
機器學習(7)——支援向量機(二):線性可分支援向量機到非線性支援向量機
線性可分支援向量機
回顧
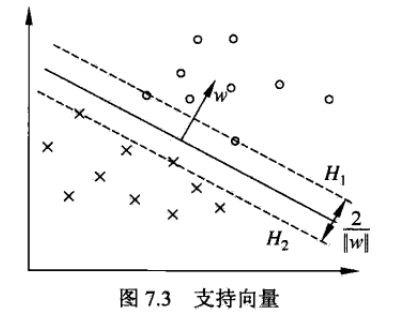
前面總結了線性可分支援向量機,知道了支援向量機的最終目的就是通過“間隔最大化” 得到最優分類器,能夠使最難區分的樣本點得到最大的分類確信度,而這些難區分的樣本就是支援向量。
還是如下圖所示,超平面
優化
上一節中我們介紹了得到上述線性可分支援向量機的方法,即最優化以下目標函式:
觀察可知,這是一個明顯的凸二次規劃問題。將其作為原始問題,應用拉格朗日對偶性,通過求解對偶問題得到原始問題的最優解。這樣求解有兩個好處:一方面是對偶問題往往更容易求解(優化效率高);二是自然引入了核函式,進而能夠推廣到非線性分類問題。首先,通過上式我們可以定義拉格朗日函式為:
其中,拉格朗日乘子
則
我們令
對偶問題與原始問題並不完全等價,因此我們用
相關推薦
機器學習(7)——支援向量機(二):線性可分支援向量機到非線性支援向量機
線性可分支援向量機 回顧 前面總結了線性可分支援向量機,知道了支援向量機的最終目的就是通過“間隔最大化” 得到最優分類器,能夠使最難區分的樣本點得到最大的分類確信度,而這些難區分的樣本就是支援向量。 還是如下圖所示,超平面H1 和 H2 支撐著中間的決
支援向量機學習筆記(一):線性可分支援向量機
SVM是用來做二類分類的模型,有簡到難分為線性可分支援向量機(或者說硬間隔支援向量機)、線性支援向量機(軟間隔支援向量機)、非線性支援向量機。下面先講最簡單的線性可分支援向量機。 以下會按順序講到: 線性可分支援向量機介紹 函式間隔與幾何間隔 支援向量機模型推導
詳解SVM系列(三):線性可分支援向量機與硬間隔最大化
支援向量機概覽(support vector machines SVM) 支援向量機是一種二類分類模型。它的基本模型是定義在特徵空間上的間隔最大(間隔最大區別於感知機)線性分類器(核函式可以用非線性的分類)。 支援向量機的學習策略是間隔最大化可形式化為一個求解凸二次規劃的問題。 也等
支援向量機(support vector machine)(一):線性可分SVM
總結一下,不然過段時間就全忘了,加油~ 1、問題描述 假設,存在兩類資料A,B,如圖1所示,A中資料對應於圖中的實心點,B中資料對應圖中的空心點,現在我們需要得到一條直線,能夠將二者進行區分,這樣的線存在無數條,如圖1中的黑色直線所示,這些線都能夠
SVM學習記錄1:線性可分硬間隔最大化
SVM是機器學習中非常流行的一個分類演算法,尤其是處理二分類問題。但是相對於其他演算法SVM可能難度稍大——至少我是這麼覺得。但是,這又是一個必須攻克的課題。我在學習SVM的時候痛下決心,將自己的學習歷程記錄在筆記本上。現在將其整理成部落格,與諸君共勉。
機器學習:SVM(一)——線性可分支援向量機原理與公式推導
原理 SVM基本模型是定義在特徵空間上的二分類線性分類器(可推廣為多分類),學習策略為間隔最大化,可形式化為一個求解凸二次規劃問題,也等價於正則化的合頁損失函式的最小化問題。求解演算法為序列最小最優化演算法(SMO) 當資料集線性可分時,通過硬間隔最大化,學習一個線性分類器;資料集近似線性可分時,即存在一小
機器學習第三個演算法SVM上(支援向量機)
突然發現看彭亮老師視訊的人很多,而且看完寫部落格的人也很多,見到一個哥們基本上把彭良老師的視訊內容完整的搬抄到部落格上,程式碼什麼的也基本沒改動,這就可以讓我先看部落格再看視訊,最後自己寫部落格這樣一種思路來學習。然後看部落格的過程中發現了好多大神。 那哥們部
SVM支援向量機-《機器學習實戰》SMO演算法Python實現(5)
經過前幾篇文章的學習,SVM的優化目標,SMO演算法的基本實現步驟,模型對應引數的選擇,我們已經都有了一定的理解,結合《機器學習實戰》,動手實踐一個基本的SVM支援向量機,來完成一個簡單的二分類任務。建立模型之前,首先看一下我們的資料,然後再用支援向量機實現分類:
【深度學習基礎-05】支援向量機SVM(上)-線性可分
Support Vector Machine 目錄 1背景 2 機器學習的一般框架 3 什麼是超平面 4 線性可區分(linear separatable)和線性不可區分(linear inseparatable) 5 如何計算超平面以及舉例 1背景 Vladim
SVM支援向量機系列理論(二) 線性可分SVM模型的對偶問題
2.1 對偶問題 2.1.1 原始問題的轉換 2.2.2 強對偶性和弱對偶性 2.3.3 SVM模型的對偶問題形式求解
機器學習 Python scikit-learn 中文文件(7)模型選擇: 選擇合適的估計器及其引數
模型選擇: 選擇合適的估計器及其引數 與官方文件完美匹配的中文文件,請訪問 https://www.studyai.cn Score, 和 cross-validated scores 交叉驗證生成器 網格搜尋與交叉驗證估計器 網格搜尋 自帶交叉驗證的估計器 模型選擇: 選擇
機器學習筆記7——異常檢測(Anomaly Detection)
前言:這是機器學習演算法的一個應用,主要用於無監督學習。一、定義 已知有了一些資料,,新來一個數據,需要判斷這個資料是否異常。給定無標籤資料集,對資料建模為P(x),x為特徵變數。如果,就是閾值,那麼就認為這是異常。二、利用高斯分佈進行異常檢測(樣本都無標記)1、條件每
機器學習sklearn庫的使用--部署環境(python2.7 windows7 64bit)
最近在學習機器學習的內容,難免地,要用到Scikit-learn(sklearn,下同)這一機器學習包。為了使用sklearn庫,我們需要安裝python2.7,pip install工具,numpy+mkl、scipy、pandas、sklearn等開源包。其
分類演算法----線性可分支援向量機(SVM)演算法的原理推導
支援向量機(support vector machines, SVM)是一種二分類模型,它的基本模型是定義在特徵空間上的間隔最大的線性分類器, 其目標是在特徵空間中找到一個分離超平面,能將例項分到不同的類,分離超平面將特徵空間劃分為兩部分,正類和負類,法向量 指向的為正類,
常用牛人主頁鏈接(計算機視覺、模式識別、機器學習相關方向,陸續更新。。。。)【轉】
short psu works charles 貝葉斯 learning 數學 ocr 相關 轉自:http://blog.csdn.net/goodshot/article/details/53214935 目錄(?)[-] The Kalman
機器學習筆記 1 LMS和梯度下降(批梯度下降) 20170617
temp eas 理解 import 樣本 alt mes show 超過 # 概念 LMS(least mean square):(最小均方法)通過最小化均方誤差來求最佳參數的方法。 GD(gradient descent) : (梯度下降法)一種參數更新法則。可以作為L
Andrew Ng機器學習筆記+Weka相關算法實現(四)SVM和原始對偶問題
優化問題 坐標 出了 變量 addclass fun ber 找到 線性 這篇博客主要解說了Ng的課第六、七個視頻,涉及到的內容包含,函數間隔和幾何間隔、最優間隔分類器 ( Optimal Margin Classifier)、原始/對偶問題 ( Pr
機器學習&數據挖掘筆記_16(常見面試之機器學習算法思想簡單梳理)
回歸 utl lsa 多維 包含 的人 相互 oss 一個用戶 【轉】 前言: 找工作時(IT行業),除了常見的軟件開發以外,機器學習崗位也可以當作是一個選擇,不少計算機方向的研究生都會接觸這個,如果你的研究方向是機器學習/數據挖掘之類,且又對其非常感興趣的話
【機器學習】谷歌的速成課程(一)
label spa dev 分類 ram 做出 org ron 表示 問題構建 (Framing) 什麽是(監督式)機器學習?簡單來說,它的定義如下: 機器學習系統通過學習如何組合輸入信息來對從未見過的數據做出有用的預測。 標簽 在簡單線性回歸中,標簽是我們要預測
機器學習--DIY筆記與感悟--②決策樹(1)
lis ... 編寫代碼 需要 總結 初始化 對數 三分 xtend 在完成了K臨近之後,今天我們開始下一個算法--->決策樹算法。 一、決策樹基礎知識 如果突然問你"有一個陌生人叫X,Ta今天需要帶傘嗎?", 你一定會覺得這個問題就像告訴你"兩千米外有一個超市,