
【目標檢測】Mask RCNN演算法詳解
1 總體架構及與faster RCNN的比較
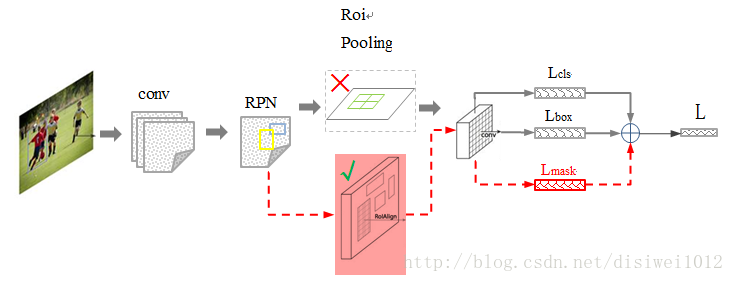
其中黑色部分為原來的 Faster-RCNN,紅色部分為在 Faster網路上的修改,總體流程如下:
1)輸入影象;
2)將整張圖片輸入CNN,進行特徵提取;
3)用FPN生成建議視窗(proposals),每張圖片生成N個建議視窗;
4)把建議視窗對映到CNN的最後一層卷積feature map上;
5)通過RoI Align層使每個RoI生成固定尺寸的feature map;
6)最後利用全連線分類,邊框,mask進行迴歸。
與faster RCNN區別:
1)使用ResNet101網路
2)將 Roi Pooling 層替換成了 RoiAlign;
3)新增並列的 Mask 層;
4)由RPN網路轉變成FPN網路
2 ResNet101網路
2.1 產生背景
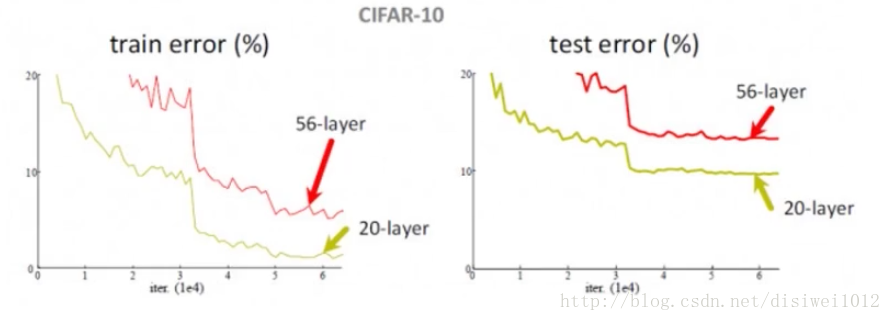
網路的深度對於特徵提取具有至關重要的作用,實驗證得,如果簡單的增加網路深度,會引起退化問題[Degradation問題],即準確率先上升然後達到飽和,再持續增加深度會導致準確率下降。該實驗說明了深度網路不能很好地被優化,也就是優化器很難去利用多層網路擬合函式。
這就產生了一個衝突,即需要多層網路,但多層網路又很難擬合函式,故提出了殘差網路。
2.2 解決退化問題
假如目前有一個可以工作的很好的網路A,這時來了一個比A更深的網路B,只需要讓網路B的前一部分與A完全相同,後一部分只實現一個恆等對映,這樣網路B最起碼能獲得與A相同的效能,而不至於更差。
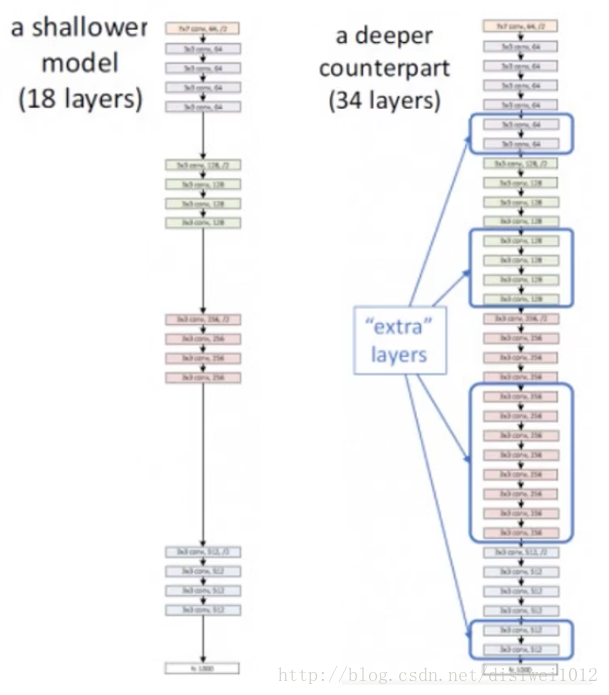
如上圖所示,18層網路結構已經能達到最優效果,如果轉化成34層網路則會導致準確率下降,按照上述思想,應該將34層網路中多出的層(extra layers)只起到恆等對映的作用,即x經過extra layer結果還是x。

對於普通網路,H(x)是我們希望得到的某個對映,我們希望用兩層非線性的疊加網路來擬合出H(x)。

上圖是是論文中提出的殘差網路結構。殘差網路希望讓兩層非線性疊加網路先擬合出F(x),接著H(x) = F(x)+ X。當在一個5層的網路中,如果前4層已經達到一個最優的函式,那麼第5層就沒有必要了,這個採用殘差網路的結構,第5層網路的F(x)就會逼近0,起到了和4層網路等價的作用。把F(x)訓練成0,比直接把第5層訓練成等價對映更簡單。
2.3 ResNet101在Mask RCNN中的應用
在mask rcnn網路中,第一部分就是使用ResNet101進行特徵圖的提取。
對於引數padding=’same’,輸出的形狀計算如下:

其中,W為輸入的size,S為步長,⌈⌉為向上取整符號。每一個殘差單元將原圖的尺寸縮小為二分之一。
def resnet_graph(input_image, architecture, stage5=False):
assert architecture in ["resnet50", "resnet101"]
# Stage 1
x = KL.ZeroPadding2D((3, 3))(input_image)
x = KL.Conv2D(64, (7, 7), strides=(2, 2), name='conv1', use_bias=True)(x)
x = BatchNorm(axis=3, name='bn_conv1')(x)
x = KL.Activation('relu')(x)
C1 = x = KL.MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x)
# Stage 2
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
C2 = x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
# Stage 3
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
C3 = x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
# Stage 4
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
block_count = {"resnet50": 5, "resnet101": 22}[architecture]
for i in range(block_count):
x = identity_block(x, 3, [256, 256, 1024], stage=4, block=chr(98 + i))
C4 = x
# Stage 5
if stage5:
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b')
C5 = x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c')
else:
C5 = None
return [C1, C2, C3, C4, C5]3 FPN網路(feature pyramid networks)
3.1產生背景
我們知道,R-CNN系列是在得到的最後一層特徵圖上進行特徵提取(也就是RPN),從而進行目標識別的。但是這樣做存在的弊端在於,頂層特徵中忽略了小物體的一些資訊,因此只根據頂層特徵進行目標識別,不能完整地反映小目標物體的資訊。如果可以結合多層級的特徵,就可以大大提高多尺度檢測的準確性。
而FPN網路則使用多層特徵圖進行預測。
3.2演算法框架

演算法結構可以分為兩個部分:
1)自下而上的卷積神經網路(上圖左)
其實就是卷積神經網路的前向過程。在前向過程中,特徵圖的大小在經過某些層後會改變,而在經過其他一些層的時候不會改變,作者將不改變特徵圖大小的層歸為一個階段,因此每次抽取的特徵都是每個階段的最後一個層的輸出,這樣就能構成特徵金字塔(feature pyramid)
具體來說,對於ResNet101,使用了每個階段的最後一個殘差結構的特徵啟用輸出。將這些殘差模組輸出表示為{C2, C3, C4, C5},對應於conv2,conv3,conv4和conv5的輸出。

2)自上而下過程(上圖右)
就是上取樣(upsampling)的過程,而橫向連線則是將上取樣的結果和自底向上生成的相同大小的feature map進行融合,將底層特徵圖上取樣成2倍即可,上取樣後的特徵圖具有和下一層的特徵圖相同的大小。
經過融合之後的特徵圖具有更豐富的資訊。1*1卷積核的作用主要使得各層特徵圖通道數相同。
P5 = KL.Conv2D(256, (1, 1), name='fpn_c5p5')(C5)
P4 = KL.Add(name="fpn_p4add")
([KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(256, (1, 1), name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")
([KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(256, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")
([KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
KL.Conv2D(256, (1, 1), name='fpn_c2p2')(C2)])在融合之後還會再採用3*3的卷積核對每個融合結果進行卷積,目的是消除上取樣的混疊效應(?),如此就得到了一個新的特徵圖。這樣一層一層地迭代下去,就可以得到多個新的特徵圖。假設生成的特徵圖結果是P2,P3,P4,P5,它們和原來自底向上的卷積結果C2,C3,C4,C5一一對應。
P2 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p5")(P5)
P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)4 ProposalLayer
該步驟用於獲取最後的候選框(Proposal),形如[y1,x1,y2,x2]。
使用通過anchors機制獲取的,和通過RPN網路獲取的rpn_probs[bg_prob,fg_prob]、rpn_bbox[dy,dx,log(dh),log(dw)]作為輸入資料,獲取最終的候選框,但求得的候選框會超過2萬+,可以通過以下三種方式將候選框的數量固定在一定範圍。
1)top-N
rpn_probs用於標記某個候選框為前景和背景的概率值,通過top-N可以篩選出概率最後的前N個候選框。
2)去掉超出圖片範圍候選框
3)非極大值抑制(NMS演算法)

如上圖(左)中,雖然幾個框都檢測到了人臉,但是我不需要這麼多的框,我需要找到一個最能表達人臉的框。通過NMS演算法能夠實現。
先假設有6個矩形框,根據分類器類別分類概率做排序,從小到大分別屬於人臉的概率分別為A、B、C、D、E、F。
①從最大概率矩形框F開始,分別判斷A~E與F的重疊度IOU是否大於某個設定的閾值;
②假設B、D與F的重疊度超過閾值,那麼就扔掉B、D;並標記第一個矩形框F,是我們保留下來的
③從剩下的矩形框A、C、E中,選擇概率最大的E,然後判斷E與A、C的重疊度,重疊度大於一定的閾值,那麼就扔掉;並標記E是我們保留下來的第二個矩形框。
④就這樣一直重複,找到所有被保留下來的矩形框。
5 分類、迴歸、Mask損失值
5.1 ROI Pooling
在faster rcnn中,anchors經過proposal layer升級為proposal,需要經過ROI Pooling進行size的歸一化後才能進入全連線網路,也就是說ROI Pooling的主要作用是將proposal調整到統一大小。步驟如下:
- 將proposal對映到feature map對應位置
- 將對映後的區域劃分為相同大小的sections
- 對每個sections進行max pooling/avg pooling操作
5.1.1舉例說明:
考慮一個8*8大小的feature map,經過一個ROI Pooling,以及輸出大小為2*2.
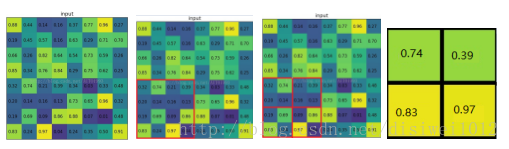
1)輸入的固定大小的feature map (圖一)
2)region proposal 投影之後位置(左上角,右下角座標):(0,4),(4,4)(圖二)
3)將其劃分為(2*2)個sections(因為輸出大小為2*2),我們可以得到(圖三)
4)對每個section做max pooling,可以得到(圖四)
5.2 ROI Align
5.2.1 ROI Pooling存在問題:

如上圖所示,這是一個Faster-RCNN檢測框架。輸入一張800*800的圖片,圖片上有一個665*665的包圍框(框著一隻狗)。圖片經過主幹網路提取特徵後,特徵圖縮放步長(stride)為32。因此,影象和包圍框的邊長都是輸入時的1/32。800正好可以被32整除變為25。但665除以32以後得到20.78,帶有小數,於是ROI Pooling 直接將它量化成20。接下來需要把框內的特徵池化7*7的大小,因此將上述包圍框平均分割成7*7個矩形區域。顯然,每個矩形區域的邊長為2.86,又含有小數。於是ROI Pooling 再次把它量化到2。經過這兩次量化,候選區域已經出現了較明顯的偏差(如圖中綠色部分所示)。
更重要的是,該層特徵圖上0.1個畫素的偏差,縮放到原圖就是3.2個畫素。那麼0.8的偏差,在原圖上就是接近30個畫素點的差別,這一差別不容小覷。
5.2.2 解決方案ROI Align:
1)遍歷每一個候選區域,保持浮點數邊界不做量化。
2)將候選區域分割成k x k個單元,每個單元的邊界也不做量化。
3)在每個單元中計算固定四個座標位置(通常是固定一個或者四個),用雙線性內插的方法計算出這四個位置的值,然後進行最大池化操作

5.3 損失函式
# Losses
rpn_class_loss = KL.Lambda(lambda x: rpn_class_loss_graph(*x), name="rpn_class_loss")(
[input_rpn_match, rpn_class_logits])
rpn_bbox_loss = KL.Lambda(lambda x: rpn_bbox_loss_graph(config, *x), name="rpn_bbox_loss")(
[input_rpn_bbox, input_rpn_match, rpn_bbox])
class_loss = KL.Lambda(lambda x: mrcnn_class_loss_graph(*x), name="mrcnn_class_loss")(
[target_class_ids, mrcnn_class_logits, active_class_ids])
bbox_loss = KL.Lambda(lambda x: mrcnn_bbox_loss_graph(*x), name="mrcnn_bbox_loss")(
[target_bbox, target_class_ids, mrcnn_bbox])
mask_loss = KL.Lambda(lambda x: mrcnn_mask_loss_graph(*x), name="mrcnn_mask_loss")(
[target_mask, target_class_ids, mrcnn_mask])rpn_class_loss:RPN網路分類損失函式
rpn_bbox_loss:RPN網路迴歸損失函式
class_loss:分類損失函式
bbox_loss:迴歸損失函式
mask_loss:Mask迴歸損失函式
6 COCO資料集(2014)

6.1 JSON標註檔案詳解
images陣列元素的數量等同於劃入訓練集(或者測試集)的圖片的數量;
annotations陣列元素的數量等同於訓練集(或者測試集)中bounding box的數量;
categories陣列元素的數量為92(2014年);
{
"info": info,
"licenses": [license],
"images": [image],
"annotations": [annotation],
"categories": [categories]
}— > Info
"info": {
"description": "This is stable 1.0 version of the 2014 MS COCO dataset.",
"url": "http://mscoco.org",
"version": "1.0",
"year": 2014,
"contributor": "Microsoft COCO group",
"date_created": "2015-01-27 09:11:52.357475"
}— >Images是包含多個image例項的陣列,對於一個image型別的例項:
{
"license": 5,
"file_name": "COCO_train2014_000000057870.jpg",
"coco_url": "http://mscoco.org/images/57870",
"height": 480,
"width": 640,
"date_captured": "2013-11-14 16:28:13",
"flickr_url": "http://farm4.
staticflickr.com/3153/2970773875_164f0c0b83_z.jpg",
"id": 57870
}— > licenses是包含多個license例項的陣列,對於一個license型別的例項:
{
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/",
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License"
}— > annotations欄位是包含多個annotation例項的一個數組,annotation型別本身又包含了一系列的欄位,如這個目標的category id和segmentation mask。segmentation格式取決於這個例項是一個單個的物件(即iscrowd=0,將使用polygons格式)還是一組物件(即iscrowd=1,將使用RLE格式)。如下所示:
annotation{
"id": int,
"image_id": int,
"category_id": int,
"segmentation": RLE or [polygon],
"area": float,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1,
}注意,只要是iscrowd=0那麼segmentation就是polygon格式;只要iscrowd=1那麼segmentation就是RLE格式。另外,每個物件(不管是iscrowd=0還是iscrowd=1)都會有一個矩形框bbox ,矩形框左上角的座標和矩形框的長寬會以陣列的形式提供。
area是area of encoded masks,是標註區域的面積。如果是矩形框,那就是高乘寬;如果是polygon或者RLE,那就複雜點。
annotation結構中的categories欄位儲存的是當前物件所屬的category的id,以及所屬的supercategory的name
{
"segmentation": [[510.66,423.01,511.72,420.03,510.45......]],
"area": 702.1057499999998,
"iscrowd": 0,
"image_id": 289343,
"bbox": [473.07,395.93,38.65,28.67],
"category_id": 18,
"id": 1768
}polygon格式比較簡單,這些數按照相鄰的順序兩兩組成一個點的xy座標,如果有n個數(必定是偶數),那麼就是n/2個點座標。
如果iscrowd=1,那麼segmentation就是RLE格式(segmentation欄位會含有counts和size陣列),在json檔案中gemfield挑出一個這樣的例子,如下所示:
{
'counts': [272, 2, 4, 4, 4, 4, 2, 9, 1, 2, 16, 43, 143, 24......],
'size': [240, 320]}上面的segmentation中的counts陣列和size陣列共同組成了這幅圖片中的分割 mask。其中size是這幅圖片的寬高,然後在這幅影象中,每一個畫素點要麼在被分割(標註)的目標區域中,要麼在背景中。很明顯這是一個bool量:如果該畫素在目標區域中為true那麼在背景中就是False;如果該畫素在目標區域中為1那麼在背景中就是0。對於一個240x320的圖片來說,一共有76800個畫素點,根據每一個畫素點在不在目標區域中,我們就有了76800個bit,比如像這樣(隨便寫的例子,和上文的陣列沒關係):00000111100111110…;但是這樣寫很明顯浪費空間,我們直接寫上0或者1的個數不就行了嘛(Run-length encoding),於是就成了54251…,這就是上文中的counts陣列。
— > categories是一個包含多個category例項的陣列,而category結構體描述如下:
{
"supercategory": "person",
"id": 1,
"name": "person"
}