
論文筆記(1)DenseBox: Unifying Landmark Localization with End to End Object Detection
本文的貢獻有一下幾點:
1,實現了end-to-end的學習,同時完成了對bounding box和物體類別的預測;
2,在多工學習中融入定位資訊,提高了檢測的準確率。
我們先來看看他和其他幾篇代表性文章之間的不同。
在OverFeat[1]中提出了將分類和定位問題一起解決的思想,但這兩個任務在訓練階段是分開進行的,並且需要複雜的後續處理來得到檢測結果,而在本文中多工的學習是end-to-end;
DDFD[2]是一個基於CNN的人臉檢測系統,它比R-CNN的效能更好的原因在於R-CNN在proposal的產生過程中會遺失一些臉部資訊。但DDFD的類別預測和bounding box定位也是分為兩個階段進行的;
Faster R-CNN[3]通過RPN完成proposal的生成,RPN需要預先定義好的anchors,而且RPN是在多尺度物體上進行訓練的。
MultiBox[4]運用CNN來生成proposal而不是selective search,它生成的bounding box不具有不變性,而本文生成的bounding box和RPN一樣,具有轉換不變性;
YOLO[5]和DenseBox一樣也可完成end-to-end的學習,但兩者的輸出層設計不一樣。YOLO針對每個影象輸出49個bounding box,DenseBox則通過上取樣層來保證解析度相對較高的輸出,同時運用了下采樣。。這使得我們的網路在處理小物體和高度重合的物體上有很大的優勢。
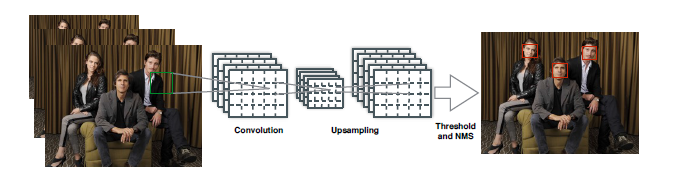
從上圖可以看到,只需要單獨的卷積網路就可以同時輸出多個預測到的bounding box和分類結果,除了nms之外,檢測系統的所有組成部分都構建在FCN之中。
在影象預處理階段,在保證人臉和足夠的背景資訊下對圖片進行了剪下。

在訓練過程中,將原始圖片剪下到240*240大小,保證處於中心的臉部高度為50p,輸出的ground truth是一個5通道的大小為60*60的特徵圖。
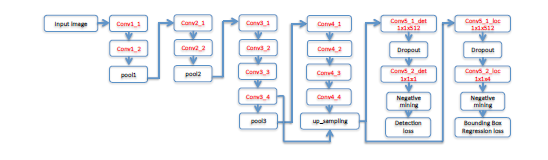
上圖是本文的網路結構圖。紅色部分表示存在學習引數。前12個conv層的網路引數由VGG19模型引數直接初始化,conv4_4的輸出作為後續四個1*1卷積層的輸入,前兩個輸出的是通道1的特徵圖,用於分類預測,後兩個利用通道4的特徵圖來預測bounding box的相對位置。這種有兩個輸出分支的結構和Fast R-CNN很相似,在第一個輸出埠定義分類損失函式,在第二個定義bounding-box迴歸損失函式,這樣就可定義完整的損失函式。
文中還談及了取樣均衡問題,並對輸出畫素進行二進位制標記來決定其是否被選來用於訓練。
首先是直接忽略正負區域的邊界,並將其loss weight設為0,其次是傾向選擇預測發生嚴重錯誤的樣本,這一過程通過negative mining實現,基於這些樣本的梯度學習使得學習更加的魯棒。
參考文獻:
[1] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y.LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv preprint arXiv:1312.6229, 2013.
[2] S. S. Farfade, M. Saberian, and L.-J. Li. Multi-view face detection using deep convolutional neural networks. arXiv preprint arXiv:1502.02766, 2015.
[3] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv preprint arXiv:1506.01497, 2015.
[4] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalable object detection using deep neural networks. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on,pages 2155–2162. IEEE, 2014.
[5] J. Redmon, S. K. Divvala, R. B. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. arXiv preprint, abs/1506.02640, 2015.