
機器學習中幾個常見模型的優缺點
阿新 • • 發佈:2019-02-09
樸素貝葉斯:優點:對小規模的資料表現很好,適合多分類任務,適合增量式訓練。
缺點:對輸入資料的表達形式很敏感(連續資料的處理方式)。
決策樹:優點:計算量簡單,可解釋性強,比較適合處理有缺失屬性值的樣本,能夠處理不相關的特徵。缺點:容易過擬合(後續出現了隨機森林,減小了過擬合現象)。
邏輯迴歸:優點:實現簡單,分類時計算量非常小,速度很快,儲存資源低。缺點:容易欠擬合,一般準確度不高;只能處理二分類問題(softmax解決多分類),需線性可分。
損失函式:
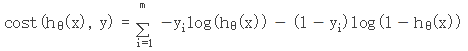
KNN:優點:思想簡單,理論成熟,既可以用來做分類也可以用來做迴歸;可用於非線性分類;訓練時間複雜度為O(n);準確度高,對資料沒有假設,對
SVM:優點:可用於線性/非線性分類,也可以用於迴歸;低泛化誤差;容易解釋;計算複雜度較低。缺點:對引數和核函式的選擇比較敏感;原始的SVM只比較擅長處理二分類問題。
損失函式:

歸一化的作用:
1. 提高梯度下降法求解最優解的速度(很難收斂甚至不能收斂);例如等高線:
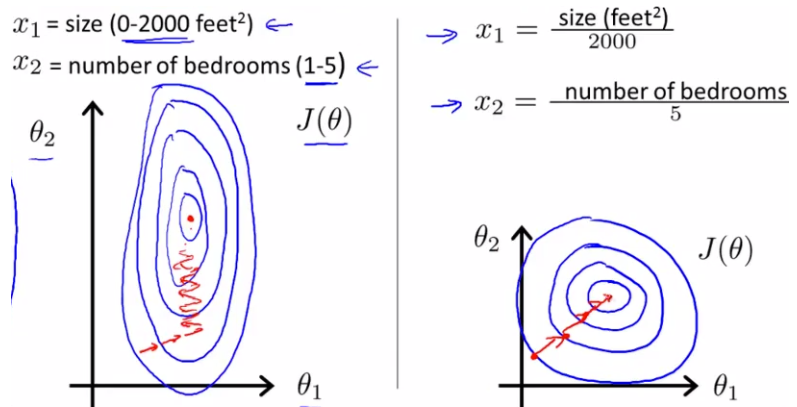
2. 有可能提高精度;一些分類器需要計算樣本之間的距離,例如KNN,若一個特徵值範圍較大,距離計算將取決於這個特徵。