
機器學習C6筆記:正則化文本回歸(交叉驗證,正則化,lasso)
非線性模型
廣義加性模型
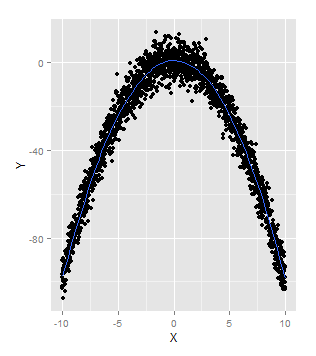
Generalized Additive Model (GAM)同過使用ggplot2程式包中的geom_smooth函式,使用預設的smooth函式,就可以擬合GAM模型:
set.seed(1)
x <- seq(-10, 10, by = 0.01)
y <- 1 - x ^ 2 + rnorm(length(x), 0, 5)
ggplot(data.frame(X = x, Y = y), aes(x = X, y = Y)) +
geom_point() +
geom_smooth(se = FALSE)
避免過擬合的方法
過擬合是指: 一個模型擬合了部分噪聲,而不是真正資料.
一個模型的好壞取決於它能否準確預測未來的未知資料. 若沒有未來的資料,一種變通的方法是: 可以把過去的資料分為兩部分,用其中一份擬合模型, 用另一份資料模擬”將來的”資料.
交叉驗證
交叉驗證的核心思想, 就是在模型擬合的過程中並不適用全部的歷史資料,而是保留了一部分資料,用來模擬未來的資料,對模型進行檢驗.
ex. 利用正弦波資料來演示通過交叉驗證來幫助選擇多項式迴歸的次數.
1. 建立正弦波資料
# Twelfth code snippet
set.seed(1)
x <- seq(0, 1, by = 0.01) - 隨機抽樣避免系統性差異
隨機拆分訓練集和測試集, 避免有系統性差異, 比如: 你可能拿較小的x來訓練,而拿較大的x來測試. 利用R語言的sample函式可以提供隨機性,他可以從一個給定的向量中進行隨機取樣. - 利用RMSE度量效果
# Fourteenth code snippet
rmse <- function(y, h)
{
return(sqrt(mean((y - h) ^ 2)))
}- 進行1-12次迴歸計算RMSE
# Fifteenth code snippet 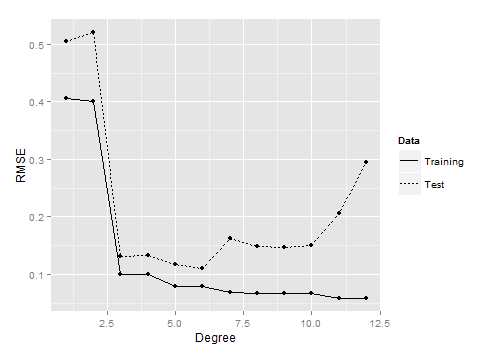
從上圖可以看到,中間大小的次數對應的模型在測試資料上表現最好.
一方面,當次數過低,如1或2時,模型沒有能擬合到真正的模式, 訓練集和測試集的效果都非常差. 當一個模型過於簡單, 以致連訓練資料都擬合不夠好是,稱之為欠擬合(underfitting).
另一方面, 次數太大,如11或12時, 可以看到模型在測試,資料上的表現又開始變差了. 這是因為模型變得太複雜, 擬合了在測試資料中並不存在的而在訓練資料中存在的噪音.
當模型開始擬合訓練資料中的噪音時,就稱之為發生了過擬合.
可以從另一個角度理解過擬合: 隨著次數不斷增加, 訓練誤差和測試誤差變化趨勢開始不一致了—訓練誤差持續變小,而測試誤差變大. 模型對於它沒見過的資料都沒有泛化能力—導致了過擬合.
正則化避免過擬合
使用glmnet程式包, 參考網址:資料鋪子(很棒的小鋪,有許多r語言的文章)
The Elements of
Statistical Learning
摘錄其中的glmnet包的講解:
glmnet包和演算法
glmnet包是關於Lasso and elastic-net regularized generalized linear models。 作者是Friedman, J., Hastie, T. and Tibshirani, R這三位。
這個包採用的演算法是迴圈座標下降法(cyclical coordinate descent),處理的模型包括 linear regression,logistic and multinomial regression models, poisson regression 和 the Cox model,用到的正則化方法就是l1範數(lasso)、l2範數(嶺迴歸)和它們的混合 (elastic net)。
座標下降法是關於lasso的一種快速計算方法(是目前關於lasso最快的計算方法),其基本要點為: 對每一個引數在保持其它引數固定的情況下進行優化,迴圈,直到係數穩定為止。這個計算是在lambda的格點值上進行的。
例子:
產生資料
# Twenty-first code snippet
set.seed(1)
x <- seq(0, 1, by = 0.01)
y <- sin(2 * pi * x) + rnorm(length(x), 0, 0.1)
n <- length(x)
indices <- sort(sample(1:n, round(0.5 * n)))
training.x <- x[indices]
training.y <- y[indices]
test.x <- x[-indices]
test.y <- y[-indices]
df <- data.frame(X = x, Y = y)
training.df <- data.frame(X = training.x, Y = training.y)
test.df <- data.frame(X = test.x, Y = test.y)
rmse <- function(y, h)
{
return(sqrt(mean((y - h) ^ 2)))
}進行glmnet迴歸
library('glmnet')
glmnet.fit <- with(training.df, glmnet(poly(X, degree = 10), Y))> glmnet.fit
Call: glmnet(x = poly(X, degree = 10), y = Y)
Df %Dev Lambda
[1,] 0 0.0000 0.569600
[2,] 1 0.1125 0.519000
[3,] 1 0.2060 0.472900
[4,] 1 0.2836 0.430900
[5,] 1 0.3480 0.392600
...
[60,] 8 0.9906 0.002354
[61,] 8 0.9906 0.002145
[62,] 8 0.9907 0.001954
[63,] 8 0.9907 0.001780
[64,] 8 0.9907 0.001622列表中最靠前的是glmnet函式執行最強正則化的結果,最靠後的是glmnet函式執行最弱正則化的結果.
df: 表示模型中的非零權重有幾個.但幷包括截距項,它不應該正則化.
dev: 是指R方的值, 最後一行是直接使用lm函式時得到的r方值是一樣的,因為lm沒用使用任何正則化, 介於完全正則化和完全正則化的兩個極端之間的模型dev值介於11%~99%之間.
lambda:在第7章詳解.直觀的概念是: lambda很大,說明對模型的複雜度很在意, 對模型施加很大的”懲罰”, 這個懲罰將迫使所有的模型權重趨向於0; 反之, lambda很小, 說明對模型的複雜度不關心, 對模型的複雜度不怎麼”懲罰”. 在極端情況下, 我們可以把lambda設為0, 就會得到一個完全沒有正則化的線性迴歸模型,就像直接使用lm函式得到的模型一樣.
尋找最優lambda的方法: 可以用交叉驗證.
交叉驗證
對lambda進行迴圈, 求RMSE.
lambdas <- glmnet.fit$lambda
performance <- data.frame()
for (lambda in lambdas)
{
performance <- rbind(performance,
RMSE = rmse(test.y,
with(test.df,
predict(glmnet.fit,
poly(X, degree = 10),s = lambda)))))# 利用測試資料在不同lambda不同的情況下進行計算RMSE
}畫圖
# Twenty-third code snippet
ggplot(performance, aes(x = Lambda, y = RMSE)) +
geom_point() +
geom_line()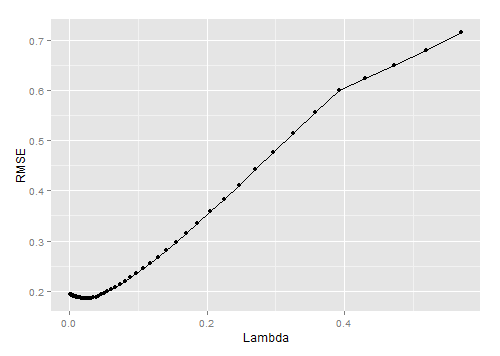
從上圖可以看出lambda=0.05時, 模型效果最好.
利用最優lambda訓練全部模型
# Twenty-fourth code snippet
best.lambda <- with(performance, Lambda[which(RMSE == min(RMSE))])
glmnet.fit <- with(df, glmnet(poly(X, degree = 10), Y))
# Twenty-fifth code snippet
coef(glmnet.fit, s = best.lambda)> coef(glmnet.fit, s = best.lambda)
11 x 1 sparse Matrix of class "dgCMatrix"
1
(Intercept) 0.0101667
1 -5.2132586
2 .
3 4.1759498
4 .
5 -0.4643476
6 .
7 .
8 .
9 .
10 . 從結果中看到, 雖然有10個特徵可供選擇, 但實際上我們只是使用了3個.這正是正則化背後的主要思想: 寧願選擇像這樣比較簡單的模型,也不選擇複雜的模型.
參考書籍:機器學習實用案例解析