
boosting和bagging演算法學習
目錄
ensemble learning
boosting和bagging都是整合學習(ensemble learning)領域的基本演算法[2]。
整合學習是指將若干弱分類器組合之後產生一個強分類器。弱分類器(weak learner)指那些分類準確率只稍好於隨機猜測的分類器(error rate < 50%)。
整合演算法成功的關鍵在於能保證弱分類器的多樣性(diversity)。整合不穩定的學習演算法能得到更明顯的效能提升。
為什麼要整合?
以下是Polikar給出的解釋 [3]:
模型選擇(Model Selection)
假設各弱分類器間具有一定差異性(如不同的演算法,或相同演算法不同引數配置),這會導致生成的分類決策邊界不同,也就是說它們在決策時會犯不同的錯誤。將它們結合後能得到更合理的邊界,減少整體錯誤,實現更好的分類效果。
資料集過小或過大(Too much or too little data)
資料集較大時,可以分為不同的子集,分別進行訓練,然後再合成分類器。
資料集過小時,可使用自舉技術(bootstrapping),從原樣本集有放回的抽取m個子集,訓練m個分類器,進行整合。分治(Divide and Conquer)
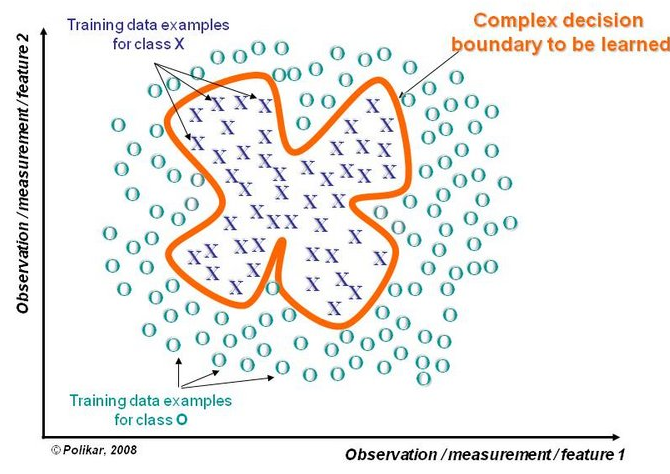
若決策邊界過於複雜,則線性模型不能很好地描述真實情況。因此先訓練多個線性分類器,再將它們整合。
資料融合(Data Fusion)
當有多個不同資料來源,且每個資料來源的特徵集抽取方法都不同時(異構的特徵集),需要分別訓練分類器然後再整合。
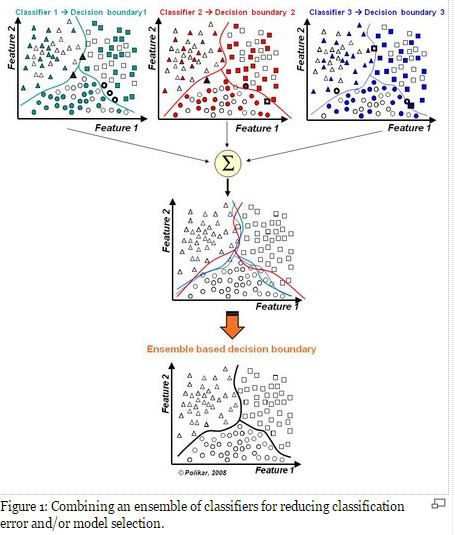
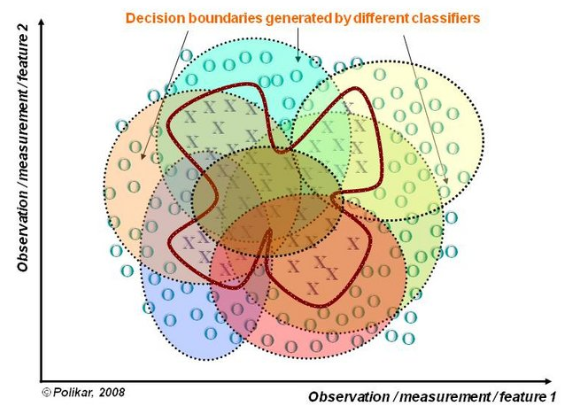
資料融合(Data Fusion)
置信度估計(Confidence Estimation)
可以為整合分類器計算分類結果的置信度。如使用多個弱分類器分類某個未知樣本,且經過多數投票後得到的標籤為y。如果投y的分類器越多,這個結果的置信度越高;反之則越低。
bagging方法
bagging也叫自舉匯聚法(bootstrap aggregating),是一種在原始資料集上通過有放回抽樣重新選出S個新資料集來訓練分類器的整合技術。也就是說這些新資料集是允許重複的。
使用訓練出來的分類器集合來對新樣本進行分類,然後用多數投票或者對輸出求均值的方法統計所有分類器的分類結果,結果最高的類別即為最終標籤。
boosting方法
分類器集合是在迭代中序列地產生的。訓練時著重關注訓練集中那些不容易區分的樣本。AdaBoost是一種常見的boosting演算法,下面是對演算法的描述。
AdaBoost
即Adaptive boosting,是一種迭代演算法。每輪迭代中會在訓練集上產生一個新的分類器,然後使用該分類器對所有樣本進行分類,以評估每個樣本的重要性(informative)。
具體來說,演算法會為每個訓練樣本賦予一個權值。每次用訓練完的新分類器標註各個樣本,若某個樣本點已被分類正確,則將其權值降低;若樣本點未被正確分類,則提高其權值。權值越高的樣本在下一次訓練中所佔的比重越大,也就是說越難區分的樣本在訓練過程中會變得越來越重要。
整個迭代過程直到錯誤率足夠小或達到一定次數為止。
訓練過程
為每個樣本初始化權值
1. 使用訓練集訓練分類器
2. 計算分類器的權值為
3. 更新樣本當前的權值
- 若分類正確,則減少權值,
- 若分類錯誤,則加大權值,
4. 將所有樣本的權值歸一化,使其相加為1
分類過程
用生成的所有分類器預測未知樣本X,最終結果為所有分類器輸出的加權平均。
分析
優點:泛化錯誤率降低,易實現,無需調整引數,可以處理不均衡的樣本集。
缺點:對於離群點很敏感,易過擬合。