
python爬取網易雲音樂評論
前言
上篇爬取喜馬拉雅FM音訊的最後也提到過,這回我們爬取的就是網易雲音樂的熱評+評論。本人用了挺久的網易雲,也是非常喜歡…閒話不多說,跟著我的思路來看看如何爬取網易雲的熱評+評論~
目標
本次我們爬取的目標是–網易雲音樂歌曲的熱評以及普通評論
我們知道網易雲音樂有很多的歌單,那麼我們的思路就是,從這些歌單入手,遍歷歌單,遍歷歌單中的歌曲
根據我們的經驗,我們在XHR中找到了這些動態載入的評論
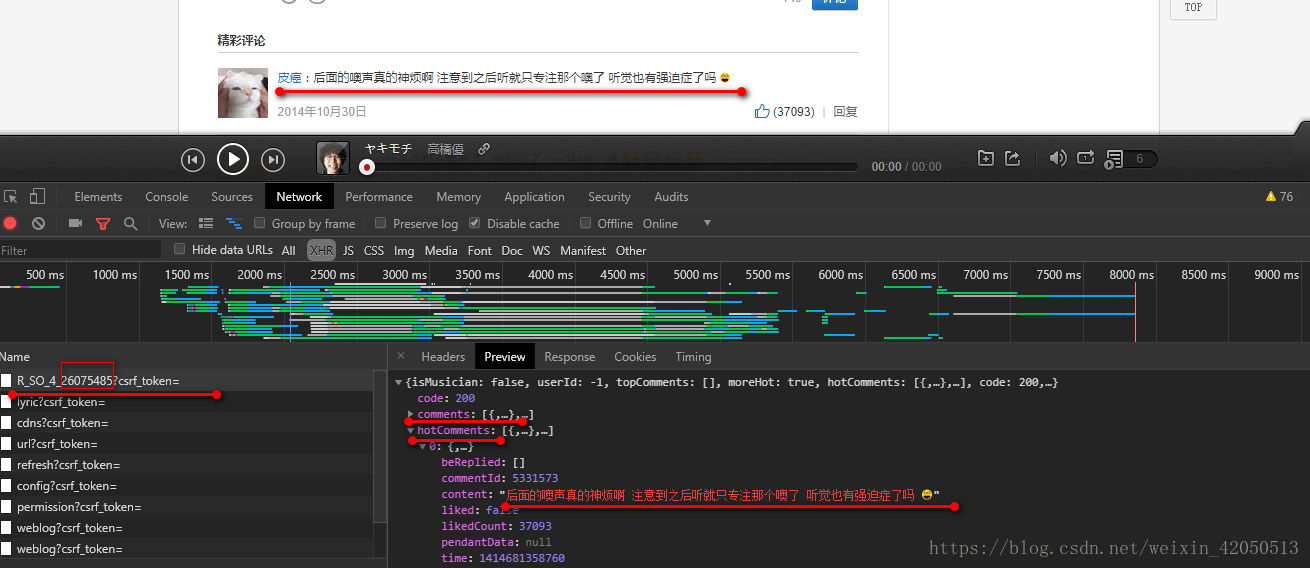
我們可以看到,在 R_SO_4_26075485?csrf_token=中,包含了comments以及hotComments,這兩個分別對應的是最新評論以及熱門評論
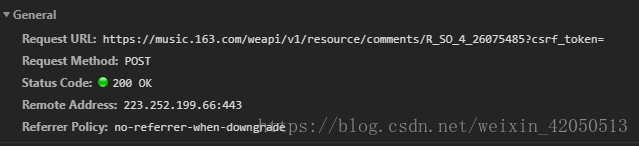

也就是說我們只要通過模擬瀏覽器向網易雲伺服器傳送post請求就能獲得評論!
這裡還要注意這個post的連結,R_SO_4_ 之後跟的一串數字實際上就是這首歌曲對應的id;而且這裡需要傳入的引數,也得好好分析一下(在後面)
所以現在目標就是:找到最新的所有歌單 -> 對每一個歌單,遍歷其中的所有歌曲,獲取網頁原始碼中的所存在歌曲的id->對每一個首歌曲通過其id,向伺服器post請求(帶上引數),得到想要的評論
開始動刀
第一步
程式碼如下:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' 這樣就可以看到

第二步
def getSongSheet(url):
#獲取每個歌單裡的每首歌的id,作為接下來post獲取的關鍵
html = getHtml(url)
result = re.findall(r'<li><a.*?href="/song\?id=(.*?)">(.*?)</a></li>',html,re.S)
result.pop()
musicList = []
for i in result:
data = {}
headers1 = {
'Referer': 'https://music.163.com/song?id={}'.format(i[0]),
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'
}
musicUrl = baseUrl+'/song?id='+i[0]
print musicUrl
#歌曲url
data['musicUrl'] = musicUrl
#歌曲名
data['title'] = i[1]
musicList.append(data)
postUrl = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_{}?csrf_token='.format(i[0])
param = {
'params': get_params(1),
'encSecKey': get_encSecKey()
}
r = requests.post(postUrl,data = param,headers = headers1)
total = r.json()
# 總評論數
total = int(total['total'])
comment_TatalPage = total/20
# 基礎總頁數
print comment_TatalPage
#判斷評論頁數,有餘數則為多一頁,整除則正好
if total%20 != 0:
comment_TatalPage = comment_TatalPage+1
comment_data,hotComment_data = getMusicComments(comment_TatalPage, postUrl, headers1)
#存入資料庫的時候若出現ID重複,那麼注意爬下來的資料是否只有一個
saveToMongoDB(str(i[1]),comment_data,hotComment_data)
print 'End!'
else:
comment_data, hotComment_data = getMusicComments(comment_TatalPage, postUrl, headers1)
saveToMongoDB(str(i[1]),comment_data,hotComment_data)
print 'End!'
time.sleep(random.randint(1, 10))
break這一步的目的就是獲取歌單裡歌曲的id,遍歷對每一個歌曲(即對應的id),獲取其歌曲的url,歌曲名;
根據id,構造postUrl 通過對第一頁的post(關於如何post得到想要的資訊,在後面會講到),獲取評論的總條數,及總頁數;
以及呼叫獲取歌曲評論的方法;
這裡還有一個判斷,根據評論總條數除以每頁20條的評論,判斷是否有餘數,可以獲得最終評論的總頁數,並且我們也可以發現,熱門評論只在第一頁
第三步
def getMusicComments(comment_TatalPage ,postUrl, headers1):
commentinfo = []
hotcommentinfo = []
# 對每一頁評論
for j in range(1, comment_TatalPage + 1):
# 熱評只在第一頁可抓取
if j == 1:
#獲取評論
r = getPostApi(j , postUrl, headers1)
comment_info = r.json()['comments']
for i in comment_info:
com_info = {}
com_info['content'] = i['content']
com_info['author'] = i['user']['nickname']
com_info['likedCount'] = i['likedCount']
commentinfo.append(com_info)
hotcomment_info = r.json()['hotComments']
for i in hotcomment_info:
hot_info = {}
hot_info['content'] = i['content']
hot_info['author'] = i['user']['nickname']
hot_info['likedCount'] = i['likedCount']
hotcommentinfo.append(hot_info)
else:
r = getPostApi(j, postUrl, headers1)
comment_info = r.json()['comments']
for i in comment_info:
com_info = {}
com_info['content'] = i['content']
com_info['author'] = i['user']['nickname']
com_info['likedCount'] = i['likedCount']
commentinfo.append(com_info)
print u'第'+str(j)+u'頁爬取完畢...'
time.sleep(random.randint(1,10))
print commentinfo
print '\n-----------------------------------------------------------\n'
print hotcommentinfo
return commentinfo,hotcommentinfo傳入三個引數,分別為comment_TatalPage ,postUrl, headers1,對應評論總頁數,postUrl就是postUrl…以及請求頭
對第一頁獲取熱評以及評論,對其他頁獲取普通評論;以及獲取其他資料,新增到列表中
第四步
下面我們就來看看令人頭疼的post部分!…
# offset的取值為:(評論頁數-1)*20,total第一頁為true,其餘頁為false
# first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}' # 第一個引數
# 第二個引數
second_param = "010001"
# 第三個引數
third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
# 第四個引數
forth_param = "0CoJUm6Qyw8W8jud"
# 獲取引數
def get_params(page): # page為傳入頁數
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
if(page == 1): # 如果為第一頁
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page-1)*20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' %(offset,'false')
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
# 獲取 encSecKey
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
# 加密過程
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
#獲取post得到的Json
def getPostApi(j ,postUrl, headers1):
param = {
# 獲取對應頁數的params
'params': get_params(j),
'encSecKey': get_encSecKey()
}
r = requests.post(postUrl, data=param, headers=headers1)
return r這裡的getPostApi函式傳入的三個引數分別為,頁數(因為每頁的post附帶的引數params不相同),postURL以及請求頭;
這裡data=param,就是需要的引數

很明顯是加密過的,這裡簡單的介紹一下
然後找到我們需要的這兩個引數

然後在fiddler中重定向core.js,修改本地core.js的內容,可以列印上面的引數,結果第一次可以在控制檯看到列印的結果,後來老是報錯…
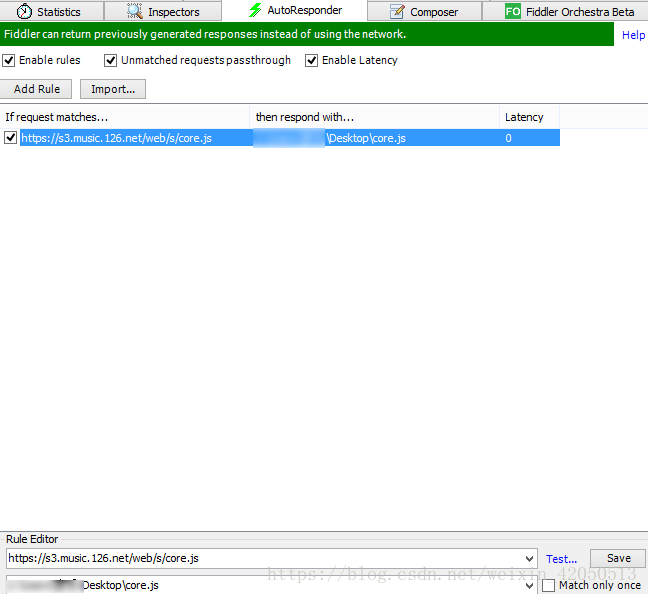
隨後就是分析JavaScript的程式碼,這裡我直接搬用了生成引數的方法…(果然還是得好好的學一下js!)
AND
別以為這樣就可以了!接著我遇到了最糟心的問題:在你匯入
from Crypto.Cipher import AES 之後報錯!
ImportError: No module named Crypto.Cipher
接著我嘗試pip install Crypto 成功後,但這回出現
ImportError: No module named Cipher!!…
最後我找了很多資料,給大家總結一下,如何解決這個問題
一般情況下,在pip install Crypto 之後只需在C:\Python27\Lib\site-packages下把crypto改成Crypto就行(但是我的沒用)
出現了報錯,隨後照著上面博文下載了Microsoft Visual C++ 9.0 後再次安裝pycrypto

可算成功了!這之後我再匯入from Crypto.Cipher import AES就可以正常運行了~
第五步
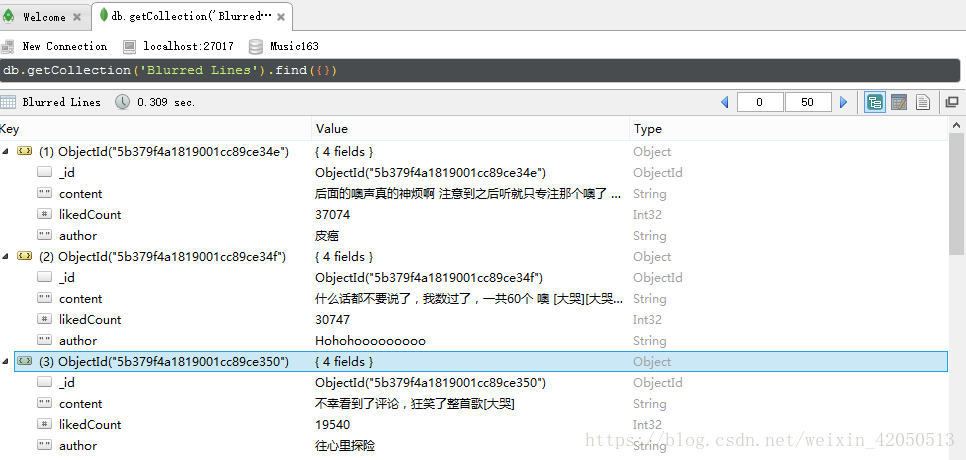
def saveToMongoDB(musicName,comment_data,hotComment_data):
client = pymongo.MongoClient(host='localhost',port=27017)
db = client['Music163']
test = db[musicName]
test.insert(hotComment_data)
test.insert(comment_data)
print musicName+u'已存入資料庫...'這最後就是將資料存入MongoDB中了,有興趣的也可以試著存入MySQL中
if __name__ == '__main__':
getUrl()這裡我是把資料爬完之後一次性存入MongoDB中,可能負擔有點大,也可以試著爬取一頁存入一頁?
有疑問或更好的方法的話,歡迎交流!
下一篇想著爬取APP的,也可能是爬取視訊…唉 快放假了…