
基於深度學習的人臉識別系統系列(Caffe+OpenCV+Dlib)——【三】使用Caffe的MemoryData層與VGG網路模型提取Mat的特徵
原文地址:http://m.blog.csdn.net/article/details?id=52456548
前言
基於深度學習的人臉識別系統,一共用到了5個開源庫:OpenCV(計算機視覺庫)、Caffe(深度學習庫)、Dlib(機器學習庫)、libfacedetection(人臉檢測庫)、cudnn(gpu加速庫)。
用到了一個開源的深度學習模型:VGG model。
最終的效果是很讚的,識別一張人臉的速度是0.039秒,而且最重要的是:精度高啊!!!
CPU:intel i5-4590
GPU:GTX 980
系統:Win 10
OpenCV版本:3.1(這個無所謂)
Caffe版本:Microsoft caffe (微軟編譯的Caffe,安裝方便,在這裡安利一波)
Dlib版本:19.0(也無所謂
CUDA版本:7.5
cudnn版本:4
libfacedetection:6月份之後的(這個有所謂,6月後出了64位版本的)
這個系列純C++構成,有問題的各位朋同學可以直接在部落格下留言,我們互相交流學習。
====================================================================
本篇是該系列的第三篇部落格,介紹如何使用VGG網路模型與Caffe的 MemoryData層去提取一個OpenCV矩陣型別Mat的特徵。
思路
VGG網路模型是牛津大學視覺幾何組提出的一種深度模型,在LFW資料庫上取得了97%的準確率。VGG網路由5個卷積層,兩層fc影象特徵,一層fc分類特徵組成,具體我們可以去讀它的prototxt檔案。這裡是模型與配置檔案的下載地址。
http://www.robots.ox.ac.uk/~vgg/software/vgg_face/
話題回到Caffe。在Caffe中提取圖片的特徵是很容易的,其提供了extract_feature.exe讓我們來實現,提取格式為lmdb與leveldb。關於這個的做法,可以看我的這篇部落格:
http://blog.csdn.net/mr_curry/article/details/52097529
顯然,我們在程式中肯定是希望能夠靈活利用的,使用這種方法不太可行。Caffe的Data層提供了type:MemoryData,我們可以使用它來進行Mat型別特徵的提取。
注:你需要先按照本系列第一篇部落格的方法去配置好Caffe的屬性表。
http://blog.csdn.net/mr_curry/article/details/52443126
實現
首先我們開啟VGG_FACE_deploy.prototxt,觀察VGG的網路結構。 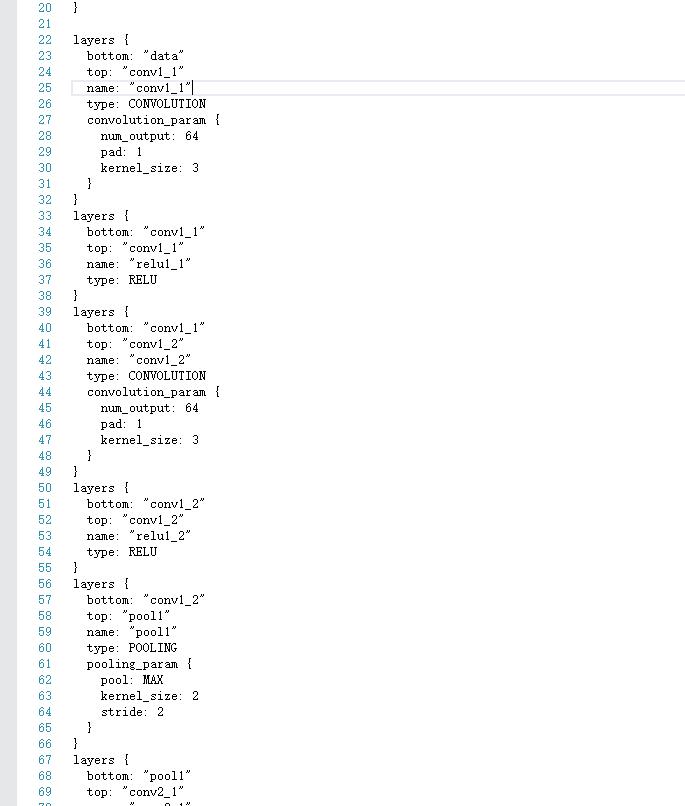
有意思的是,MemoryData層需要影象均值,但是官方網站上並沒有給出mean檔案。我們可以通過這種方式進行輸入:
- 1
- 2
- 3
我們還需要修改它的data層:(你可以用下面這部分的程式碼去替換下載下來的prototxt檔案的data層)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
為了不破壞原來的檔案,把它另存為vgg_extract_feature_memorydata.prototxt。 
好的,然後我們開始編寫。新增好這個屬性表: 
然後,新建caffe_net_memorylayer.h、ExtractFeature_.h、ExtractFeature_.cpp開始編寫。
caffe_net_memorylayer.h:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
ExtractFeature_.h
- 1
- 2
- 3
- 4
- 5
- 6
ExtractFeature_.cpp:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
=============注意上面這個地方可以這麼改:==============
(直接可以知道這個向量的首地址、尾地址,我們直接用其來定義vector)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
請特別注意這個地方:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
為什麼要加這些?因為在提取過程中發現,如果不加,會導致有一些層沒有註冊的情況。我在Github的Microsoft/Caffe上幫一外國哥們解決了這個問題。我把問題展現一下: 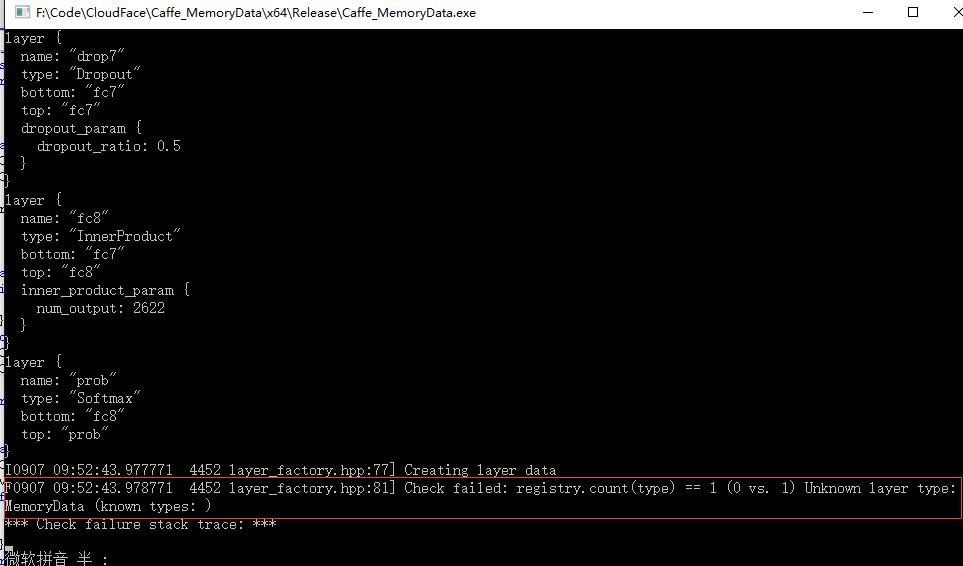
如果我們加了上述程式碼,就相當於註冊了這些層,自然就不會有這樣的問題。
在提取過程中,我提取的是fc8層的特徵,2622維。當然,最後一層都已經是分類特徵了,最好還是提取fc7層的4096維特徵。
在這個地方:
- 1
- 2
- 3
- 4
- 5
- 6
是一個初始化的函式,用於將VGG網路模型與提取特徵的配置檔案進行傳入,所以很明顯地,在提取特徵之前,需要先:
- 1
進行了這個之後,這些全域性量我們就能一直用了。
我們可以試試提取特徵的這個介面。新建一個main.cpp,呼叫之:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
因為我們得到的是一個vector< float>型別,所以我們可以把它逐一輸出出來看看。當然,在ExtractFeature()的函式中你就可以這麼做了。我們還是在main()函式裡這麼做。
來看看:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
那麼對於這張圖片,提取出的特徵,就是很多的這些數字:
提取一張224*224圖片特徵的時間為:0.019s。我們可以看到,GPU加速的效果是非常明顯的。而且我這塊顯示卡也就是GTX980。不知道泰坦X的提取速度如何(淚)。
附:net結構 (prototxt),注意layer和layers的區別:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
-
相關推薦
基於深度學習的人臉識別系統系列(Caffe+OpenCV+Dlib)——【三】使用Caffe的MemoryData層與VGG網路模型提取Mat的特徵
原文地址:http://m.blog.csdn.net/article/details?id=52456548 前言 基於深度學習的人臉識別系統,一共用到了5個開源庫:OpenCV(計算機視覺庫)、Caffe(深度學習庫)、Dlib(機器學習庫)、libfacede
【翻譯搬運】起源引擎網路同步模型(Source Multiplayer Networking)【三】
寫在前面 文章的原文很多地方都能找到 也有人做過優秀翻譯 【騰訊GAD譯館】 Source引擎多人模式網路同步模型,我只是因為自己注意力渙散覺得文章乾澀不寫下來就看不動,也請閱讀的大家不要用我的渣翻水平做橫向對比,取得必要知識資訊就好。 【2018
深度學習與人臉識別系列(3)__基於VGGNet的人臉識別系統
作者:wjmishuai 1.引言 本文中介紹的人臉識別系統是基於這兩篇論文: 第一篇論文介紹了海量資料集下的圖片檢索方法。第二篇文章將這種思想應用到人臉識別系統中,實現基於深度學習的人臉識別。 2.關於深度學習的簡要介紹 現階段為止,對
語音識別——基於深度學習的中文語音識別系統實現(程式碼詳解)
文章目錄 利用thchs30為例建立一個語音識別系統 1. 特徵提取 2. 模型搭建 搭建cnn+dnn+ctc的聲學模型 3. 訓練準備 下載資料
基於深度學習的推薦系統(二)MLP based
在第二部分,我們總結MLP基礎上的推薦系統,我在這裡只截取了原文的一部分內容。這篇部落格中所使用的註解字元和參考文獻目錄可以在基於深度學習的推薦系統(一)Overview中找到。我們把這些工作分為如下幾部分: 傳統推薦演算法的神經網路擴充套件 許多現有的推薦模型
推薦系統(Remmender System)學習筆記(二)--基於深度學習的推薦系統
關於session-based recommender system相關演算法以及論文筆記: 1.the item-to-item recommendation approach 《Item-based collaborative filtering recommendat
基於PCA的人臉識別系統(JAVA版)(一) OpenCV在JAVA上的環境配置
這裡用的JDK 1.8和OpenCV3.2.0版本。後面會重點提到OpenCV的安裝配置和OpenCV在JAVA上的配置。 1.OpenCV的安裝配置 (1)下載安裝
基於PCA的人臉識別系統(JAVA版)(三) 系統實現
系統主要由上圖幾部分組成。其中EigenFaceCore為特徵臉類,faceMain為主程式,ImageViewer為顯示圖片的工具類。如果根據第一篇博文環境都已經配置好的話則程式可以完美執行。J
深度學習-人臉識別DFACE模型pytorch訓練(二)
首先介紹一下MTCNN的網路結構,MTCNN有三種網路,訓練網路的時候需要通過三部分分別進行,每一層網路都依賴前一層網路產生訓練資
Dlib+OpenCV深度學習人臉識別
row 拷貝 too 這一 驗證 message word endif all 目錄(?)[+] DlibOpenCV深度學習人臉識別 前言 人臉數據庫導入 人臉檢測 人臉識別 異常處理 Dlib+OpenCV深度學習人臉識別 前言 人臉
基於深度學習的Person Re-ID(綜述)
轉載。 https://blog.csdn.net/linolzhang/article/details/71075756 一. 問題的提出 Person Re-ID 全稱是 Person Re-Identification,又稱為 行
基於深度學習的推薦系統綜述 (arxiv 1707.07435) 譯文 3.1 ~ 3.3
基於深度學習的推薦:最先進的技術 在本節中,我們首先介紹基於深度學習的推薦模型的類別,然後突出最先進的研究原型,旨在確定近年來最顯著和最有希望的進步。 基於深度學習的推薦模型的類別 **圖 1:**基於深度神經網路的推薦模型的類別。 為了提供該領域的全景圖,
《基於深度學習的推薦系統研究綜述》_黃立威——閱讀筆記
一、常用的深度學習模型和方法介紹 1.自編碼器 自編碼器通過一個編碼和一個解碼過程來重構輸入資料,學習資料的隱表示。基本的自編碼器可視為一個三層的神經網路結構.下圖是自編碼器結構示意圖: 自編碼器的目的是使得輸入 x 與輸出 y 儘可能接近,這種接近程度通過重構誤差表示,根據資料的
wav2letter++簡介:深度學習語音識別系統
語音識別系統是深度學習生態中發展最成熟的領域之一。當前這一代的語音識別模型基本都是基於遞迴神經網路(Recurrent Neural Network)對聲學和語言模型進行建模,以及用於知識構建的計算密集的特徵提取流水線。雖然基於RNN的技術已經在語音識別任務中得到驗證,但訓練RNN網路所需要
基於深度學習的推薦演算法實現(以MovieLens 1M資料 為例)
前言 本專案使用文字卷積神經網路,並使用MovieLens資料集完成電影推薦的任務。 推薦系統在日常的網路應用中無處不在,比如網上購物、網上買書、新聞app、社交網路、音樂網站、電影網站等等等等,有人的地方就有推薦。根據個人的喜好,相同喜好人群的習慣等資訊進行個性化
如何走近深度學習人臉識別?你需要這篇超長綜述 | 附開原始碼
相信做機器學習或深度學習的同學們回家總會有這樣一個煩惱:親朋好友詢問你從事什麼工作的時候,如何通俗地解釋能避免尷尬?我嘗試過很多名詞來形容自己的工作:機器學習,深度學習,演算法工程師/研究員,搞計算機的,程式設計師…這些詞要麼自己覺得不滿意,要麼對方聽不懂。經歷無數次失敗溝通,最後總結了一個簡單實用的答案:“
基於深度學習的Person Re-ID(特徵提取)
一. CNN特徵提取 通過上一篇文章的學習,我們已經知道,我們訓練的目的在於尋找一種特徵對映方法,使得對映後的特徵 “類內距離最小,類間距離最大”,這種特徵對映 可以看作是 空間投影,選擇一組基,得到基於這組基的特徵變換,與 PCA 有點像。 這
基於深度學習的推薦系統:綜述與新視角
原文:Deep Learning based Recommender System: A Survey and New Perspectives 作者:張帥, 新南威爾士大學 翻譯:沈春旭,清華大學 隨著線上資訊量的不斷增加,推薦系統已經成為克服這種資訊過載的有效策略。
【opencv】基於opencv2的人臉識別系統
之前,曾寫過一個較為完整的人臉識別小系統。開發環境為opencv2.4.9和VS2012,並加入了一個新模組cvui.h,用此模組為人臉識別系統寫了一個簡單介面。介面如下: 此介面用到的
現有深度學習人臉識別綜述
現有人臉檢測三類方法:1、Cascade CNN:速度最快,精度相對較低;代表演算法:MI-CNN,ICS2、Faster R-CNN:速度較慢,精度較高;代表演算法:Face R-CNN,Face R