
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
摘要:在本文中,我們提出了一種新的神經網路模型,稱為RNN編碼器 - 解碼器,由兩個遞迴神經網路(RNN)組成。一個RNN編碼器將特徵編碼為一個固定長度的向量,另一個解碼器解碼這個向量為另一個符號序列。聯合訓練所提出的模型的編碼器和解碼器以最大化給定源序列的目標序列的條件概率。通過使用由RNN編碼器 - 解碼器計算的短語對的條件概率作為現有對數線性模型中的附加特徵,相較於統計機器翻譯系統的效能得到改善。定性地,我們表明所提出的模型學習表達到了短語的語義和語法。
1.introduction
深度神經網路已經在很多應用中取得了成功,比如在語音識別和目標檢測上。此外,許多最近的工作表明神經網路可以成功地用於自然語言處理(NLP)中的許多工。這些包括但不限於語言建模(Bengio等,2003),複述檢測(Socher等,2011)和單詞嵌入提取(Mikolov等,2013)。在統計機器翻譯(SMT)領域,深度神經網路已經開始顯示出有希望的結果。(Schwenk,2012)總結了基於短語的SMT系統框架中前饋神經網路的成功應用。
通過對SMT使用神經網路的這一研究,本文重點研究了一種新的神經網路結構,可以作為傳統的基於短語的SMT系統的一部分。提出的神經網路結構,我們將其稱為 RNN編碼器 - 解碼器由兩個遞迴神經網路(RNN)組成,它們充當編碼器和解碼器對。 編碼器將可變長度源序列對映到固定長度向量,並且解碼器將矢量表示映射回可變長度目標序列。 聯合訓練兩個網路以最大化給定源序列的目標序列的條件概率。 此外,我們建議使用相當複雜的隱藏單元,以提高記憶體容量和培訓的便利性。
所提出的具有新穎隱藏單元的RNN編碼器 - 解碼器根據從英語到法語的翻譯任務進行經驗評估。 我們訓練模型以學習英語短語的翻譯概率到相應的法語短語。 然後,通過對短語表中的每個短語對進行評分,將該模型用作基於標準短語的SMT系統的一部分。 經驗評估表明,這種使用RNN編碼器 - 解碼器對短語對進行評分的方法提高了翻譯效能。
我們通過比較其短語得分與現有翻譯模型給出的那些,定性地分析訓練的RNN編碼器 - 解碼器。 定性分析表明,RNN編碼器 - 解碼器更好地捕捉短語表中的語言規律,間接解釋了整體翻譯效能的定量改進。 對模型的進一步分析表明,RNN編碼器 - 解碼器學習了一個短語的連續空間表示,該短語保留了短語的語義和句法結構。
2RNN Encoder–Decoder
2.1Preliminary: Recurrent Neural Networks
遞迴神經網路(RNN)是神經網路,其由隱藏狀態h和可選輸出y組成,其在可變長度序列x =(x 1,...,x T)上操作。 在每個時間步t,RNN中的隱藏單元h(t)被以以下方式進行更新:
![]()
其中f是非線性啟用函式。 f可以像元素邏輯sigmoid函式一樣簡單,也可以像長短期記憶(LSTM)單元一樣複雜(Hochreiter和Schmidhuber,1997)。
RNN可以通過訓練來預測序列中的下一個符號來學習序列上的概率分佈。 在這種情況下,每個時間步t的輸出是條件分佈p(x t | x t-1,...,x 1)。 例如,可以使用softmax啟用函式輸出多項分佈(1-of-K編碼)

對於所有可能的符號j = 1 ,.。。 ,K,其中w j是權重矩陣W的行。通過組合這些概率,我們可以計算序列x的概率。
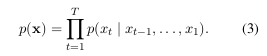
通過這種學習的分佈,通過在每個時間步迭代地對符號進行取樣,可以直接對新序列進行取樣。
2.2 RNN Encoder–Decoder.
在本文中,我們提出了一種新穎的神經網路體系結構,它學習將可變長度序列編碼為固定長度的矢量表示,並將給定的固定長度矢量表示解碼回可變長度序列。 從概率的角度來看,這種新模型是學習在另一個可變長度序列條件下的可變長度序列上的條件分佈的一般方法,例如, p(y 1,...,y T 0 | x 1,...,x T),其中應注意輸入和輸出序列長度T和T 0可能不同。

編碼器是RNN,其順序地讀取輸入序列x的每個符號。 當它讀取每個符號時,RNN的隱藏狀態根據等式1而變化。(1)。 在讀取序列的結尾(由序列結束符號標記)之後,RNN的隱藏狀態是整個輸入序列的摘要c。
所提出的模型的解碼器是另一個RNN,其被訓練以通過在給定隱藏狀態h(t)的情況下預測下一個符號y t來生成輸出序列。 但是,與第二節中描述的RNN不同。 在圖2.1中,y t和ht也都以y t-1和輸入序列的彙總c為條件。 因此,解碼器在時間t的隱藏狀態由下式計算:
![]()
並且類似地,下一個符號的條件分佈是:
![]()
對於給定的啟用函式f和g(後者必須產生有效概率,例如使用softmax)。
有關所提出的模型架構的圖形描述,請參見圖1。
所提出的RNN編碼器 - 解碼器的兩個元件被聯合訓練以最大化條件對數似然:

其中θ是模型引數的集合,並且每個(x n,y n)是來自訓練集的(輸入序列,輸出序列)對。 在我們的例子中,由於解碼器的輸出從輸入開始是可微分的,我們可以使用基於梯度的演算法來估計模型引數。
一旦訓練了RNN編碼器 - 解碼器,就可以以兩種方式使用該模型。 一種方法是使用該模型在給定輸入序列的情況下生成目標序列。 另一方面,該模型可用於對給定的輸入和輸出序列對進行評分,其中得分就像概率pθ(y | x)一樣來自於公式(3)和(4)。
2.3 Hidden Unit that Adaptively Remembers and Forgets
除了新穎的模型架構之外,我們還提出了一種新型的隱藏單元(方程(1)中的f),該單元由LSTM單元激勵,但計算和實現起來要簡單得多。 1圖2顯示了所提出的隱藏單元的圖形描述。

讓我們描述如何計算第j個隱藏單元的啟用。 首先,通過計算復位門r j:
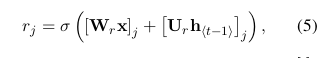
其中σ是邏輯sigmoid函式,[。] j表示向量的第j個元素。 x和h t-1分別是輸入和先前的隱藏狀態。 W r和U r是學習的權重矩陣。
類似地,更新門z j由計算:

然後通過計算所提出的單位h j的實際啟用
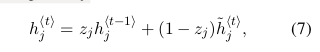
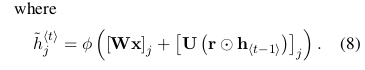
在該公式中,當復位門接近0時,強制隱藏狀態忽略先前的隱藏狀態並僅用當前輸入復位。 這有效地允許隱藏狀態丟棄在將來稍後發現不相關的任何資訊,從而允許更緊湊的表示。
另一方面,更新門控制來自先前隱藏狀態的多少資訊將轉移到當前隱藏狀態。 這類似於LSTM網路中的儲存器單元,並幫助RNN記住長期資訊。 此外,這可以被認為是洩漏整合單元的自適應變體(Bengio等,2013)。
由於每個隱藏單元具有單獨的重置和更新門,每個隱藏單元將學習捕獲不同時間尺度上的依賴性。 學習捕獲短期依賴關係的那些單元將傾向於重置經常活動的門,但那些捕獲長期依賴關係的那些將具有主要是活動的更新門。
在我們的初步實驗中,我們發現使用帶有澆口裝置的新裝置至關重要。 我們無法通過經常使用的tanh裝置獲得有意義的結果而沒有任何門控。
3 Statistical Machine Translation
在常用的統計機器翻譯系統(SMT)中,系統的目標(具體地說是解碼器)是在給定源句e的情況下找到翻譯f,最大化:
![]()
其中右手側的第一項稱為翻譯模型,後一種稱為語言模型(例如,(Koehn,2005))。 然而,在實踐中,大多數SMT系統將log p(f | e)建模為具有附加特徵和相應權重的對數線性模型:
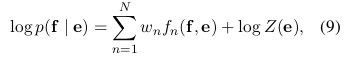
其中f n和w n分別是第n個特徵和權重。 Z(e)是不依賴於權重的歸一化常數。 通常優化權重以最大化開發集上的BLEU分數。
在(Koehn等,2003)和(Marcu和Wong,2002)中引入的基於短語的SMT框架中,將翻譯模型log p(e | f)分解為源和目標中匹配短語的翻譯概率。這些概率再次被認為是對數線性模型中的附加特徵(參見方程(9))並且相應地加權以最大化BLEU得分。
由於神經網路語言模型(Bengio et al。,2003)提出,神經網路已廣泛應用於SMT系統。 在許多情況下,神經網路已被用於重新構建翻譯假設(n-最佳列表)(參見,例如,(Schwenk等人,2006))。 然而,最近,人們對訓練神經網路感興趣
使用源句子的表示作為附加輸入來對翻譯的句子(或短語對)進行評分。 參見,例如,(Schwenk,2012),(Son等人,2012)和(Zou等人,2013)。
3.1 Scoring Phrase Pairs with RNN Encoder–Decoder
在這裡,我們提出在短語對錶上訓練RNN編碼器 - 解碼器(參見2.2節),並將其得分作為方程中對數線性模型的附加特徵(9)當調節SMT解碼器時。
當我們訓練RNN編碼器 - 解碼器時,我們忽略原始語料庫中每個短語對的(標準化的)頻率。 採取該措施(1)以減少根據歸一化頻率從大短語表中隨機選擇短語對的計算開銷,以及(2)確保RNN編碼器 - 解碼器不僅僅學習對短語對進行排序 根據他們的出現次數。 這種選擇的一個潛在原因是短語表中的現有翻譯概率已經反映了原始語料庫中短語對的頻率。 利用RNN編碼器 - 解碼器的固定容量,我們嘗試確保模型的大部分容量專注於學習語言規律,即區分合理和難以置信的翻譯,或學習“流形”(概率集中區域) )合理的翻譯。
一旦訓練了RNN編碼器 - 解碼器,我們就為每個短語對新增到現有短語表的新分數。 這允許新分數進入現有調整演算法,而計算中的額外開銷最小。
正如Schwenk在(Schwenk,2012)中指出的那樣,可以用提出的RNN編碼器 - 解碼器完全替換現有的短語表。 在這種情況下,對於給定的源短語,RNN編碼器 - 解碼器將需要生成(好的)目標短語的列表。 然而,這需要重複執行昂貴的取樣程式。 因此,在本文中,我們只考慮在短語表中重新標記短語對。
3.2Related Approaches: Neural Networks in Machine Translation
在介紹實驗結果之前,我們討論了一些最近提出的在SMT背景下使用神經網路的工作。
Schwenk(Schwenk,2012)提出了一種類似的評分短語對的方法。 他沒有使用基於RNN的神經網路,而是使用前饋神經網路,該網路具有固定大小的輸入(在他的情況下為7個字,對於較短的短語具有零填充)和固定大小的輸出(目標語言中的7個字)。 當它專門用於SMT系統的評分短語時,通常選擇最大短語長度較小。 然而,隨著短語的長度增加或者當我們將神經網路應用於其他可變長度序列資料時,神經網路可以處理可變長度的輸入和輸出是很重要的。 所提出的RNN編碼器 - 解碼器非常適合這些應用。
類似於(Schwenk,2012),Devlin等人(Devlin等人,2014)提出使用前饋神經網路來建模翻譯模型,然而,通過一次預測目標短語中的一個單詞。 他們報告了一個令人印象深刻的改進,但他們的方法仍然需要輸入短語(或上下文單詞)的最大長度
先驗地固定。
雖然它不是他們訓練的神經網路,但是(Zou等人,2013)的作者提出要學習單詞/短語的雙語嵌入。 他們使用學習嵌入來計算一對短語之間的距離,這對短語用作SMT系統中短語對的附加分數。
在(Chandar等人,2014)中,訓練前饋神經網路以學習從輸入短語的詞袋錶示到輸出短語的對映。 這與提出的RNN編碼器 - 解碼器和模型密切相關
在(Schwenk,2012)中提出,除了他們對短語的輸入表示是一個詞袋之外。在(Gao等人,2013)中也提出了使用詞袋錶示的類似方法。 早些時候,在(Socher等人,2011)中提出了使用兩個遞迴神經網路的類似編碼器 - 解碼器模型,但是他們的模型被限制為單語設定,即模型重建輸入句子。 最近,在(Auli等人,2013)中提出了另一種使用RNN的編碼器 - 解碼器模型,其中解碼器以源句子或源上下文的表示為條件。
所提出的RNN編碼器 - 解碼器與(Zou等人,2013)和(Chandar等人,2014)中的方法之間的一個重要區別在於考慮了源和目標短語中的單詞的順序。 RNN編碼器 - 解碼器自然地區分具有相同字但序列不同的序列,而上述方法忽略了順序資訊。
與提出的RNN編碼器 - 解碼器相關的最接近的方法是(Kalchbrenner和Blunsom,2013)中提出的迴圈連續轉換模型(模型2)。 在他們的論文中,他們提出了一個由編碼器和解碼器組成的類似模型。 與我們的模型的不同之處在於它們使用卷積n-gram模型(CGM)用於編碼器以及逆CGM和用於解碼器的遞迴神經網路的混合。 然而,他們評估了他們的模型,重新評估了傳統SMT系統提出的n-最佳列表,並計算了金標準翻譯的困惑。
4 Experiments
我們評估了WMT'14研討會英語/法語翻譯任務的方法。
4.1 Data and Baseline System
在WMT'14翻譯任務的框架內,可以利用大量資源建立英語/法語SMT系統。 雙語語料庫包括Europarl(61M字),新聞評論(5.5M),UN(421M),以及兩個90M和780M字的爬行語料庫。最後兩個語料庫非常嘈雜。 為了訓練法語模型,除了位元的目標側之外,還有大約712M字的爬行報紙材料。 所有單詞計數都是指在標記化之後的法語單詞。
人們普遍認為,在所有這些資料的串聯上訓練統計模型不一定會導致最佳效能,並導致難以處理的極大模型。 相反,應該關注給定任務的最相關資料子集。 我們通過應用(Moore和Lewis,2010)中提出的資料選擇方法及其對bitexts的擴充套件(Axelrod等,2011)來實現。 通過這些方法,我們從用於語言建模的2G字以上的418M字的子集中選擇了用於訓練RNN編碼器 - 解碼器的850M字中的348M的子集。 我們使用測試集newstest2012和2013進行資料選擇和使用MERT進行重量調整,並使用newstest2014作為我們的測試集。 每組有超過7萬個單詞和一個參考翻譯。
為了訓練神經網路,包括提出的RNN編碼器 - 解碼器,我們將源和目標詞彙限制為英語和法語最常見的15,000個單詞。 這涵蓋了大約93%的資料集。 所有詞彙外的單詞都被對映到一個特殊的令牌([UNK])。
基於短語的基線SMT系統是使用具有預設設定的Moses構建的。 該系統在開發和測試集上分別達到30.64和33.3的BLEU分數(見表1)。
4.1.1 RNN Encoder–Decoder
在該實驗中使用的RNN編碼器 - 解碼器具有1000個隱藏單元,其在編碼器和解碼器處具有所提出的門。 每個輸入符號x hti和隱藏單元之間的輸入矩陣用兩個較低秩矩陣近似,並且輸出矩陣類似地近似。 我們使用了rank-100矩陣,相當於為每個單詞學習了100維的嵌入。 用於方程式中的h的啟用函式。 (8)是雙曲正切函式。 從解碼器中的隱藏狀態到輸出的計算被實現為深度神經網路(Pascanu等人,2014),其中單箇中間層具有500個最大單元,每個單元彙集2個輸入(Goodfellow等人,2013)。
