
吳恩達機器學習筆記(十六)-推薦系統
第十七章推薦系統
問題規劃
這一章中將討論推薦系統的有關內容,它是在機器學習中的一個重要應用。
機器學習領域的一個偉大思想:對於某些問題,有一些演算法可以自動地學習一系列合適的特徵,比起手動設計或編寫特徵更有效率。這是目前做的比較多的研究,有一些環境能讓你開發某個演算法來學習使用那些特徵。
接下里讓我們通過推薦系統的學習來領略一些特徵學習的思想。
推薦系統預測電影評分的問題:
某些公司讓使用者對不同的電影進行評價,用0到5星來評級,下面是使用者的評價情況:

符號介紹:
nu表示使用者的數量、nm表示電影的數量、
r(i,j)等於1時表示使用者j給電影i進行了評價、
y(i,j)表示當評價後會得到的具體的評價星值。
推薦系統就是在給出了r(i,j)和y(i,j)的值後,會去查詢那些沒有被評級的電影,並試圖預測這些電影的評價星級。例如,在上述圖中給出的結果,從Alice和Bob的評價中,他們給愛情片的評價比較高,可能預測他們沒看過的電影也是4到5星;而Carol和Dave的評價中,對愛情片的評價低,而動作片的評價不錯,所以他們對沒看過的愛情片的評價會是0,而對動作片的評價可能會是4到5星。

因此,如果想開發一個推薦系統,那麼需要想出一個學習演算法—能自動填補這些缺失值的演算法。這樣就可以看到該使用者還有哪些電影沒看過,並推薦新的電影給該使用者,可以去預測什麼是使用者感興趣的內容。
這就是推薦系統問題的主要形式,接下來將討論一個學習演算法來解決這個問題。
基於內容的推薦演算法
這一節中將介紹一種建立推薦系統的方法:基於內容的推薦演算法。
例如上一節中提到的預測電影的例子,如何預測未評價的電影呢?假設對於每一部電影,都有一個對應的特徵集,如下圖所示:

現在為了做出預測,可以把每個使用者的評價預測值看作是一個線性迴歸問題,特別規定,對於每一個使用者j,要學習引數向量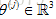

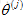
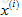
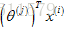
假如想預測使用者1-Alice對電影3的評價,那麼電影3會有一個引數向量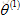
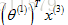
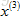

所以,上的操作就是對每一個使用者應用了一個不同的線性迴歸的副本,上述給出了Alice的線性方程。同樣的,其他使用者都有一個不同的線性方程,這就是預測評價的方法。
接下來給出問題的正式定義:
如果使用者j給出了電影i的評價,就將r(i,j)記為1,而y(i,j)是對電影的評價的具體評價值;

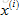

用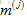

這就像是線性迴歸,最小化引數向量

通過這個方法可以得到對引數向量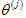
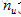

為了實現最小化,推導梯度下降的更新公式如下:

這就是如何將變數應用到線性迴歸中來預測不同使用者對不同電影的評級,這裡描述電影內容的特徵量來做預測,這個特殊的演算法叫做基於內容的推薦演算法,接下來將介紹另一種推薦演算法。
協同過濾
這一節中將討論用來構建推薦系統的方法,叫做協同過濾,這種演算法能夠自行學習要使用的特徵。
這裡還是用上一節中的預測電影的例子,但是不知道特徵量具體的值,如下圖所示:

假設這裡採訪了上述4個使用者,他們告知了喜歡愛情電影的程度以及喜歡動作電影的程度,於是每個使用者有了對應的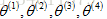

如果能從使用者得到例如上述的引數值,那麼理論上就能推測出每部電影的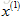
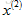
我們將這一學習問題標準化到任意特徵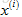
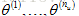
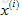

當然,我們不僅要學習單個電影的特徵,還要學習所有電影的所有特徵(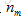

總結一下協同過濾的方法:
如果已知電影的特徵量,可以根據不同電影的特徵,學習引數θ,已知這些特徵,就能學習出不同使用者的引數θ;如果使用者願意提供這些引數θ,那麼就能估計出各種電影的特徵值。
那麼通過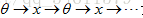
這一節中,探討了最基本的協同過濾演算法,它指的是當你執行演算法時,要觀察大量的使用者的實際行為來協同地得到更佳的每個人對電影的評分值,協同的另一層含義就是每個使用者都在幫助演算法更好地進行特徵學習。
協同過濾演算法
這一節中將會結合前兩節中講述到的概念來設計協同過濾演算法。
我們並不需要不停地重複計算,解出θ解出x再解出θ再解出x,實際上存在更有效率的演算法可以將θ和同時計算出來,定義新的優化目標函式J,如下圖所示:

這個代價函式將關於θ和x的兩個代價函式合併起來,為了提出一個綜合的優化目標問題,要做的是將這個代價函式視為特徵x和使用者引數θ的函式,對它的整體最小化:

所以,將上述所講的結合起來,就得到了協同過濾演算法:
▷ 首先會把θ和x初始化為小的隨機值;
▷ 接下來用梯度下降或其他高階優化演算法把代價函式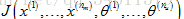

▷ 最後,如果使用者具有一些引數θ,電影帶有已知的特徵x,就可以預測出該使用者給這部電影的評分會是: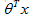
這就是協同過濾演算法,可以使用它同時計算出θ和x。
向量化:低秩矩陣分解
這一節中將介紹協同過濾演算法的向量化實現。
給定了資料如下;

將圖中的資料寫入矩陣中,會得到一個5行4列的矩陣:

矩陣中的Y(i,j)就是第j個使用者給第i部電影的評分,使用者j給第i部電影的評分的預測由公式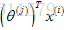

給定矩陣X和矩陣Θ的定義如下:

就可以用向量化的方法計算預測矩陣: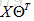
接下來再介紹一個問題:利用已學到的屬性來找到相關的電影。
假如有電影i,想要找到另一部與電影i相關的電影j,換個角度來說,如果使用者正在看電影j,看完後推薦哪一部電影比較合理?
比如電影i有一個特徵向量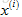
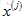
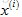
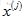
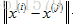
因此,希望通過本節的學習,能夠知道如何用一個向量化的實現來計算所有使用者對所有電影的評分預測值,也可以實現利用已學到的特徵,找到彼此相類似的電影。
實施細節:均值規範化
這一節中將介紹在實現推薦演算法過程中的細節:均值歸一化。
考慮這樣的例子,有一個使用者沒有給任何電影評分,如下圖所示:

現在再來看一看協同過濾演算法會對這個使用者做什麼,假設要學習兩個特徵變數,學習出引數向量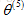
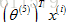
將圖中的資料寫入矩陣中,得到一個5行5列的矩陣:

現在要實現均值歸一化,要做是計算每個電影所得評分的均值:

觀察這些均值,現在用矩陣Y的每一列減去μ得到矩陣:

現在如果使用協同過濾演算法進行預測,則假設這就是從使用者那得到的實際評分,把它當做資料集,用來學習引數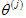
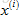
▷ 對使用者j對電影i的評分預測它為: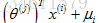
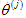
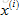
▷ 對使用者5:Eve來說,由於之前沒有給電影進行評分,學習到的引數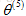
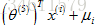
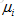
所以,這就是均值歸一化的實現,它作為協同過濾演算法的預處理步驟,根據不同的資料集,有時能讓演算法表現的更好。