
爬蟲—新浪微博(登陸訪問、cookie訪問)
一、思路:
登入 ====>進入指定頁面 ====>獲取cookie ====> 帶cookie訪問相關頁面。
注:貌似微博頁面稍微改了一下:現在通過登入直接進入個人中心的過程中所獲取的cookie不能用於訪問其他頁面,因此,才會在登陸後加一層進入指定頁面用於獲取可用的cookie。
二、程式碼:
1、登入並獲取cookie(url:https://login.sina.com.cn/signup/signin.php?entry=sso)

2、cookie訪問(demo)
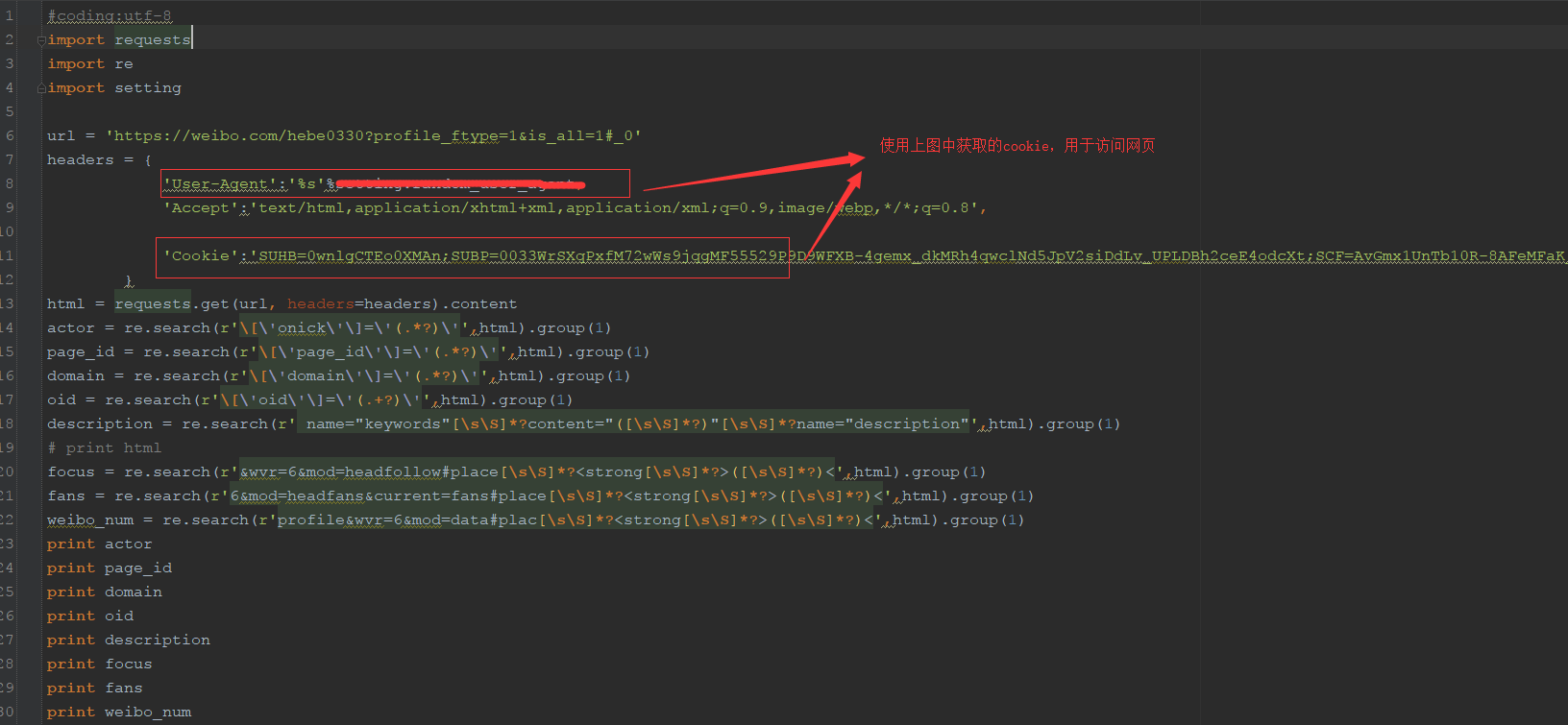
requests方式:
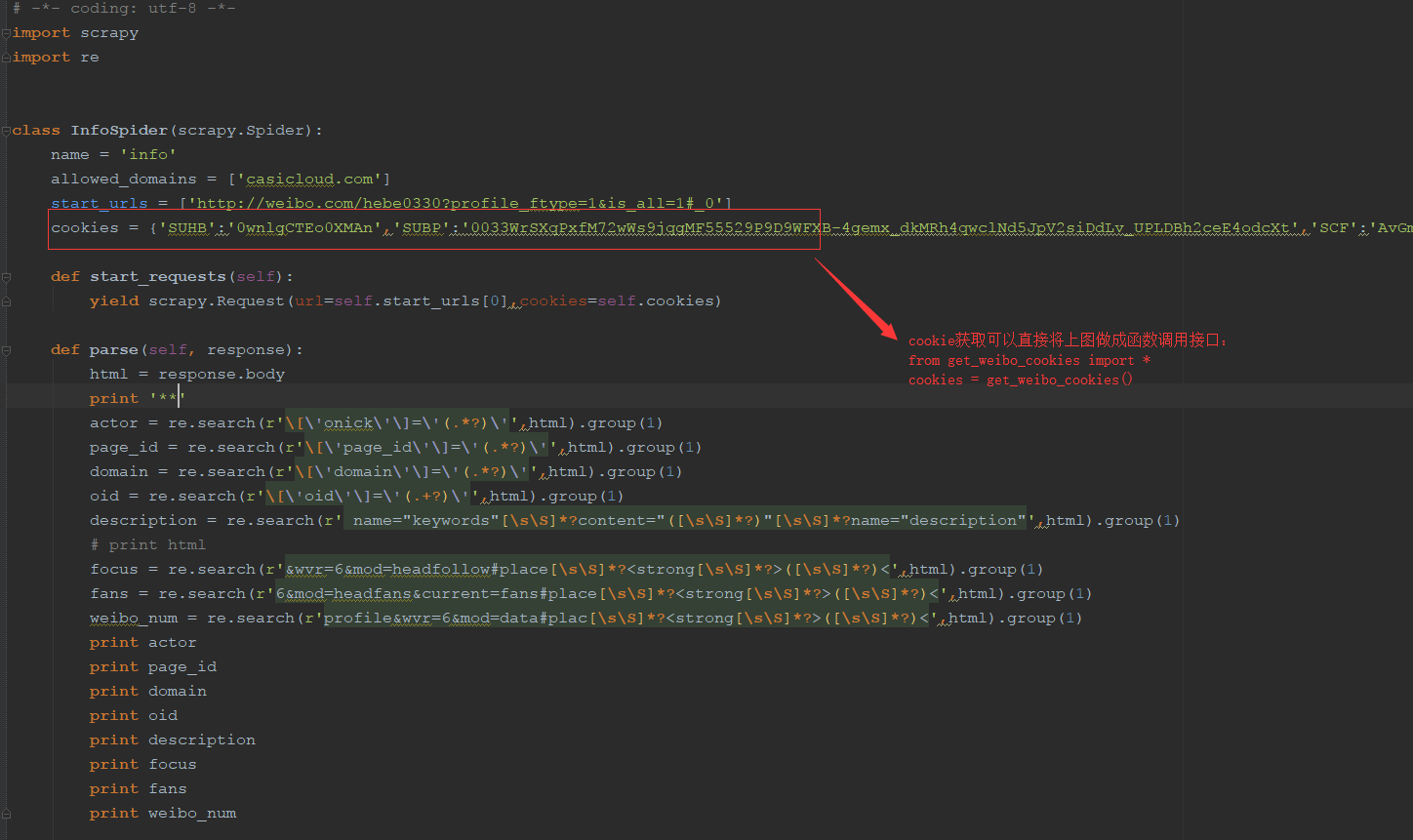
scrapy方式:
相關推薦
爬蟲—新浪微博(登陸訪問、cookie訪問)
一、思路: 登入 ====>進入指定頁面 ====>獲取cookie ====> 帶cookie訪問相關頁面。 注:貌似微博頁面稍微改了一下:現在通過登入直接進入個人中心的過程中所獲取的cookie不能用於訪問其他頁面,因此,才會在登陸後加一層進
java 模擬登入新浪微博(通過cookie)
java模擬登入新浪微博(通過cookie) 這幾天一直在研究新浪微博的爬蟲,發現爬取微博的資料首先要登入。本來打算是通過賬號和密碼模擬瀏覽器登入。但是現在微博的登入機制比較複雜。通過賬號密碼還沒有登入成功QAQ。所以就先記錄下,通過cookie直接訪問自
Python: 傳送新浪微博(使用oauth2)
1、申請個應用,得到App Key和App Secret 2、設定授權回撥頁地址,如下,如果不設定,打開回調頁時會報錯“error:redirect_uri_mismatch”,這一點一定要注意。 3、程式碼: #!/usr/bin/env python # -
使用weibo js,新浪微博三方登陸,帳號繫結。
最近在做利用三方資源的東西,由於以往做的是企業管理(ERP)的內網系統,初涉外網資源的網際網路系統摸索了很長時間。 對於網上充斥的各種教程,我真是無力吐槽,我決定把這期間的各種問題以及相應的解決辦法拿出來分享 。教程分為兩個階段:一是賬號登入,二是三方賬號與
1-新浪微博爬蟲-(2017-05-09)
1 爬使用者的資訊 1-1 哪裡找cookies 1-2 哪裡找使用者資訊 2 爬使用者發過的所有部落格 2
新浪微博爬蟲分享(一天可抓取 1300 萬條資料)
爬蟲功能: 此專案和QQ空間爬蟲類似,主要爬取新浪微博使用者的個人資訊、微博資訊、粉絲和關注(詳細見此)。 程式碼獲取新浪微博Cookie進行登入,可通過多賬號登入來防止新浪的反扒(用來登入的賬號可從淘寶購買,一塊錢七個)。 專案爬的是新浪微
新浪微博登陸以及傳送微博(附python原始碼)
說明 本文主要記錄分析新浪微博登陸以及傳送文字和圖片微博的詳細過程 分析 登陸入口選擇的是新浪通行證登陸入口 https://login.sina.com.cn/signup/signin.
爬蟲計劃(一)--實現新浪微博自動登入和釋出內容
看到網上很多人都對新浪微博進行爬蟲,正巧公司也有外接的小活,因此本人也加入到爬蟲的佇列,開始研究新浪微博。歷時半個月,一路上遇到諸多阻礙,還好沒有放棄,最終實現了對新浪微博的自動登入以及自動釋出內容!下面本人分多個章節把我的爬蟲經歷以及方法分享給大家,最後會附上程式碼(
[Javascript] 爬蟲 模擬新浪微博登陸
1 agent('http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.11)', 2 {type: 'POST', headers: { Referer : 'http://weibo.com
使用網頁爬蟲(高階搜尋功能)蒐集含關鍵詞新浪微博資料
作為國內社交媒體的領航者,很遺憾,新浪微博沒有提供以“關鍵字+時間+區域”方式獲取的官方API。當我們看到國外科研成果都是基於某關鍵字獲得的社交媒體資料,心中不免涼了一大截,或者轉戰推特。再次建議微博能更開放些!1、切入點慶幸的是,新浪提供了高階搜尋功能。找不到?這個功能需要
python 爬蟲1 開始,先拿新浪微博開始
大括號 版本 install esp con data- 定位 ble Language 剛剛開始學。 目的地是兩個。一個微博,一個貼吧 存入的話,臨時還沒想那麽多。先存到本地目錄吧 分詞和推薦後面在整合 mysql mongodb hadoop redius 後面在用
java parse 帶英文單詞的日期字符串 轉 date (轉化新浪微博api返回的時間)
site ats 技術 cnblogs local 隨筆 html5 null 就會 拂曉風起 專註前端技術cocos2d、js、flash、html5,聯系:[email protected]/* */,請不吝推薦簡歷。 博客園 首頁
apigw鑒權分析(1-4)新浪微博開放平臺 - 鑒權分析
取消 spa 控制 server 信息 des 包含 flash poi 一、訪問入口 http://open.weibo.com/wiki/%E6%8E%88%E6%9D%83%E6%9C%BA%E5%88%B6%E8%AF%B4%E6%98%8E 微博開放接口的
(一一六)新浪微博client的離線緩存實現思路
aso 離線 要求 北京 ... comm roo rep 功能 上一節(一一五)利用NSKeyedArchiver實現隨意對象轉為二進制介紹了將隨意對象轉化為二進制數據和還原的方法。可用於實現本節介紹的微博數據離線緩存。 通過新浪官方的API能夠發現,返回的微博
iOS之 接入新浪微博 SDK(微信支付) 的坑(registerApp 的問題)
com .net symbols object type lan creat manager -o 最近在做一個 iOS 的 cocos2d-x 項目接入新浪微博 SDK 的時候被“坑”了,最後終於順利的解決了。發現網上也有不少人遇到一樣的問題,但是能找到的數量有限的解決辦
Python爬蟲開源項目代碼,爬取微信、淘寶、豆瓣、知乎、新浪微博、QQ、去哪網等 代碼整理
http server 以及 pro 模擬登錄 取數 存在 漏洞 搜狗 作者:SFLYQ 今天為大家整理了32個Python爬蟲項目。 整理的原因是,爬蟲入門簡單快速,也非常適合新入門的小夥伴培養信心。所有鏈接指向GitHub,祝大家玩的愉快~ 1、WechatSogou
全程模擬新浪微博登錄(2015)
star php utf 版本 get lag spa ckey phoenix 非常久之前就了解過模擬登錄的過程。近期對python用的比較多,想來練練手,就想實現
android 微博sdk 整合 檔案不存在(8998) 您所訪問的站點在新浪微博的認證失敗,錯誤碼 21322
問題:使用mSsoHandler.authorize(new AuthListener()); 請求授權 微部落格戶端報 檔案不存在(8998) 使用mSsoHandler.authorizeWeb(new Au
新浪微博爬蟲v1.0
心血來潮想看看自己這幾年都去過什麼地方,因為我的動態資訊基本上都發布在微博上面的,上面也記錄了地址,
7-3 出租 (20 分) 下面是新浪微博上曾經很火的一張圖:
一時間網上一片求救聲,急問這個怎麼破。其實這段程式碼很簡單,index陣列就是arr陣列的下標,index[0]=2 對應 arr[2]=1,index[1]=0 對應 arr[0]=8,index[2]=3 對應 arr[3]=0,以此類推…… 很容易得到電話號碼是18013820100。