
系統學習深度學習(二) --自編碼器,DA演算法,SDA,稀疏自編碼器
轉自:http://www.cnblogs.com/neopenx/p/4370350.html,作者寫的很好,輕鬆易懂。
起源:PCA、特徵提取....
隨著一些奇怪的高維資料出現,比如影象、語音,傳統的統計學-機器學習方法遇到了前所未有的挑戰。
資料維度過高,資料單調,噪聲分佈廣,傳統方法的“數值遊戲”很難奏效。資料探勘?已然挖不出有用的東西。
為了解決高維度的問題,出現的線性學習的PCA降維方法,PCA的數學理論確實無懈可擊,但是卻只對線性資料效果比較好。
於是,尋求簡單的、自動的、智慧的特徵提取方法仍然是機器學習的研究重點。比如LeCun在1998年CNN總結性論文中就概括了今後機器學習模型的基本架構。
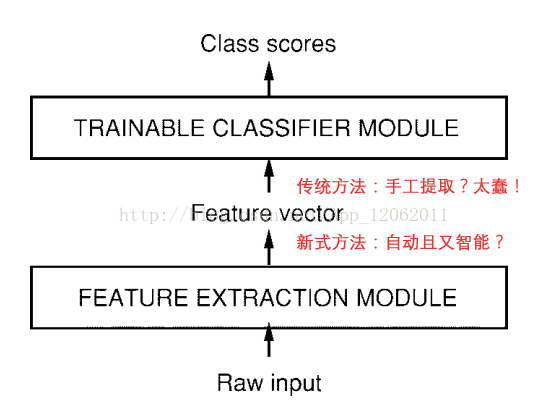
當然CNN另闢蹊徑,利用卷積、降取樣兩大手段從訊號資料的特點上很好的提取出了特徵。對於一般非訊號資料,該怎麼辦呢??
Part I 自動編碼器(AutoEncoder)
自動編碼器基於這樣一個事實:原始input(設為x)經過加權(W、b)、對映(Sigmoid)之後得到y,再對y反向加權映射回來成為z。
通過反覆迭代訓練兩組(W、b),使得誤差函式最小,即儘可能保證z近似於x,即完美重構了x。
那麼可以說正向第一組權(W、b)是成功的,很好的學習了input中的關鍵特徵,不然也不會重構得如此完美。結構圖如下:
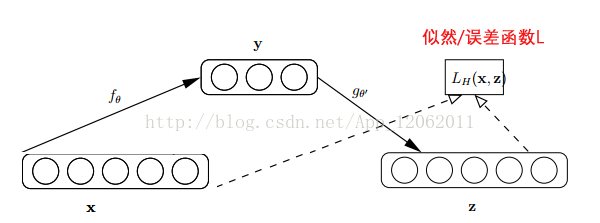
從生物的大腦角度考慮,可以這麼理解,學習和重構就好像編碼和解碼一樣。

這個過程很有趣,首先,它沒有使用資料標籤來計算誤差update引數,所以是無監督學習。
其次,利用類似神經網路的雙隱層的方式,簡單粗暴地提取了樣本的特徵。
這個雙隱層是有爭議的,最初的編碼器確實使用了兩組(W,b),但是Vincent在2010年的論文中做了研究,發現只要單組W就可以了。
即W'=WT, W和W’稱為Tied Weights。實驗證明,W'真的只是在打醬油,完全沒有必要去做訓練。
逆向重構矩陣讓人想起了逆矩陣,若W-1=WT的話,W就是個正交矩陣了,即W是可以訓成近似正交陣的。
由於W'就是個醬油,訓練完之後就沒它事了。正向傳播用W即可,相當於為input預先編個碼,再匯入到下一layer去。所以叫自動編碼器,而不叫自動編碼解碼器。
我當時看到這個過程和概念,也糾結明明是編解碼器,為什麼又叫編碼器。
Part II 降噪自動編碼器(Denoising Autoencoder)
Vincent在2008年的論文中提出了AutoEncoder的改良版——dA。推薦首先去看這篇paper。
論文的標題叫 "Extracting and Composing Robust Features",譯成中文就是"提取、編碼出具有魯棒性的特徵"
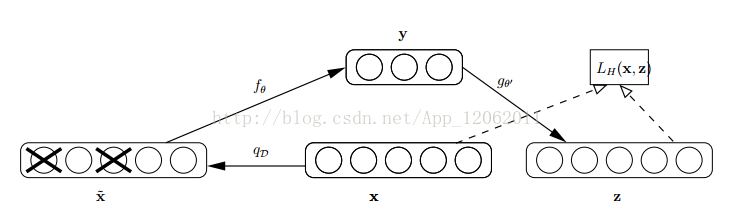
怎麼才能使特徵很魯棒呢?就是以一定概率分佈(通常使用二項分佈)去擦除原始input矩陣,即每個值都隨機置0, 這樣看起來部分資料的部分特徵是丟失了。
以這丟失特徵的資料x'去計算y,計算z,並將z與原始x做誤差迭代,這樣,網路就學習了這個破損(原文叫Corruputed)的資料。
這個破損的資料是很有用的,原因有二:
其之一,通過與非破損資料訓練的對比,破損資料訓練出來的Weight噪聲比較小。降噪因此得名。
原因不難理解,因為擦除的時候不小心把輸入噪聲給×掉了。

其之二,破損資料一定程度上減輕了訓練資料與測試資料的代溝。由於資料的部分被×掉了,因而這破損資料
一定程度上比較接近測試資料。(訓練、測試肯定有同有異,當然我們要求同舍異)。
這樣訓練出來的Weight的魯棒性就提高了。圖示如下:

關鍵是,這樣胡亂擦除原始input真的很科學?真的沒問題? Vincent又從大腦認知角度給瞭解釋:
paper中這麼說到:人類具有認知被阻擋的破損影象能力,此源於我們高等的聯想記憶感受機能。
我們能以多種形式去記憶(比如影象、聲音,甚至如上圖的詞根記憶法),所以即便是資料破損丟失,我們也能回想起來。
另外,就是從特徵提取的流形學習(Manifold Learning)角度看:
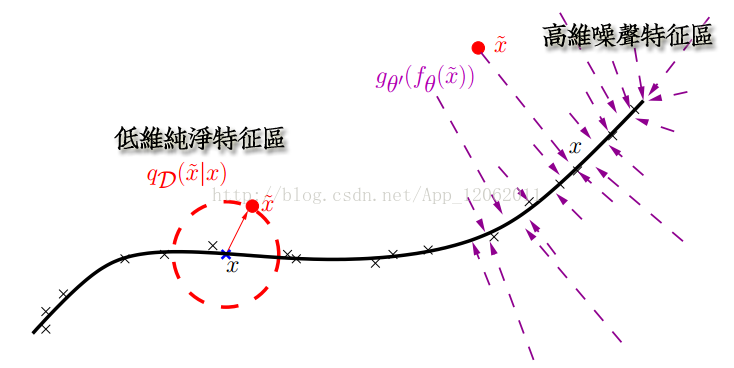
破損的資料相當於一個簡化的PCA,把特徵做一個簡單的降維預提取。
Part III 自動編碼器的奇怪用法
自動編碼器相當於建立了一個隱層,一個簡單想法就是加在深度網路的開頭,作為原始訊號的初級filter,起到降維、提取特徵的效果。
當然Bengio在2007年論文中仿照DBN較之於RBM做法:作為深度網路中各個layer的引數初始化值,而不是用隨機小值。
當然,這種做法就有一個問題,AutoEncoder可以看作是PCA的非線性補丁加強版,PCA的取得的效果是建立在降維基礎上的。
仔細想想CNN這種結構,隨著layer的推進,每層的神經元個數在遞增,如果用了AutoEncoder去預訓練,豈不是增維了?真的沒問題?
paper中給出的實驗結果認為AutoEncoder的增維效果還不賴,原因可能是非線性網路能力很強,儘管神經元個數增多,但是每個神經元的效果在衰減。
同時,隨機梯度演算法給了後續監督學習一個良好的開端。整體上,增維是利大於弊的。
Part IV 程式碼與實現
有幾個注意點說下:
①cost函式可以使用交錯熵(Cross Entroy)設計,對於定義域在[0,1]這類的資料,交錯熵可用來設計cost函式。
也可以使用最小二乘法設計。
②RandomStreams函式存在多個,因為要與非Tensor量相乘,必須用shared版本。
所以是 fromtheano.tensor.shared_randomstreamsimportRandomStreams
而不是 from theano.tensor import RandomStreams
轉自:http://blog.csdn.net/zouxy09/article/details/8775524
下面是另一篇部落格,我做了一點刪減。
AutoEncoder自動編碼器
Deep Learning最簡單的一種方法是利用人工神經網路的特點,人工神經網路(ANN)本身就是具有層次結構的系統,如果給定一個神經網路,我們假設其輸出與輸入是相同的,然後訓練調整其引數,得到每一層中的權重。自然地,我們就得到了輸入I的幾種不同表示(每一層代表一種表示),這些表示就是特徵。自動編碼器就是一種儘可能復現輸入訊號的神經網路。為了實現這種復現,自動編碼器就必須捕捉可以代表輸入資料的最重要的因素,就像PCA那樣,找到可以代表原資訊的主要成分。
具體過程簡單的說明如下:
給定無標籤資料,用非監督學習學習特徵:

在我們之前的神經網路中,如第一個圖,我們輸入的樣本是有標籤的,即(input, target),這樣我們根據當前輸出和target(label)之間的差去改變前面各層的引數,直到收斂。但現在我們只有無標籤資料,也就是右邊的圖。那麼這個誤差怎麼得到呢?

如上圖,我們將input輸入一個encoder編碼器,就會得到一個code,這個code也就是輸入的一個表示,那麼我們怎麼知道這個code表示的就是input呢?我們加一個decoder解碼器,這時候decoder就會輸出一個資訊,那麼如果輸出的這個資訊和一開始的輸入訊號input是很像的(理想情況下就是一樣的),那很明顯,我們就有理由相信這個code是靠譜的。所以,我們就通過調整encoder和decoder的引數,使得重構誤差最小,這時候我們就得到了輸入input訊號的第一個表示了,也就是編碼code了。因為是無標籤資料,所以誤差的來源就是直接重構後與原輸入相比得到。

Denoising AutoEncoders降噪自動編碼器:
降噪自動編碼器DA是在自動編碼器的基礎上,訓練資料加入噪聲,所以自動編碼器必須學習去去除這種噪聲而獲得真正的沒有被噪聲汙染過的輸入。因此,這就迫使編碼器去學習輸入訊號的更加魯棒的表達,這也是它的泛化能力比一般編碼器強的原因。DA可以通過梯度下降演算法去訓練。

通過編碼器產生特徵,然後訓練下一層。這樣逐層訓練(這裡說的是SDA):
那上面我們就得到第一層的code,我們的重構誤差最小讓我們相信這個code就是原輸入訊號的良好表達了,或者牽強點說,它和原訊號是一模一樣的(表達不一樣,反映的是一個東西)。那第二層和第一層的訓練方式就沒有差別了,我們將第一層輸出的code當成第二層的輸入訊號,同樣最小化重構誤差,就會得到第二層的引數,並且得到第二層輸入的code,也就是原輸入資訊的第二個表達了。其他層就同樣的方法炮製就行了(訓練這一層,前面層的引數都是固定的,並且他們的decoder已經沒用了,都不需要了)。

有監督微調:
經過上面的方法,我們就可以得到很多層了。至於需要多少層(或者深度需要多少,這個目前本身就沒有一個科學的評價方法)需要自己試驗調了。每一層都會得到原始輸入的不同的表達。當然了,我們覺得它是越抽象越好了,就像人的視覺系統一樣。
到這裡,這個AutoEncoder還不能用來分類資料,因為它還沒有學習如何去連結一個輸入和一個類。它只是學會了如何去重構或者復現它的輸入而已。或者說,它只是學習獲得了一個可以良好代表輸入的特徵,這個特徵可以最大程度上代表原輸入訊號。那麼,為了實現分類,我們就可以在AutoEncoder的最頂的編碼層新增一個分類器(例如羅傑斯特迴歸、SVM等),然後通過標準的多層神經網路的監督訓練方法(梯度下降法)去訓練。
也就是說,這時候,我們需要將最後層的特徵code輸入到最後的分類器,通過有標籤樣本,通過監督學習進行微調,這也分兩種,一個是隻調整分類器(黑色部分):

另一種:通過有標籤樣本,微調整個系統:(如果有足夠多的資料,這個是最好的。end-to-end learning端對端學習)

一旦監督訓練完成,這個網路就可以用來分類了。神經網路的最頂層可以作為一個線性分類器,然後我們可以用一個更好效能的分類器去取代它。
在研究中可以發現,如果在原有的特徵中加入這些自動學習得到的特徵可以大大提高精確度,甚至在分類問題中比目前最好的分類演算法效果還要好!
AutoEncoder存在一些變體,這裡簡要介紹下兩個:
Sparse AutoEncoder稀疏自動編碼器:
當然,我們還可以繼續加上一些約束條件得到新的Deep Learning方法,如:如果在AutoEncoder的基礎上加上L1的正則限制(L1主要是約束每一層中的節點中大部分都要為0,只有少數不為0,這就是Sparse名字的來源),我們就可以得到Sparse AutoEncoder法。

如上圖,其實就是限制每次得到的表達code儘量稀疏。因為稀疏的表達往往比其他的表達要有效(人腦好像也是這樣的,某個輸入只是刺激某些神經元,其他的大部分的神經元是受到抑制的)。
Sparse Coding稀疏編碼
如果我們把輸出必須和輸入相等的限制放鬆,同時利用線性代數中基的概念,即O = a1*Φ1 + a2*Φ2+….+ an*Φn, Φi是基,ai是係數,我們可以得到這樣一個優化問題:
Min |I – O|,其中I表示輸入,O表示輸出。
通過求解這個最優化式子,我們可以求得係數ai和基Φi,這些係數和基就是輸入的另外一種近似表達。

因此,它們可以用來表達輸入I,這個過程也是自動學習得到的。如果我們在上述式子上加上L1的Regularity限制,得到:
Min |I – O| + u*(|a1| + |a2| + … + |an |)
這種方法被稱為Sparse Coding。通俗的說,就是將一個訊號表示為一組基的線性組合,而且要求只需要較少的幾個基就可以將訊號表示出來。“稀疏性”定義為:只有很少的幾個非零元素或只有很少的幾個遠大於零的元素。要求係數 ai 是稀疏的意思就是說:對於一組輸入向量,我們只想有儘可能少的幾個係數遠大於零。選擇使用具有稀疏性的分量來表示我們的輸入資料是有原因的,因為絕大多數的感官資料,比如自然影象,可以被表示成少量基本元素的疊加,在影象中這些基本元素可以是面或者線。同時,比如與初級視覺皮層的類比過程也因此得到了提升(人腦有大量的神經元,但對於某些影象或者邊緣只有很少的神經元興奮,其他都處於抑制狀態)。
稀疏編碼演算法是一種無監督學習方法,它用來尋找一組“超完備”基向量來更高效地表示樣本資料。雖然形如主成分分析技術(PCA)能使我們方便地找到一組“完備”基向量,但是這裡我們想要做的是找到一組“超完備”基向量來表示輸入向量(也就是說,基向量的個數比輸入向量的維數要大)。超完備基的好處是它們能更有效地找出隱含在輸入資料內部的結構與模式。然而,對於超完備基來說,係數ai不再由輸入向量唯一確定。因此,在稀疏編碼演算法中,我們另加了一個評判標準“稀疏性”來解決因超完備而導致的退化(degeneracy)問題。(詳細過程請參考:UFLDL Tutorial稀疏編碼)

比如在影象的Feature Extraction的最底層要做Edge Detector的生成,那麼這裡的工作就是從Natural Images中randomly選取一些小patch,通過這些patch生成能夠描述他們的“基”,也就是右邊的8*8=64個basis組成的basis,然後給定一個test patch, 我們可以按照上面的式子通過basis的線性組合得到,而sparse matrix就是a,下圖中的a中有64個維度,其中非零項只有3個,故稱“sparse”。
這裡可能大家會有疑問,為什麼把底層作為Edge Detector呢?上層又是什麼呢?這裡做個簡單解釋大家就會明白,之所以是Edge Detector是因為不同方向的Edge就能夠描述出整幅影象,所以不同方向的Edge自然就是影象的basis了……而上一層的basis組合的結果,上上層又是上一層的組合basis……(就是上面第四部分的時候咱們說的那樣)
Sparse coding分為兩個部分:
1)Training階段:給定一系列的樣本圖片[x1, x 2, …],我們需要學習得到一組基[Φ1, Φ2, …],也就是字典。
稀疏編碼是k-means演算法的變體,其訓練過程也差不多(EM演算法的思想:如果要優化的目標函式包含兩個變數,如L(W, B),那麼我們可以先固定W,調整B使得L最小,然後再固定B,調整W使L最小,這樣迭代交替,不斷將L推向最小值。EM演算法可以見我的部落格:“從最大似然到EM演算法淺解”)。
訓練過程就是一個重複迭代的過程,按上面所說,我們交替的更改a和Φ使得下面這個目標函式最小。

每次迭代分兩步:
a)固定字典Φ[k],然後調整a[k],使得上式,即目標函式最小(即解LASSO問題)。
b)然後固定住a [k],調整Φ [k],使得上式,即目標函式最小(即解凸QP問題)。
不斷迭代,直至收斂。這樣就可以得到一組可以良好表示這一系列x的基,也就是字典。
2)Coding階段:給定一個新的圖片x,由上面得到的字典,通過解一個LASSO問題得到稀疏向量a。這個稀疏向量就是這個輸入向量x的一個稀疏表達了。

例如:
