
相似度演算法之皮爾遜相關係數
皮爾遜相關係數是比歐幾里德距離更加複雜的可以判斷人們興趣的相似度的一種方法。該相關係數是判斷兩組資料與某一直線擬合程式的一種試題。它在資料不是很規範的時候,會傾向於給出更好的結果。
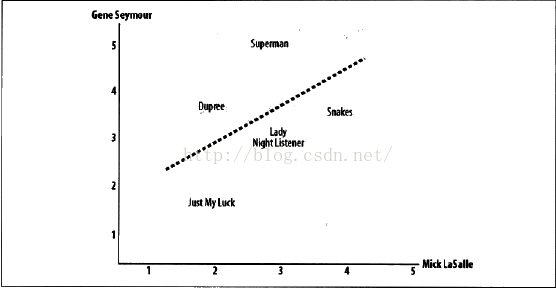
如圖,Mick Lasalle為<<Superman>>評了3分,而GeneSeyour則評了5分,所以該影片被定位中圖中的(3,5)處。在圖中還可以看到一條直線。其繪製原則是儘可能地靠近圖上的所有座標點,被稱為最佳擬合線。如果兩位評論者對所有影片的評分情況都相同,那麼這條直線將成為對角線,並且會與圖上所有的座標點都相交,從而得到一個結果為1的理想相關度評價。
假設有兩個變數X(x1,x2,x3,……)、Y(y1,y2,y3,……),那麼兩變數間的皮爾遜相關係數可通過以下公式計算:
公式一:

皮爾遜相關係數計算公式
公式二:

皮爾遜相關係數計算公式
公式三:

皮爾遜相關係數計算公式
公式四:

皮爾遜相關係數計算公式
以上列出的四個公式等價,其中E是數學期望,cov表示協方差,N表示變數取值的個數。
皮爾遜相關度評價演算法首先會找出兩位評論者都曾評論過的物品,然後計算兩者的評分總和與平方和,並求得評分的乘積之各。利用上面的公式四計算出皮爾遜相關係數。
在實踐統計中,一般只輸出兩個係數,一個是相關係數,也就是計算出來的相關係數大小,在-1到1之間;另一個是獨立樣本檢驗係數,用來檢驗樣本一致性.
根據皮爾遜相關係數的值參考以下標準,可以大概評估出兩者的相似程度:
- 0.8-1.0 極強相關
- 0.6-0.8 強相關
- 0.4-0.6 中等程度相關
- 0.2-0.4 弱相關
- 0.0-0.2 極弱相關或無相關
當然,在使用過程中該演算法也不使用所有的場景,需要變數X,Y滿足以下幾個約束條件:
- 1 兩個變數間有線性關係
- 2 變數是連續變數
- 3 變數均符合正態分佈,且二元分佈也符合正態分佈
- 4 兩變數獨立
演算法實現如下:
#皮爾遜相似度演算法 def PearsonSimilarity(UL,p1,p2): si = GetSameItem(UL,p1,p2) n = len(si) if n == 0: return 0 sum1 = sum([UL[p1][item] for item in si]) sum2 = sum([UL[p2][item] for item in si]) sqSum1 = sum([pow(UL[p1][item],2) for item in si]) sqSum2 = sum([pow(UL[p2][item],2) for item in si]) pSum = sum([UL[p1][item]*UL[p2][item] for item in si]) num = pSum - (sum1*sum2/n) den = math.sqrt(sqSum1-pow(sum1,2)/n)*math.sqrt(sqSum2-pow(sum2,2)/n) if den ==0: return 0 r = num/den return r
注:本文很大一部分內容轉自:http://lobert.iteye.com/blog/2024999,因為這位仁兄總結的確實很好。本文後續部分略作補充,謹作拋磚引玉之用。