
度量學習(meritc learning)思考
阿新 • • 發佈:2019-02-07
經典論文:
簡單總結下個人對mertic learning的認知:
①本質是學習一個embedding space,也可以理解為對映空間,使得同類的物體距離更近,不同類物體距離更遠。
②應用場景:a.大量的類別,如人臉;b.每類訓練樣本較少的情況
③與傳統分類任務相比,度量學習能學習到距離度量的一般概念;在學習到的度量空間與近鄰推理相容。
④學習重點:訓練樣本的組合方式及損失函式的定義。樣本有兩兩組合,三元組合,也有下面論文的lifted structured embedding結構;
得到embedding space,可當作特徵向量進行人臉驗證(k-NN分類)、識別(和哪個emdedding距離最近)、聚類。
例如在《FaceNet: A Unified Embedding for Face Recognition and Clustering》中
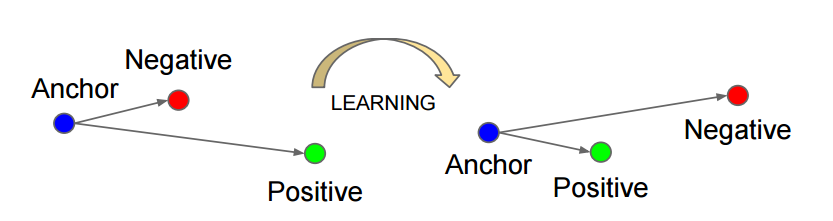
如上圖所示,triplet是一個三元組,這個三元組是這樣構成的:從訓練資料集中隨機選一個樣本,稱為Anchor,然後再隨機選取一個和Anchor 屬於同一類的樣本和不同類的樣本,這兩個樣本分別稱為Positive (記為x_p)和Negative (記為x_n),由此構成一個(Anchor,Positive,Negative)三元組。
針對三元組中的每個元素(樣本),訓練一個網路,得到三個元素的特徵表達(Embedded Space),分別記為:
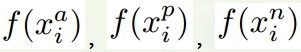
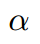 。
。
公式化的表示就是:
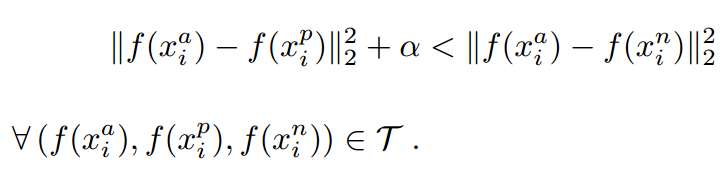
對應的目標函式: 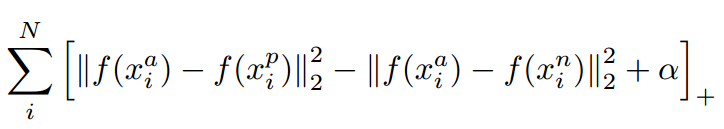
這裡距離用歐式距離度量,+表示[]內的值大於零的時候,取該值為損失,小於零的時候,損失為零。