
10.第五次讀取記憶體得到最終要訪問的資料。
整個過程是比較機械的,每次轉換先獲取物理頁基地址,再從線性地址中獲取索引,合成物理地址後再訪問記憶體。不管是頁表還是要訪問的資料都是以頁為單 位存放在主存中的,因此每次訪問記憶體時都要先獲得基址,再通過索引(或偏移)在頁內訪問資料,因此可以將線性地址看作是若干個索引的集合。
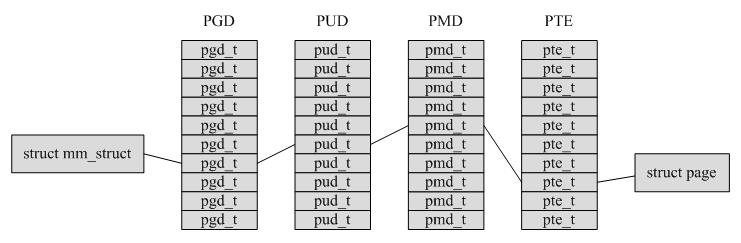
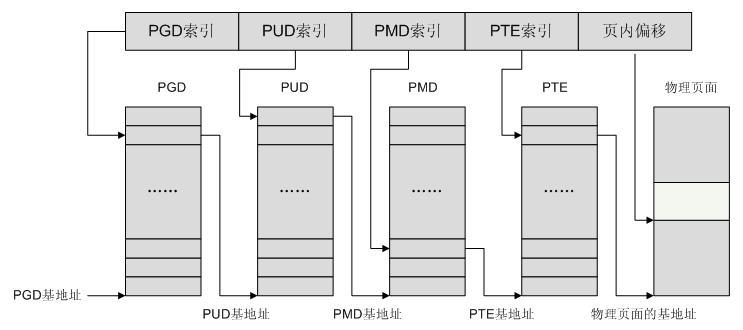
3.2 Linux中通過4級頁表訪問實體記憶體
linux中每個程序有它自己的PGD( Page Global Directory),它是一個物理頁,幷包含一個pgd_t陣列。
程序的pgd_t資料見 task_struct -> mm_struct -> pgd_t * pgd;
PTEs, PMDs和PGDs分別由pte_t, pmd_t 和pgd_t來描述。為了儲存保護位,pgprot_t被定義,它擁有相關的flags並經常被儲存在page table entry低位(lower bits),其具體的儲存方式依賴於CPU架構。
前面我們講了頁表處理的大多數函式資訊,在上面我們又講了線性地址如何轉換為實體地址,其實就是不斷索引的過程。
通過如下幾個函式,不斷向下索引,就可以從程序的頁表中搜索特定地址對應的頁面物件
| 巨集函式 | 說明 |
|---|---|
| pgd_offset | 根據當前虛擬地址和當前程序的mm_struct獲取pgd項 |
| pud_offset | 引數為指向頁全域性目錄項的指標 pgd 和線性地址 addr 。這個巨集產生頁上級目錄中目錄項 addr 對應的線性地址。在兩級或三級分頁系統中,該巨集產生 pgd ,即一個頁全域性目錄項的地址 |
| pmd_offset | 根據通過pgd_offset獲取的pgd 項和虛擬地址,獲取相關的pmd項(即pte表的起始地址) |
| pte_offset | 根據通過pmd_offset獲取的pmd項和虛擬地址,獲取相關的pte項(即物理頁的起始地址) |
根據虛擬地址獲取物理頁的示例程式碼詳見mm/memory.c中的函式follow_page
不同的版本可能有所不同,早起核心中存在follow_page,而後來的核心中被follow_page_mask替代,目前最新的釋出4.4中為查詢到此函式
我們從早期的linux-3.8的原始碼中, 擷取的程式碼如下
/**
* follow_page - look up a page descriptor from a user-virtual address
* @vma: vm_area_struct mapping @address
* @address: virtual address to look up
* @flags: flags modifying lookup behaviour
*
* @flags can have FOLL_ flags set, defined in <linux/mm.h>
*
* Returns the mapped (struct page *), %NULL if no mapping exists, or
* an error pointer if there is a mapping to something not represented
* by a page descriptor (see also vm_normal_page()).
*/
struct page *follow_page(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *ptep, pte;
spinlock_t *ptl;
struct page *page;
struct mm_struct *mm = vma->vm_mm;
page = follow_huge_addr(mm, address, flags & FOLL_WRITE);
if (!IS_ERR(page)) {
BUG_ON(flags & FOLL_GET);
goto out;
}
page = NULL;
pgd = pgd_offset(mm, address);
if (pgd_none(*pgd) || unlikely(pgd_bad(*pgd)))
goto no_page_table;
pud = pud_offset(pgd, address);
if (pud_none(*pud))
goto no_page_table;
if (pud_huge(*pud) && vma->vm_flags & VM_HUGETLB) {
BUG_ON(flags & FOLL_GET);
page = follow_huge_pud(mm, address, pud, flags & FOLL_WRITE);
goto out;
}
if (unlikely(pud_bad(*pud)))
goto no_page_table;
pmd = pmd_offset(pud, address);
if (pmd_none(*pmd))
goto no_page_table;
if (pmd_huge(*pmd) && vma->vm_flags & VM_HUGETLB) {
BUG_ON(flags & FOLL_GET);
page = follow_huge_pmd(mm, address, pmd, flags & FOLL_WRITE);
goto out;
}
if (pmd_trans_huge(*pmd)) {
if (flags & FOLL_SPLIT) {
split_huge_page_pmd(mm, pmd);
goto split_fallthrough;
}
spin_lock(&mm->page_table_lock);
if (likely(pmd_trans_huge(*pmd))) {
if (unlikely(pmd_trans_splitting(*pmd))) {
spin_unlock(&mm->page_table_lock);
wait_split_huge_page(vma->anon_vma, pmd);
} else {
page = follow_trans_huge_pmd(mm, address,
pmd, flags);
spin_unlock(&mm->page_table_lock);
goto out;
}
} else
spin_unlock(&mm->page_table_lock);
/* fall through */
}
split_fallthrough:
if (unlikely(pmd_bad(*pmd)))
goto no_page_table;
ptep = pte_offset_map_lock(mm, pmd, address, &ptl);
pte = *ptep;
if (!pte_present(pte))
goto no_page;
if ((flags & FOLL_WRITE) && !pte_write(pte))
goto unlock;
page = vm_normal_page(vma, address, pte);
if (unlikely(!page)) {
if ((flags & FOLL_DUMP) ||
!is_zero_pfn(pte_pfn(pte)))
goto bad_page;
page = pte_page(pte);
}
if (flags & FOLL_GET)
get_page(page);
if (flags & FOLL_TOUCH) {
if ((flags & FOLL_WRITE) &&
!pte_dirty(pte) && !PageDirty(page))
set_page_dirty(page);
/*
* pte_mkyoung() would be more correct here, but atomic care
* is needed to avoid losing the dirty bit: it is easier to use
* mark_page_accessed().
*/
mark_page_accessed(page);
}
if ((flags & FOLL_MLOCK) && (vma->vm_flags & VM_LOCKED)) {
/*
* The preliminary mapping check is mainly to avoid the
* pointless overhead of lock_page on the ZERO_PAGE
* which might bounce very badly if there is contention.
*
* If the page is already locked, we don't need to
* handle it now - vmscan will handle it later if and
* when it attempts to reclaim the page.
*/
if (page->mapping && trylock_page(page)) {
lru_add_drain(); /* push cached pages to LRU */
/*
* Because we lock page here and migration is
* blocked by the pte's page reference, we need
* only check for file-cache page truncation.
*/
if (page->mapping)
mlock_vma_page(page);
unlock_page(page);
}
}
unlock:
pte_unmap_unlock(ptep, ptl);
out:
return page;
bad_page:
pte_unmap_unlock(ptep, ptl);
return ERR_PTR(-EFAULT);
no_page:
pte_unmap_unlock(ptep, ptl);
if (!pte_none(pte))
return page;
no_page_table:
/*
* When core dumping an enormous anonymous area that nobody
* has touched so far, we don't want to allocate unnecessary pages or
* page tables. Return error instead of NULL to skip handle_mm_fault,
* then get_dump_page() will return NULL to leave a hole in the dump.
* But we can only make this optimization where a hole would surely
* be zero-filled if handle_mm_fault() actually did handle it.
*/
if ((flags & FOLL_DUMP) &&
(!vma->vm_ops || !vma->vm_ops->fault))
return ERR_PTR(-EFAULT);
return page;
}以上程式碼可以精簡為
unsigned long v2p(int pid unsigned long va)
{
unsigned long pa = 0;
struct task_struct *pcb_tmp = NULL;
pgd_t *pgd_tmp = NULL;
pud_t *pud_tmp = NULL;
pmd_t *pmd_tmp = NULL;
pte_t *pte_tmp = NULL;
printk(KERN_INFO"PAGE_OFFSET = 0x%lx\n",PAGE_OFFSET);
printk(KERN_INFO"PGDIR_SHIFT = %d\n",PGDIR_SHIFT);
printk(KERN_INFO"PUD_SHIFT = %d\n",PUD_SHIFT);
printk(KERN_INFO"PMD_SHIFT = %d\n",PMD_SHIFT);
printk(KERN_INFO"PAGE_SHIFT = %d\n",PAGE_SHIFT);
printk(KERN_INFO"PTRS_PER_PGD = %d\n",PTRS_PER_PGD);
printk(KERN_INFO"PTRS_PER_PUD = %d\n",PTRS_PER_PUD);
printk(KERN_INFO"PTRS_PER_PMD = %d\n",PTRS_PER_PMD);
printk(KERN_INFO"PTRS_PER_PTE = %d\n",PTRS_PER_PTE);
printk(KERN_INFO"PAGE_MASK = 0x%lx\n",PAGE_MASK);
//if(!(pcb_tmp = find_task_by_pid(pid)))
if(!(pcb_tmp = findTaskByPid(pid)))
{
printk(KERN_INFO"Can't find the task %d .\n",pid);
return 0;
}
printk(KERN_INFO"pgd = 0x%p\n",pcb_tmp->mm->pgd);
/* 判斷給出的地址va是否合法(va<vm_end)*/
if(!find_vma(pcb_tmp->mm,va))
{
printk(KERN_INFO"virt_addr 0x%lx not available.\n",va);
return 0;
}
pgd_tmp = pgd_offset(pcb_tmp->mm,va);
printk(KERN_INFO"pgd_tmp = 0x%p\n",pgd_tmp);
printk(KERN_INFO"pgd_val(*pgd_tmp) = 0x%lx\n",pgd_val(*pgd_tmp));
if(pgd_none(*pgd_tmp))
{
printk(KERN_INFO"Not mapped in pgd.\n");
return 0;
}
pud_tmp = pud_offset(pgd_tmp,va);
printk(KERN_INFO"pud_tmp = 0x%p\n",pud_tmp);
printk(KERN_INFO"pud_val(*pud_tmp) = 0x%lx\n",pud_val(*pud_tmp));
if(pud_none(*pud_tmp))
{
printk(KERN_INFO"Not mapped in pud.\n");
return 0;
}
pmd_tmp = pmd_offset(pud_tmp,va);
printk(KERN_INFO"pmd_tmp = 0x%p\n",pmd_tmp);
printk(KERN_INFO"pmd_val(*pmd_tmp) = 0x%lx\n",pmd_val(*pmd_tmp));
if(pmd_none(*pmd_tmp))
{
printk(KERN_INFO"Not mapped in pmd.\n");
return 0;
}
/*在這裡,把原來的pte_offset_map()改成了pte_offset_kernel*/
pte_tmp = pte_offset_kernel(pmd_tmp,va);
printk(KERN_INFO"pte_tmp = 0x%p\n",pte_tmp);
printk(KERN_INFO"pte_val(*pte_tmp) = 0x%lx\n",pte_val(*pte_tmp));
if(pte_none(*pte_tmp))
{
printk(KERN_INFO"Not mapped in pte.\n");
return 0;
}
if(!pte_present(*pte_tmp)){
printk(KERN_INFO"pte not in RAM.\n");
return 0;
}
pa = (pte_val(*pte_tmp) & PAGE_MASK) | (va & ~PAGE_MASK);
printk(KERN_INFO"virt_addr 0x%lx in RAM is 0x%lx t .\n",va,pa);
printk(KERN_INFO"contect in 0x%lx is 0x%lx\n", pa, *(unsigned long *)((char *)pa + PAGE_OFFSET)
}