
Cloudera Hadoop運維管理與效能調優
1、Hadoop客戶端 在開始介紹效能調優和運維之前,我們先來回顧一下Hadoop的架構,Hadoop是主從(master/slave)架構,具體儲存和計算都是由節點負責,主節點負責排程、元資料儲存、資源管理等。我們不禁會問,應該在哪個節點提交任務、上傳檔案呢?當然,主節點可以,叢集上任意一個節點也可以,但是這樣做會讓運維的難度增大,使得叢集不在純淨,所以不推薦這樣做。 我們很自然地希望將這些提交任務的工作交由一個節點來完成,但是又希望這個節點在叢集之外,事實上,這樣的節點是存在的我們稱之為Hadoop客戶端。Hadoop客戶端可以被認為是獨立於叢集之外,或者是叢集內特殊的一個節點,它不參與計算和儲存,可以用來提交任務。
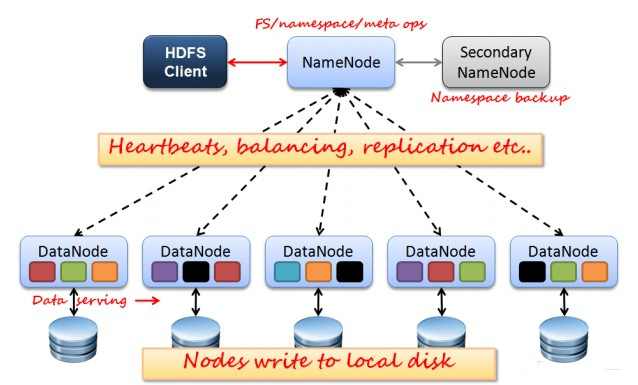
該節點的部署很簡單,將叢集內任意一臺機器的安裝檔案,不做任何修改直接全部發送到Hadoop節點的相同目錄下即可部署。這麼一來,在Hadoop客戶端就可以直接執行Hadoop客戶端相關命令,如Hadoop jar、Hadoop dfs等等,甚至直接可以在Hadoop客戶端執行start-all.sh指令碼,由於在叢集的配置檔案slaves中並沒有配置Hadoop客戶端的IP地址,所以Hadoop不會在Hadoop客戶端啟動DataNode、NodeManager程序。 當這個節點部署好以後,Hadoop客戶端就接管了叢集中所有與計算儲存無關的任務,例如向HDFS中上傳下載檔案、提交計算任務等等。那麼自然而然的,Hive、Sqoop的安裝位置也應該是Hadoop客戶端。本質上,Hive和Sqoop對於Hadoop來說就是一個客戶端,通過提交任務和叢集進行互動。那麼一個規範的叢集,使用者應該通過訪問Hadoop客戶端來和Hadoop叢集進行互動。 2、Hadoop效能調優
2.1、硬體選擇 Hadoop的優點之一就是能在普通硬體上良好地執行,所以不需要購買昂貴的硬體。但是仍然需要考慮實際工作中的硬體符合。例如CPU、記憶體和硬碟。 原則1:主節點可靠性要好於從節點 Hadoop是主從架構,Hadoop自身架構的基本特點決定了其硬體配置的選項。Hadoop採用了Master/Slave架構,其中,主節點維護了全域性元資料資訊,是YARM的ResourceManager和HDFS的NameNode,其重要性遠遠大於slave。一旦主節點掛掉,會造成整個叢集不可用。在較低Hadoop版本中,master存在單點故障問題,因此,master的配置應遠遠好於各個slave。
原則2:多路多核、高頻率CPU、大記憶體 NameNode的記憶體決定了叢集儲存檔案數量的總量,ResourceManager同時執行的作業會消耗一定的記憶體。 對於NameNode來說,在記憶體方面要特別考慮,每當HDFS啟動的時候,NameNode會將元資料載入進記憶體。所以HDFS所能儲存的檔案總數受限於NameNode的記憶體容量。而SecondaryNameNode的配置應該與NameNode相同,當NameNode宕機時,這些資訊被儲存在ResourceManagerde的記憶體中。ResourceManager的記憶體需求也是很高,與NameNode不同的是,它與HDFS檔案總數無關,與需要處理的作業有關。 從節點負責計算和儲存,所以需要保證CPU和記憶體能夠滿足計算要求,而磁碟滿足儲存要求。對YARN來說,它要執行各種各樣的任務,當然希望有足夠的計算資源。一般來說,記憶體和虛擬CPU要滿足一個線性比例,這樣在分配的時候才不容易造成浪費。 虛擬CPU的個數計算公式=CPU數X單個CPU核數X單個CPU核的超執行緒數”,例如,一個雙路的六核CPU,具有HT超執行緒技術,那麼它的虛擬CPU個數是2X6X2=24個,按照每個虛擬CPU分配4GB8GB的原則,服務記憶體應該為96GB-192GB。才外還需要作業系統以及其他其他服務預留資源。 原則3:根據資料量確定叢集規模 在規劃的儲存能力時候,首先考慮因素是塊的副本數,如果副本數是3,那麼平均下來1TB檔案在叢集實際上需要3TB檔案,平攤到每個節點就是每個節點所需要的最小容量。當然這個容量還是不夠的,最好是1.3倍。
原則4:不要讓網路IO成為瓶頸 Hadoop作業通常是IO密集型而非計算密集型,瓶頸通常集中在IO上。計算能力可以通過新增新節點進行線性擴充套件,而IO方面的瓶頸卻很難進行擴充套件。例如硬碟讀寫能力,交換機背板頻寬等。
2.2、作業系統調優與JVM調優 ( 1 )、避免使用SWAP分割槽,因為將Hadoop守護程序的資料交換到磁碟的行為可能會導致操作超時 swap分割槽是指在系統的實體記憶體不夠用的時候,把實體記憶體中的一部分空間釋放出來,以供當前執行的程式使用。通過vm.swapiness引數進行控制,值域是0-100,值越高說明作業系統核心更加積極地將應用程式的資料交換到磁碟。將Hadoop守護程序的資料交換到磁碟的行為是危險的,有可能導致操作超時,所以將該值設定為0。 在Linux中,如果一個程序的記憶體空間不足,那麼,它會將記憶體中的部分資料暫時寫到磁碟上,當需要時,再將磁碟上的資料動態置換到記憶體中,通常而言,這種行為會大大降低程序的執行效率。在MapReduce分散式計算環境中,使用者完全可以通過控制每個作業處理的資料量和每個任務執行過程中用到的各種緩衝區大小,避免使用swap分割槽。
具體方法是調整/etc/sysctl.conf檔案中的vm.swappiness引數。vm.swappiness有效範圍是0~100,值越高表明核心應該更積極將應用程式的資料交換到磁碟,較低的值表示將延遲這種行為,而不是強制丟棄檔案系統的緩衝區。 [[email protected] ~]# echo "vm.swappiness = 0 " >> /etc/sysctl.conf
( 2 )、調整記憶體分配策略 作業系統核心根據vm.overcommit_memory的值來決定記憶體分配策略,並且通過vm.overcommit_ratio的值來設定超過實體記憶體的比例。前者一般設定為2,後者根據實際情況調整。 [[email protected] ~]# echo 2 > /proc/sys/vm/overcommit_memory
程序通常呼叫malloc()函式來分配記憶體,記憶體決定是否有足夠的可用記憶體,並允許或拒絕記憶體分配的請求。Linux支援超量分配記憶體,以允許分配比可用RAM加上交換記憶體的請求。
vm.overcommit_memory引數有三種可能的配置。0表示檢查是否有足夠的記憶體可用,如果是,允許分配;如果記憶體不夠,拒絕該請求,並返回一個錯誤給應用程式。1 表示根據vm.overcommit_ratio定義的值,允許分配超出實體記憶體加上交換記憶體的請求。vm.overcommit_ratio引數是一個百分比,加上記憶體量決定記憶體可以超量分配多少記憶體。例如,vm.overcommit_ratio值為50,而記憶體有1GB,那麼這意味著在記憶體分配請求失敗前,加上交換記憶體,記憶體將允許高達1.5GB的記憶體分配請求。2 表示核心總是返回true。
( 3 )、修改net.core.somaxconn引數 該引數是Linux中的核心引數,表示socket監聽backlog的上限,backlog是套接字的監聽佇列,預設是128,socket伺服器會一次性處理backlog中的所有請求,當伺服器繁忙的時候,128遠遠不夠的,建議大於等於32768。並且修改core-default.xml中的.ipc.server.listen.queue.size引數(該引數表示服務端套接字的監聽佇列長度,即backlog長度)。 ( 4 )、選擇合適的檔案系統,並且禁用檔案的訪問時間 Hadoop執行在Linux系統,常見檔案系統就是ext3、ext4、xfs。對於不同檔案系統,ext3、ext4效能會有所不同。 當檔案系統被格式化以後,還需要做一項優化工作,禁用檔案的訪問時間。對於普通管得機器,這項功能可以讓使用者知道哪些檔案近期被檢視或者修改,但是對於HFDS沒有多大意義。因為HDFS目前不支援這類操作,並且獲取某個檔案的某個塊什麼時候被訪問並沒有意義。如果記錄了檔案的訪問時間的話,在每次讀操作的時候,也會伴隨一個寫操作,這個開銷是無謂的。所以在掛載資料分割槽的時候,需要禁用檔案的訪問時間。 ( 5 )、增大同時開啟的檔案描述符和網路連線上限 對核心來說,所有開啟的檔案都通過檔案描述符引用,檔案描述符是一個非負整數。當開啟一個現有檔案或者建立一個檔案的時候,核心向程序返回一個檔案描述符。在CDH叢集中,由於涉及的作業和任務數目非常多。Hadoop的作業經常會讀寫大量檔案,需要增大同時開啟檔案描述符的上限。因此,管理員在啟動Hadoop叢集時,使用ulimit命令將允許同時開啟的檔案描述符數目上限增大至一個合適的值。同時,調整核心引數net.core.somaxconn網路連線數目至一個足夠大的值。此外,Hadoop RPC採用了epoll作為高併發庫,如果你使用的Linux核心版本在2.6.28以上,你需要適當調整epoll的檔案描述符上限。 ( 6 )、設定合理的預讀取緩衝區大小 磁碟I/O效能的發展遠遠滯後於CPU和記憶體,因而成為現代計算機系統的一個主要瓶頸。預讀可以有效地減少磁碟的尋道次數和應用程式的I/O等待時間,是改進磁碟讀I/O效能的重要優化手段之一。管理員可使用Linux命令blockdev設定預讀取緩衝區的大小,以提高Hadoop中大檔案順序讀的效能。當然,也可以只為Hadoop系統本身增加預讀緩衝區大小。( 7 )、設定核心死鎖引數 softlockup(watchdog)用於檢測系統排程是否正常,即軟鎖的情況,當發生softlockup時,核心不能排程,但還能響應中斷,對使用者的表現可能為:能ping通,但無法登陸系統,無法進行正常操作。其基本原理為:為每個CPU啟動一個核心執行緒(watchdog/x),此執行緒為優先順序最高的實時執行緒,在該執行緒得到排程時,會更新相應的計數(時間戳),同時會啟動定時器,當定時器到期時檢查相應的時間戳,如果超過指定時間,都沒有更新,則說明這段時間內都沒有發生排程(因為此執行緒優先順序最高),則列印相應告警或根據配置可以進入panic流程,警告中包含佔用時長和程序名及pid。 [[email protected] ~]# echo 60 > /proc/sys/kernel/watchdog_thresh # 超時閾值,目前設定為60秒 [[email protected] ~]# echo 1 > /proc/sys/kernel/softlockup_panic # 預設為0,即只打印日誌;1為宕機重啟 (8 )、關閉THP Huge Pages就是大小為2MB-1GB的記憶體頁,而THP(Transparent Huge Pages)是一個使管理Huge Pages自動化的抽象層,但是在執行Hadoop作業時,THP會引起CPU佔用率偏高,需要將其關閉。
(9 )、JVM引數調優 由於Hadoop中的每個服務和任務均會執行在一個單獨的JVM中,因此,JVM的一些重要引數也會影響Hadoop效能。管理員可通過調整JVM FLAGS和JVM垃圾回收機制提高Hadoop效能,調整後的執行效率大概有4%的提升。 2.3、Haddop引數調優 Hadoop為使用者作業提供了多種可配置的引數,以允許使用者根據作業特點調整這些引數值使作業執行效率達到最優。
2.3.1、hdfs-site.xml <property> <name>dfs.blocksize</name>
<value>134217728</value>
</property>
該引數表示Hadoop檔案塊大小,通常設定為128MB或者256MB。
<property>
<name>dfs.replication</name>
<value>3</value>
</property> 該引數表示控制HDFS檔案的副本數,預設是3,當許多工同時讀取一個檔案時,讀取可能造成瓶頸,這時增大副本數能有效緩解,但會造成大量的磁碟空間佔用,這時只修改Hadoop客戶端的配置,這樣,從Hadoop客戶端上傳的檔案的副本數以Hadoop客戶端的為準。
<property>
<name>dfs.namenode.handler.count</name>
<value>40</value>
</property> 該引數表示NameNode同時和DataNode通訊的執行緒數,預設是10,將其增大為40。
2.3.2、core-site.xml
<property>
<name>io.file.buffer.size</name>
<value>65536</value>
</property>
緩衝區的大小用於讀寫HDFS檔案,還有map中間結果輸出都到這個緩衝區容量,預設4KB,增加128KB。
2.3.3、Yarn-site.xml <property><name>yarn.scheduler.increment-allocation-mb</name>
<value>512</value>
</property>
該引數表示記憶體申請大小的規整化單位,預設是1024MB,即如果申請的記憶體是1.5GB,將被計算為2GB。 <property>
<name>yarn.scheduler.increment-allocation-vcores</name>
<value>1</value>
</property> 該引數表示虛擬CPU申請的規整化單位,預設是1個。 <property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>65536</value>
該引數表示單個任務(容器)能夠申請到的最大記憶體,根據容器記憶體總量進行設定,預設8GB。
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>32</value>
</property>
該引數表示單個任務(容器)能夠申請到的最大虛擬CPU數,根據容器虛擬CPU總數進行設定,預設是4。 <property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1</value>
</property> 該引數表示單個任務(容器)能夠申請到的最小記憶體,根據容器記憶體總量進行設定,預設1GB。
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
該引數表示單個任務(容器)能夠申請到的最小虛擬CPU數,根據容器虛擬CPU總數進行設定,預設是1。
2.3.4、mapred-site.xml <property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
該引數表示Map任務的中間結果是否進行壓縮,設定為true時,會對中間結果進行壓縮,這樣會減少資料傳輸時貸款的需要。 <property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
該引數表示Map任務需要的記憶體大小。 <property>
<name>mapreduce.map.cpu.vcores</name>
<value>1</value>
</property>
該引數表示Map任務所需要的虛擬CPU數,預設是1。 <property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
該配置為Reduce任務所需要的記憶體大小。 <property>
<name>mapreduce.reduce.cpu.vcores</name>
<value>1</value>
</property> 該配置為Reduce任務向排程器需要的虛擬CPU數,預設是1,根據容器虛擬CPU數設定。 3、Hive調優 在實際應用中,我們會選擇Hive而不是Mapduce開發應用,所以Hive使用的頻率會非常高,有必要對其進行調優,調優的而方法是引數配置、優化HQL等等,Hive的配置檔案是$Hive_HOME/conf/hive=site.xml檔案。 其實Hive已經做了很多原生優化的工作了,所以在執行效率和穩定性上已經很不錯,但是仍然有優化的空間,經過有針對性的調優,有利於HIve有效的執行。 3.1、JOIN優化 在執行JOIN語句中,需要將大表放在右邊以獲得更好的效能,如果一個表小到能影響全部加在到記憶體中,那麼可以考慮執行map端JOIN。 3.2、Reducer的數量 將Reducer最大值設定為n*0.95,其中n為NodeManger數量,通過設定hive.reducers.max可以增加Reducer數量,但是這樣並不能直接增大Hive作業的Reducer的個數,Hive作業的Redurce個數可以直接由以下兩個引數配置決定的。 hive.exec.reducers.bytes.per.reducer(預設1GB) hive.exec.reducers.max(預設999) 計算Reducer個數的公式為“Reducer的個數=min(引數是2,總輸入蜀將/引數1)”,所以如果輸入資料是5GB情況相愛,Hive會開啟5個Reducer,我們可以通過改變這兩個引數,來達到控制Reducer個數的目的。 3.3、並行執行 一個HQL會被Hive拆分成為多個作業,這些作業有時候相互之間會有依賴,有時候則相互獨立,如表1和表2JOIN的結果與表3和表4JOIN的結果再JOIN,那麼表1和表2JOIN的結果與表3和表4JOIN這兩個作業則是相互獨立,而最後一次JOIN的作業依賴於前兩個作業。從邏輯上看,第一個作業和第二個作業可以同時執行。但是HIve預設不考慮並行性。一次執行作業,我們可以通過設定引數hive.exec.paraller為true,開啟Hive的並行模式。 4、Hbase調優 Hbase在使用過程中也需要調優,才能保證在極大的資料量下滿足業務的需求。但Hbase調優其實比Hadoop要複雜和靈活一些,因為面對的情況不一樣,如高併發讀、高併發寫、高併發讀寫混合,要求低延遲,等等,所以經常會用對某幾個引數反覆除錯才能達到最佳效果。Hbase的調優覆蓋是全方面的,有表設計上的,有運維上的,有硬體上的,還有配置引數上的。
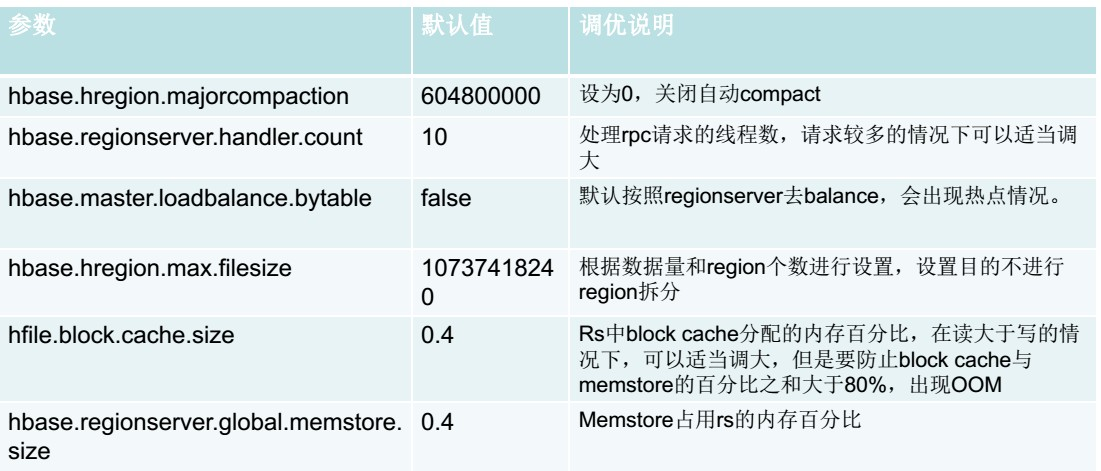
4.1、通用調優 Hbase是面向業務,業務場景不同,調優方式不同。例如,有些場景讀多寫少,有些場景寫少讀多,有些場景讀寫各半。Hbase有些通用優點幾乎適用於所有場景,能讓Hbase的效能獲得整體提升。
增大Zookeeper連線數:Zookeeper最大連線數會影響Hbase的併發效能,最大連線數可以通過Zookepper上的maxClientCxns引數進行配置,在配置時候注意考慮硬體的效能。 適當的region大小:region越大越少,效能越好。 Region處理器數量:該配置定義了每一個RegionServer的RPC處理器的數量。Reguin Server通過RPC處理器接受外部請求並且加以處理。所以增加RPC處理的數量可以一定程度提高Hbase接受請求的能力,也就是RegionServer接受請求的能力。這個引數跟記憶體息息相關。 RegionServer記憶體:推薦32GB,再大的話,對效能影響不大。 考慮SSD硬碟:當對效能比較嚴格苛刻時候,採取SSD,這樣效能可以得到顯著提升,Hbae的瓶頸一般在硬碟和網路。 4.2、客戶端調優 因為Hbase的讀寫請求都是由客戶端發起的,所以根據不同的業務改變客戶端的查詢和寫入方式,也能使Hbase的效能有所提升,並且客戶端的引數的作用於都是會話範圍,非常靈活。例如,客戶端寫入緩衝區、禁止自動重新整理、設定客戶端快取記憶體、並行插入框架等等。 4.3、表設計調優 行健設計:行健設計對Hbase來說非常重要。它的設計直接影響了查詢模式、查詢效能和資料分佈。 不要在一張表裡面定義太多的列族。 在建立表時候,可以進行與分割槽:這樣可以避免表頻繁地進行solit,資料自然在叢集分散分佈。 5、Hadoop運維 Hadoop運維無外乎,監控整個叢集的健康狀態,瞭解磁碟的剩餘空間,及時處理死掉的datanode,對磁碟碎片進行處理,以便提高叢集的執行效率。當叢集中存在執行任務時,需要對任務的引數進行控制,保證整個叢集能夠正常的高效的完成任務如果出現異常,需要分析異常,調整引數。一般的hadoop運維都是程式設計師出生,不然很難弄。你對hadoop一知半解,那整個Hadoop叢集出現問題,你都不知道從何入手。
Cloudera Manager作為Hadoop大資料平臺的管理工具,本身具有四大功能:管理功能,監控功能、診斷功能和整合功能。
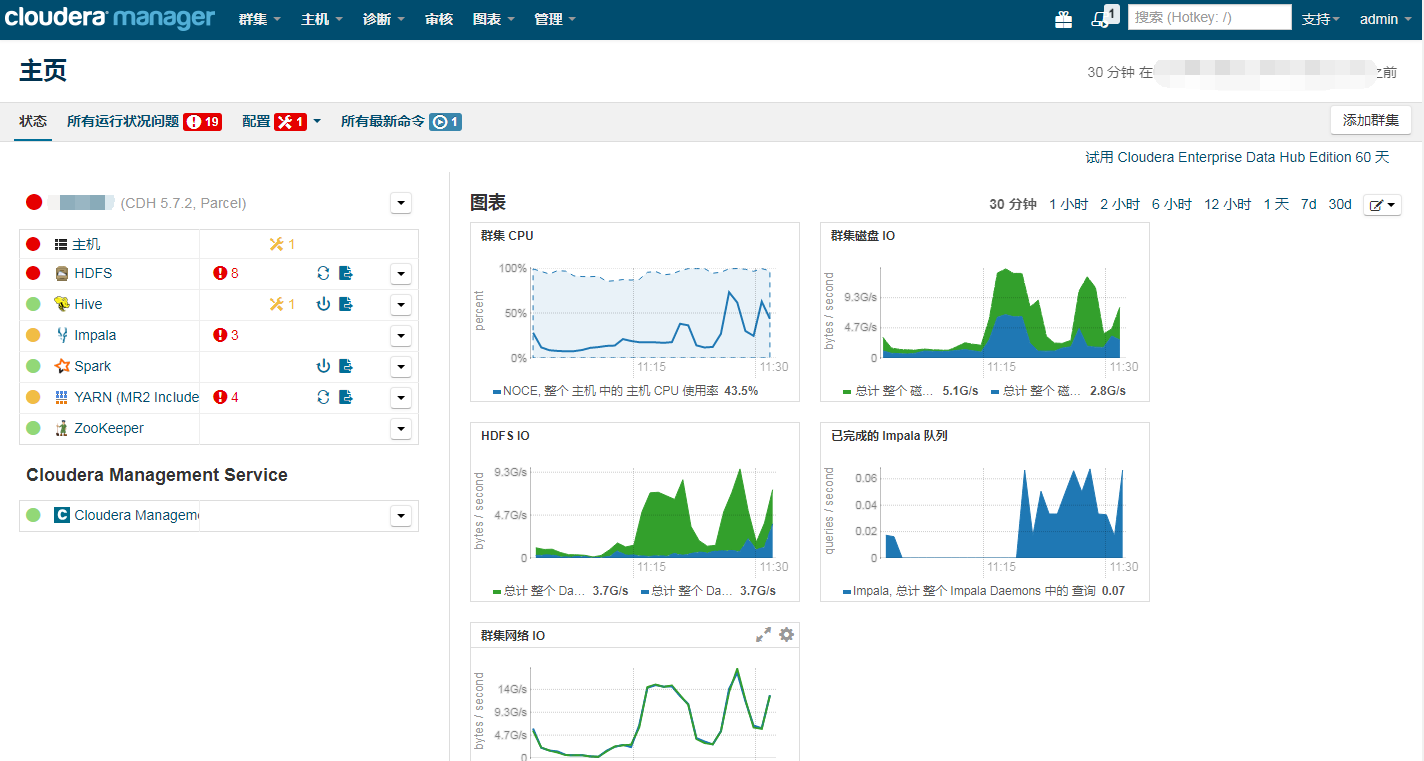
5.1、檢視日誌 日誌是Hadoop運維最重要的依據,無論遇到什麼異常情況,通常首先要做的就是檢視日誌。tail -f 檢視 命令可以實時檢視更新日誌:$HADOOP_HOME/logs/下NameNode、DataNode、ResourceManager和NodeManager的日誌。 5.2、清理臨時檔案 很多時候,由於對叢集的操作太過頻繁,或是日誌輸出不合理,日誌檔案或者歷史檔案可能變得十分巨大,影響正常HDFS儲存,可以視情況定期清理。有時候,我們發現,即使刪除了某些大檔案,但是df -h檢視分割槽佔用率依舊填滿。那是什麼原因呢?
原來,Linux系統下檔名是存在父目錄的block裡面,並指向這個檔案的inode節點,這個檔案的inode節點再指向存放這個檔案的block資料塊。當我們刪除一個檔案時,實際上並不是清除了inode節點和block資料塊。只是在這個檔案的父目錄裡面的block中,刪除了這個檔案的名字,從而使這個檔名消失,並且無法指向這個檔案的inode節點而已。
所以,rm -f 這個操作只是將檔案的 i_nlink減少了,如果沒有其它的連結 i_nlink就為0了。但是由於該檔案依然被程序引用,因此,此時檔案對應的 i_count並不為0,所以執行rm操作,系統並沒有真正的刪除這個檔案,只有當 i_nlink和 i_count都為 0 的時候,這個檔案才會被真正的刪除。也就是說,必須要解除該程序對該檔案的呼叫,才能真正的刪除。
lsof簡介lsof(list open files)是一個列出當前系統開啟檔案的工具。檢視已經刪除的檔案,空間有沒有釋放,沒有的話kill掉pid
lsof -n |grep deleted
5.3、定期執行資料均衡指令碼 導致HDFS資料不均衡的原因有很多種,如新增一個DataNode、快速刪除HDFS上的大量檔案、計算任務分佈不均勻等等。可以通過執行Hadoop自帶的均衡器指令碼來重新平衡整個叢集,指令碼的路徑是$Hadoop_HOME/bin/start-balancer.sh。
相關推薦
Cloudera Hadoop運維管理與效能調優
效能調優之於Hadoop來說無異於打通任督二脈,對於Hadoop的計算能力會有質的的提升,而運維之於Hadoop來說,就好像金鐘罩、鐵布衫一般,有了穩定的運維,Hadoop才能在海量資料之中大展拳腳,兩者相輔相成,缺一不可。 總體來說,Hadoop運維維度取決於Had
深入理解Java虛擬機器總結一虛擬機器效能監控工具與效能調優(三)
深入理解Java虛擬機器總結一虛擬機器效能監控工具與效能調優(三) JDK的命令列工具 JDK的視覺化工具 效能調優 JDK的命令列工具 主要有以下幾種: jps (Java Process Status Tool): 虛擬機器程序
nginx監控與效能調優
監控 nginx有自帶的監控模組,編譯nginx的時候,加上引數 --with-http_stub_status_module #配置指令 ./configure --prefix=/usr/local --user=nginx --group=nginx
Redis 基礎、高階特性與效能調優
本文將從Redis的基本特性入手,通過講述Redis的資料結構和主要命令對Redis的基本能力進行直觀介紹。之後概覽Redis提供的高階能力,並在部署、維護、效能調優等多個方面進行更深入的介紹和指導。 本文適合使用Redis的普通開發人員,以及對Redis進行選型、架構設計和效能調優的架構設計人員。 &n
Redis基礎、高階特性與效能調優
本文將從Redis的基本特性入手,通過講述Redis的資料結構和主要命令對Redis的基本能力進行直觀介紹。之後概覽Redis提供的高階能力,並在部署、維護、效能調優等多個方面進行更深入的介紹和指導。 本文適合使用Redis的普通開發人員,以及對Redis進行選型、
JVM垃圾回收與效能調優
一、JVM記憶體結構 圖片來源於網路 1、方法區 方法區用於儲存已被虛擬機器載入的類資訊、常量、靜態變數、即時編譯器編譯後的程式碼等資料,描述為堆的一個邏輯部分,稱為非堆(HotSpot中也稱為永久代)
Spark商業案例與效能調優實戰100課》第3課:商業案例之通過RDD分析大資料電影點評系各種型別的最喜愛電影TopN及效能優化技巧
Spark商業案例與效能調優實戰100課》第3課:商業案例之通過RDD分析大資料電影點評系各種型別的最喜愛電影TopN及效能優化技 原始碼 package com.dt.spark.core
介面測試流程與效能調優
1.介面效能測試流程1-5是效能流程1.接到需求,先把介面功能調通 引數化(常用的引數化方法),關聯(正則表示式),檢查點(我們要檢查哪些),看需不需要集合,如果這個介面依賴上一個介面,那麼這個需要用到引數的傳遞,看介面需不需要用到cookie session等,請求頭等2.
Hadoop實戰:*********MapReduce的效能調優(一)*********
下面來談談重頭戲,那就是mapred中的這些NB的引數。前置知識我相信大家都已經瞭解了(如果你還不瞭解mapred的執行機制,看這個也無意義...),首先資料要進行map,然後merge,然後reduce程序進行copy,最後進行reduce,其中的merge和copy總稱可以為shuffle
redis基礎、高階特性與效能調優(轉)
本文將從Redis的基本特性入手,通過講述Redis的資料結構和主要命令對Redis的基本能力進行直觀介紹。之後概覽Redis提供的高階能力,並在部署、維護、效能調優等多個方面進行更深入的介紹和指導。本文適合使用Redis的普通開發人員,以及對Redis進行選型、架構設計和效能調優的架構設計人員。目錄概述Re
nginx配置與效能調優
nginx的配置檔案 首先,我的nginx是原始碼編譯的,版本是官網是提供的穩定版1.12.0、根據的我編譯選項,配置檔案被我編譯到/etc/nginx目錄下。 [[email p
高薪必備|Redis 基礎、高階特性與效能調優
開發十年,就只剩下這套架構體系了! >>>
效能測試分析與效能調優診斷--史上最全的伺服器效能分析監控調優篇
一個系統或者網站在功能開發完成後一般最終都需要部署到伺服器上執行,那麼伺服器的效能監控和分析就顯得非常重要了,選用什麼配置的伺服器、如何對伺服器進行調優、如何從伺服器監控中發現程式的效能問題、如何判斷伺服器的瓶頸在哪裡等 就成為了伺服器效能監控和分析時重點需要去解決的問題了。 本文章節
鯤鵬效能優化十板斧——鯤鵬處理器NUMA簡介與效能調優五步法
1.1 鯤鵬處理器NUMA簡介 隨著現代社會資訊化、智慧化的飛速發展,越來越多的裝置接入網際網路、物聯網、車聯網,從而催生了龐大的計算需求。但是功耗牆問題以功耗和冷卻兩大限制極大的影響了單核算力的發展。為了滿足智慧世界快速增長的算力需求,多核架構成為最重要的演進方向。 傳統的多核方案採用的是SMP(
Elasticsearch原理解析與效能調優
## 基本概念 ### 定義 - 一個分散式的實時文件儲存,*每個欄位* 可以被索引與搜尋 - 一個分散式實時分析搜尋引擎 - 能勝任上百個服務節點的擴充套件,並支援 PB 級別的結構化或者非結構化資料 ### 用途 - 全文檢索 - 結構化搜尋 - 分析 ### VS傳統資料庫 - 傳統資料庫
Mysql運維管理-MySQL備份與恢復實戰案例及生產方案17
inno 主鍵 文件 黑名單 con dem into info l數據庫 1.全量備份與增量備份 1.1 全量備份 全量數據就是數據庫中所有的數據,全量備份就是把數據庫中所有的數據進行備份。 備份所有庫:mysqldump -uroot -p123456 -S /data
mysql運維管理-mysqldump 備份與恢復數據庫20
oca 導出數據 -h sql數據庫 oot 指定 令行 恢復數據 all mysqldump 備份與恢復數據庫 備份: 1、備份全部數據庫的數據和結構 mysqldump -uroot -pjsb -A > /bk/all.sql -A: 備份所有數據庫=--al
Tomcat效能調優以及遠端管理(Tomcat manager與psi-probe監控)
tomcat優化的我用到的幾個點: 1.記憶體優化 2.執行緒優化 docs/config/http.html maxConnections acceptCount(配置的太大是沒有意義的) maxThreads minSpareThreads 最小空閒的工作
網站運維技術與實踐之資料採集、傳輸與過濾 談談運維人員謹慎作業系統環境和管理
一、採集點的取捨 說到資料分析,首先當然是資料越全面越詳細越好。因為這有助於分析得出比較正確的結果,從而做出合理的決策。 1.伺服器資料 採集的伺服器資料主要圍繞著這麼幾個? (1)伺服器負載 (2)磁碟讀寫 (3)網絡卡流量 如何採集這些資料,可以通過zabbix監控獲取。 關於zabbix
DEVOPS 運維開發系列九:VLAN網段與私網IP資源的自動化運維管理
要解決的問題 傳統上,對於VLAN和私網IP地址這些資源與配置的使用管理上面我們多是事前規劃、事中實施、事後登記,對於一個持續運營中的系統與網路,各種資源數量的變更,總是讓我們會有很多機會反反覆覆做這些事。但時間長了就會出問題,會有不登記的情況、登記錯的情況,以及登記的資訊過時的情況。然