
深度學習論文筆記(六)--- FCN-2015年(Fully Convolutional Networks for Semantic Segmentation)

深度學習論文筆記(六)--- FCN 全連線網路
FullyConvolutional Networks for Semantic Segmentation
Author:J Long , E Shelhamer, T Darrell
Year: 2015
1、 導引
通常CNN網路在卷積層之後會接上若干個全連線層, 將卷積層產生的特徵圖(feature map)對映成一個固定長度的特徵向量。以AlexNet為代表的經典CNN結構適合於影象級的分類和迴歸任務,因為它們最後都期望得到整個輸入影象的一個數值描述(概率),比如AlexNet的ImageNet模型輸出一個1000維的向量表示輸入影象屬於每一類的概率(softmax歸一化)。
而要做SemanticSegmentation(語義分割),希望能夠直接輸出一幅分割影象結果,所以就有了本篇FCN網路的提出。
2、模型解讀
①FCN將傳統CNN中的全連線層轉化成一個個的卷積層。如下圖所示,在傳統的CNN結構中,前5層是卷積層,第6層和第7層分別是一個長度為4096的一維向量,第8層是長度為1000的一維向量,分別對應1000個類別的概率。FCN將這3層表示為卷積層,卷積核的大小(寬,高,通道數)分別為(1,1,4096)、(1,1,4096)、(1,1,1000)。所有的層都是卷積層,故稱為全卷積網路。
②但是,經過多次卷積(還有pooling)以後,得到的影象越來越小,解析度越來越低。為了從這個解析度低的粗略影象恢復到原圖的解析度,FCN使用了增取樣操作。這個增取樣是通過反捲積來實現的(deconvolution),文中用的反捲積操作很簡單,後來有其他人就在反捲積這一步上做了進一步優化,使得分割結果更為準確。
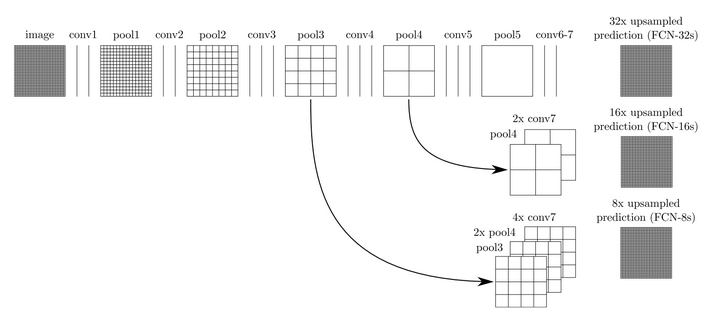
我們來把位置稍微調整一下利於理解:
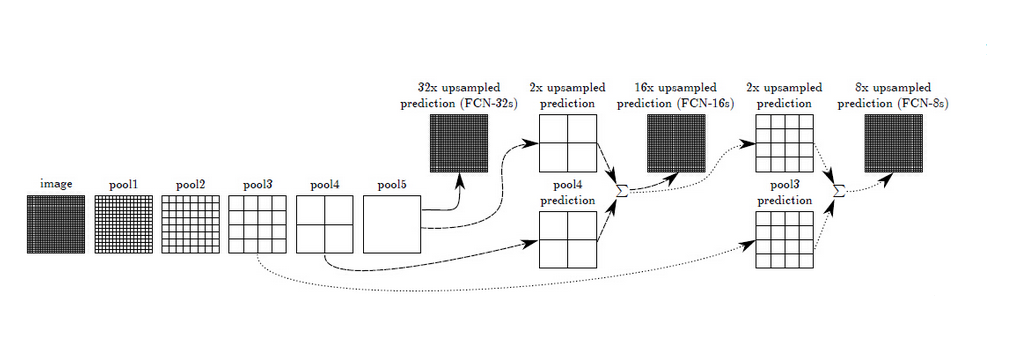
在淺層處減小upsampling的步長,得到的finelayer 和 高層得到的coarselayer做融合,然後再upsampling得到輸出。這種做法兼顧local和global資訊,即文中說的combiningwhat and where,取得了不錯的效果提升。FCN-32s為59.4,FCN-16s提升到了62.4,FCN-8s提升到62.7。可以看出效果還是很明顯的。
3、 創新點分析
①由於沒有全連線層的存在,所以輸入影象的尺寸要求並不固定了。這個原因是因為全連線層是一個矩陣乘法的操作,可以自己去想一想。
②實現的是對每個畫素點的分類預測:
Pixel-wiseprediction
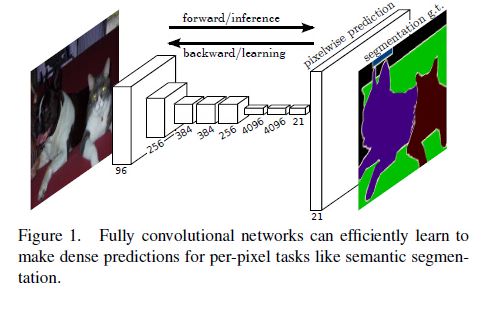
之所以能做到這樣,是因為卷積層的輸出的結果是datamap,而不是一個向量!經過反捲積後得到與原圖一樣大小的1000層heatmap,每一層代表一個類,然後觀察每個位置的畫素,在哪一層它這個點對應的值最大,就認為這個畫素點屬於這一層的類,
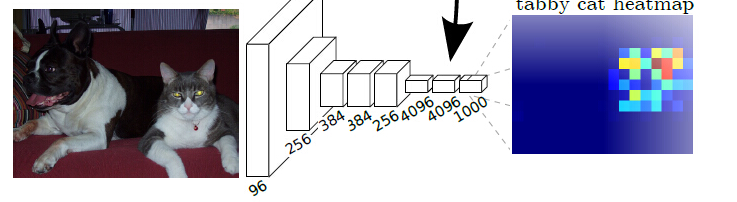
就比如圖中點貓那個位置的點,在tabby cat這個類的heatmap上表現的值很高,所以認為那一坨畫素點是屬於tabby cat這個類的。
從而這樣對每個畫素點進行分類,最後輸出的就是分割好的影象。