【python 淘寶爬蟲】淘寶信譽分抓取
阿新 • • 發佈:2019-02-15
一、需求分析
輸入旺旺號,獲取淘寶賣家的信用分
二、思路
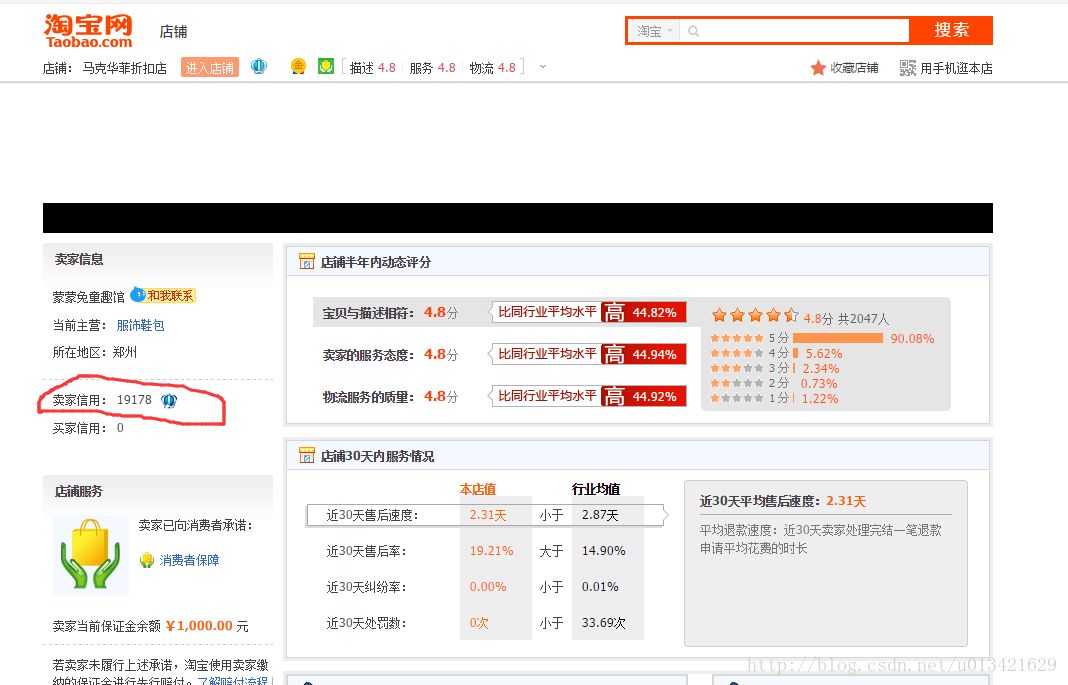
淘寶需要模擬登陸,我們這裡抓不到,因此為了繞過登陸,發現了淘一兔,我們可以通過這裡,得到淘寶賣家的信用分,結果是一樣的。
http://www.taoyizhu.com/
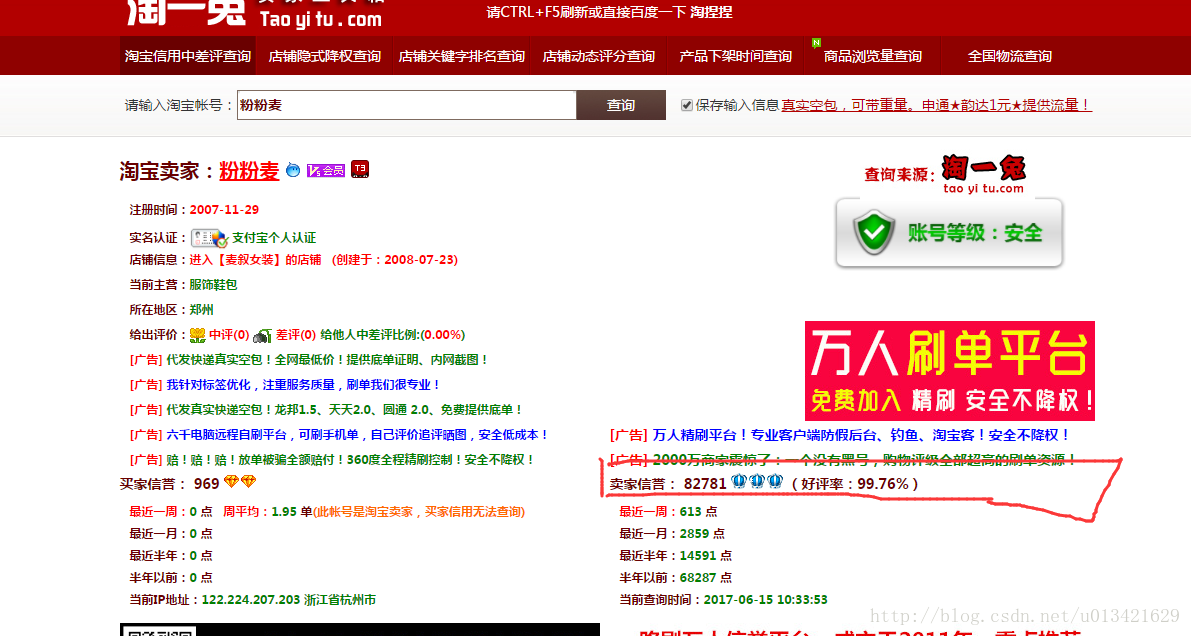
輸入旺旺號,需要點選查詢,等待幾秒,得到查詢結果,這裡我們用selienum 來做
三、實現原始碼(抓取不能太快,否則抓不到)
# encoding: utf-8
from selenium import webdriver
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import pandas as