
pandas按某一層索引分組取某一列的最大值,groupby(),idxmax()
阿新 • • 發佈:2019-02-13
本文是根據stackoverflow上一個問題進行的覆盤,若涉及任何侵權,請聯絡我修改或刪除。
stackoverflow原文連結 -->
https://stackoverflow.com/questions/32459325/python-pandas-dataframe-select-row-by-max-value-in-group
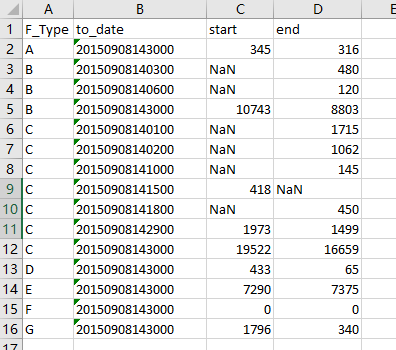
我將上面的資料直接複製貼上到excel中,分列及填充F_Type列後,儲存為csv格式。
接下來,用pandas.read_csv匯入到python中,
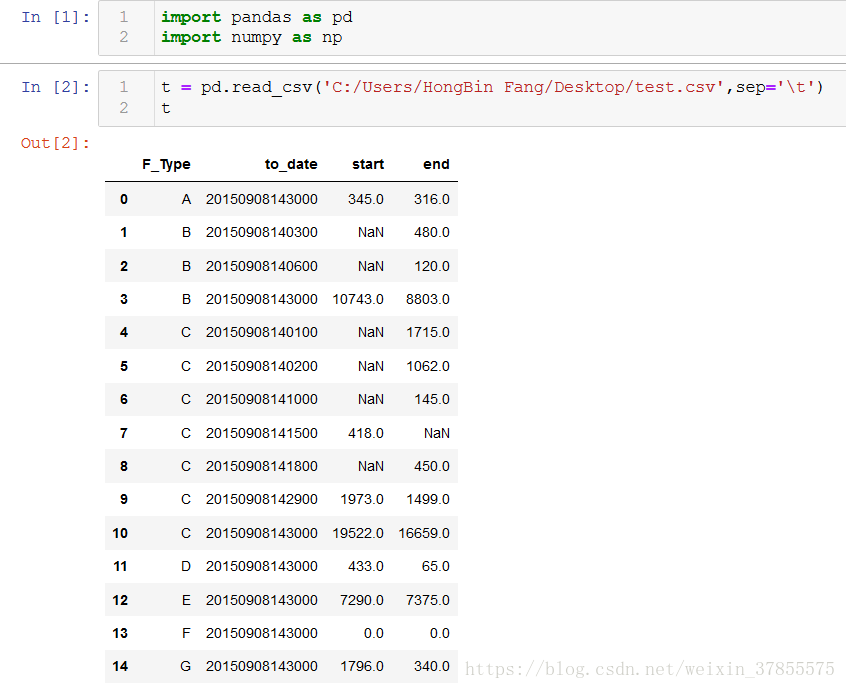
重新設定索引就可以顯示出與原問題相同的結構
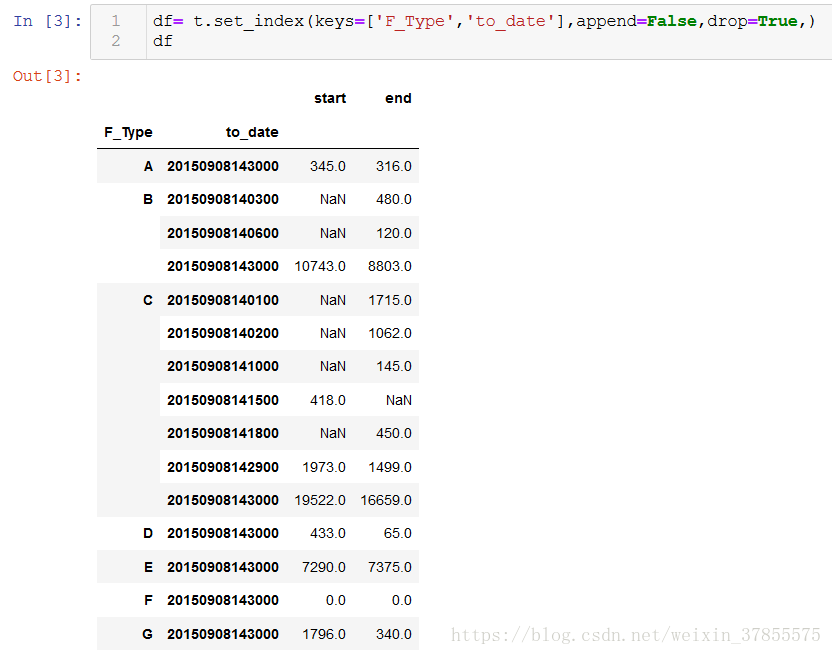
接下來,問題中的要求是按ABCD中去分組,然後取出每一分組的to_date最大的一條資料
先對df重設索引,這樣就可以把F_Type變成column類,再以這個column分組

用group_name.groups,可以檢視每一分組的資訊,這裡課可以看到每一分組包含的資料的索引位置資訊
接下來,指定各個groups中某一列。並idxmax()提取該列裡面的最大值的索引
這裡的出來的g1,是一個series,索引是各類,值是原資料的索引
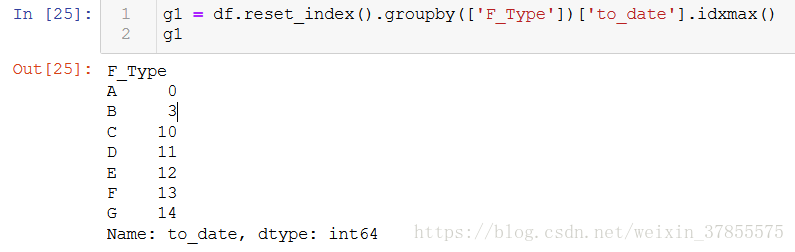
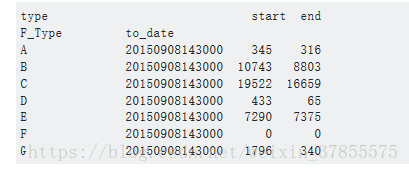
各最大值索引的位置出來了,我們就可以用iloc選取原陣列中對應的行資料,iloc是根據索引的位置來選取資料行
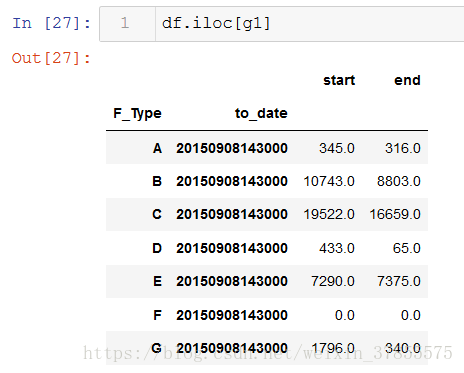
如果要用loc,loc是根據索引的值來選取資料行
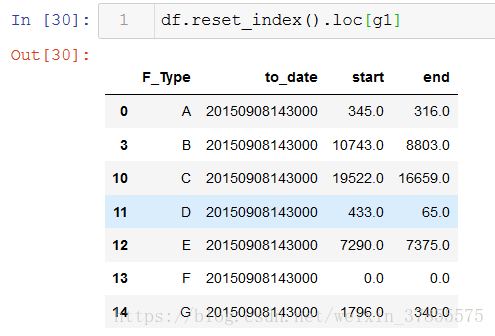
那麼我們就要對陣列reset_index,這樣一來,index就是重設為從0開始,新index無論是值還是位置,都是從0開始,便可以根據索引值選取資料行
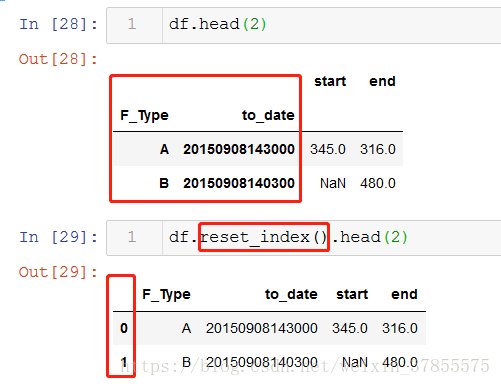
用loc選取後的陣列如下
原連結中解決問題的答案現在已經無法給出結果,resolver用的是loc+idxmax(), 可能pandas已經無法用loc去同時匹配一個作為條件的sereis的索引和值。

--- End ---