
學習理論之模型選擇——Andrew Ng機器學習筆記(八)
內容提要
這篇部落格主要的內容有:
1. 模型選擇
2. 貝葉斯統計和規則化(Bayesian statistics and regularization)
最為核心的就是模型的選擇,雖然沒有那麼多複雜的公式,但是,他提供了更加巨集觀的指導,而且很多時候是必不可少的。now let’s begin
模型選擇
假設我們訓練不同的模型去解決一個學習問題,比如我們有一個多項式迴歸模型
我們先假設一個模型的有限幾何
交叉驗證
解決上面模型選擇問題的一個簡單想法就是我用70%的資料對每一模型進行訓練,用30%的資料進行訓練誤差的計算,然後我們在比較各個模型的訓練誤差,就可以選擇出訓練誤差比較小的模型了。如果對這些誤差不用請參看(學習理論之經驗風險最小化——Andrew Ng機器學習筆記(七))這篇部落格。
如果我們的訓練資料非常容易的就可以得到,那麼上面這個方法將是一個不錯的方法,因為它只需要遍歷訓練模型一次就可以得到一個比較好的模型。但是訓練資料往往不是非常容易就可以得到,之前我就採集過一次實驗資料,那的的確是一次非常痛苦的過程。所以我們就想高效的利用我們來之不易的訓練資料,有人就提出來K重交叉驗證(k-fold cross validation)演算法,演算法過程如下:
- 將訓練集
S 分成k 份,分別記為S1,S2,...,Sk - 對於每一個
Mi ,都執行如下過程:
forj=1,2,...,k
在S1,S2,...Sj−1,Sj+1,...Sk 上訓練模型Mi ,得到假設函式hij 。
利用Sj 計算hij 的訓練誤差,然後求平均值。- 選擇出訓練誤差最小的模型
Mi ,然後在整個訓練集上訓練整個模型,最後我們就得到了對於這個訓練集最好的模型
這個演算法主要的思想就是:對於每一個模型,我們一次用
特徵選擇
特徵選擇 ( Feature Selection )也稱特徵子集選擇( Feature Subset Selection , FSS ) ,或屬性選擇( Attribute Selection ) ,是指從全部特徵中選取一個特徵子集,使構造出來的模型更好。
為什麼要特徵選擇
先舉個例子,之前我們舉過郵件分類的例子,整個郵件中的單詞是否出現構成的0,1向量作為其特徵向量。但是,當其中出現“deep leaning”等單詞對判斷判斷是否為垃圾郵件作用不大,反而出現“buy”等單詞對判斷作用大,所以我們就行將其中作用不大的這些單詞剔除掉。剔除的過程就是特徵選擇的過程。下面我們再來看看更加嚴格的說明
在機器學習的實際應用中,特徵數量往往較多,其中可能存在不相關的特徵,特徵之間也可能存在相互依賴,容易導致如下的後果:
1. 特徵個數越多,分析特徵、訓練模型所需的時間就越長
2. 特徵個數越多,容易引起“維度災難”,模型也會越複雜,其推廣能力會下降
特徵選擇能剔除不相關(irrelevant)或亢餘(redundant )的特徵,從而達到減少特徵個數,提高模型精確度,減少執行時間的目的。另一方面,選取出真正相關的特徵簡化了模型,使研究人員易於理解資料產生的過程。
下面我們介紹特徵選擇的演算法
前向搜尋和後向搜尋
先來看前向搜尋,他的核心思想就是嘗試特徵向量所有組合,從中選擇出訓練誤差最小的特徵向量的自向量,原始特徵向量的維度為n,具體描述如下:
1. 初始化特徵向量
2. 迴圈直到到達閾值或者迴圈n趟
令
3. 輸出最終訓練誤差最小的特徵向量的子集
實際上這個演算法就是在遍歷這樣一個排列樹(關於演算法的書上有排列樹的概念):
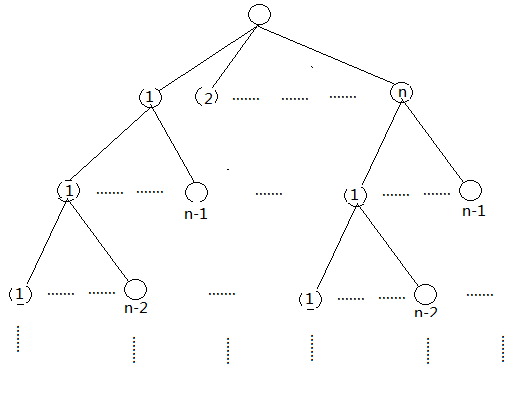
並且以廣度優先的方式進行遍歷。不同就是,每一層只保留一個訓練誤差最小的節點。
與前向搜尋思想相反的搜尋演算法叫後向搜尋,他的核心思想是:先將
前向搜尋和後向搜尋屬於封裝特徵選擇(wrapper model feature selection),Andrew Ng老師還解釋為什麼稱為“Wraper”原因,說這算個就像“wrapper”一樣套在你的學習演算法外面,在執行的時候需要不斷重複的呼叫你的學習演算法。前向搜尋和後向搜尋都有兩層迴圈,並且最壞情況下迴圈計數都到達
濾特徵選擇演算法(Filter feature selection method)
有時候前向和後向搜尋的複雜度是無法接收的,比如在郵件分類中,特徵向量的維數有時候會到達5000,甚至更高。這時的複雜度我們接收不了。所以就有了濾特徵選擇演算法,它是一種啟發式搜尋演算法,其中我們會定義個評價函式
定義S(i)
這個
相關推薦
學習理論之模型選擇——Andrew Ng機器學習筆記(八)
內容提要 這篇部落格主要的內容有: 1. 模型選擇 2. 貝葉斯統計和規則化(Bayesian statistics and regularization) 最為核心的就是模型的選擇,雖然沒有那麼多複雜的公式,但是,他提供了更加巨集觀的指導,而且很多時候
非監督學習之混合高斯模型和EM演算法——Andrew Ng機器學習筆記(十)
0、內容提要 這篇博文主要介紹: - 混合高斯模型(mixture of Gaussians model) - EM演算法(Expectation-Maximization algorithm) 1、引入 假設給定一個訓練集{x(1),...,x(m)
Andrew Ng機器學習課程筆記(十六)之無監督學習之因子分析模型與EM演算法
Preface Marginals and Conditionals of Gaussians(高斯分佈的邊緣分佈與條件分佈) Restrictions of ΣΣ(限制協方差矩陣) Factor Analysis(因子分析模型) EM Alg
廣義線性模型 - Andrew Ng機器學習公開課筆記1.6
sans luci art 能夠 tro ron 便是 import grand 在分類問題中我們如果: 他們都是廣義線性模型中的一個樣例,在理解廣義線性模型之前須要先理解指數分布族。 指數分
Andrew Ng機器學習課程筆記(四)之神經網絡
sca 優化 介紹 www 之間 output 現在 利用 href Andrew Ng機器學習課程筆記(四)之神經網絡 版權聲明:本文為博主原創文章,轉載請指明轉載地址 http://www.cnblogs.com/fydeblog/p/7365730.html 前言
學習理論、模型選擇、特徵選擇——斯坦福CS229機器學習個人總結(四)
這一份總結裡的主要內容不是演算法,是關於如何對偏差和方差進行權衡、如何選擇模型、如何選擇特徵的內容,通過這些可以在實際中對問題進行更好地選擇與修改模型。 1、學習理論(Learning theory) 1.1、偏差/方差(Bias/variance)
Andrew Ng機器學習課程筆記(十三)之無監督學習之EM演算法
Preface Jensen’s Inequality(Jensen不等式) Expectation-Maximization Algorithm(EM演算法) Jensen’s Inequality 對於凸函式 令f(x)f(x)為
Andrew Ng機器學習課程之學習筆記---牛頓方法
牛頓方法 本次課程大綱: 1、 牛頓方法:對Logistic模型進行擬合 2、 指數分佈族 3、 廣義線性模型(GLM):聯絡Logistic迴歸和最小二乘模型 複習: Logistic迴歸:分類演算法 假設給定x以為引數的y=1和y=0的概率: 求對數似然性: 對其求偏導數,應用梯度上升
Andrew Ng機器學習課程筆記(十二)之無監督學習之K-means聚類演算法
Preface Unsupervised Learning(無監督學習) K-means聚類演算法 Unsupervised Learning 我們以前介紹的所有演算法都是基於有類別標籤的資料集,當我們對於沒有標籤的資料進行分類時,以前的方
Andrew NG機器學習課程筆記系列之——Introduction to Machine Learning
引言 本系列文章是本人對Andrew NG的機器學習課程的一些筆記,如有錯誤,請讀者以課程為準。 在現實生活中,我們每天都可能在不知不覺中使用了各種各樣的機器學習演算法。 例如,當你每一次使用 Google 時,它之所以可以執行良好,其中一個重要原因便是由 Google 實
非監督學習之k-means聚類演算法——Andrew Ng機器學習筆記(九)
寫在前面的話 在聚類問題中,我們給定一個訓練集,演算法根據某種策略將訓練集分成若干類。在監督式學習中,訓練集中每一個數據都有一個標籤,但是在分類問題中沒有,所以類似的我們可以將聚類演算法稱之為非監督式學習演算法。這兩種演算法最大的區別還在於:監督式學習有正確答
Andrew Ng機器學習筆記+Weka相關算法實現(四)SVM和原始對偶問題
優化問題 坐標 出了 變量 addclass fun ber 找到 線性 這篇博客主要解說了Ng的課第六、七個視頻,涉及到的內容包含,函數間隔和幾何間隔、最優間隔分類器 ( Optimal Margin Classifier)、原始/對偶問題 ( Pr
Andrew Ng機器學習第一章——初識機器學習
表現 多次 無監督學習 答案 性能 分類 理想 通過 連續 機器學習的定義 計算機程序從經驗E中學習,解決某一任務T、進行某一性能度量P,通過P測定在T上的表現因E而提高。 簡而言之:程序通過多次執行之後獲得學習經驗,利用這些經驗可以使得程序的輸出結果更為理想,就是
Andrew Ng機器學習第一章——單變量線性回歸
梯度 tex 回歸 同步 常常 最好 可能 機器 http 監督學習算法工作流程 h代表假設函數,h是一個引導x得到y的函數 如何表示h函數是監督學習的關鍵問題 線性回歸:h函數是一個線性函數 代價函數 在線性回歸問題中,常常需要解決最小化問題。代
Andrew Ng機器學習(零):什麽是機器學習
中學 修正 style tar 輸入 color 情況 html 知識 1.什麽是機器學習? 自動化:讓計算機處理繁瑣和重復的工作。 編程:設計一種算法,適用於解決特定的問題。 機器學習:可以解決更廣泛的而不是特定的問題。類比於人類從經驗中學習這種活動,從已有的數據中發現自
Andrew Ng 機器學習筆記 16 :照片OCR
OCR的大概步驟 機器學習流水線(machine learning pipeline) 滑動窗體 上限分析 照片OCR是指照片光學字元識別(photo optical ch
Andrew Ng 機器學習筆記 15 :大資料集梯度下降
隨機梯度下降 隨機梯度下降原理 小批量梯度下降 小批量梯度下降vs隨機梯度下降 隨機梯度下降的收
Andrew Ng 機器學習筆記 14 :異常檢測
異常檢測問題 高斯分佈 高斯分佈中,μ和σ的關係 異常檢測的具體演算法 異常檢測演算法步驟總結 異常檢測 VS 監督學習 對不服從高斯分佈的資料進行
Andrew Ng 機器學習筆記 13 :降維(dimensionality reduction)
資料壓縮 二維降到一維 三維降到二維 視覺化資料 主成分分析(PCA) PCA的執行過程2D -&
Andrew Ng 機器學習筆記 12 :聚類
K均值 (K-means)演算法 K-Means的規範化描述 異常情況 K均值的代價函式 隨機初始化 肘部法則 (Elbow Method)