
Net和Java基於zipkin的全鏈路追蹤
在各大廠分散式鏈路跟蹤系統架構對比 中已經介紹了幾大框架的對比,如果想用免費的可以用zipkin和pinpoint還有一個忘了介紹:SkyWalking,具體介紹可參考:https://github.com/apache/incubator-skywalking/blob/master/README_ZH.md
由於追蹤的要求是Net平臺和Java平臺都要支援,對於java平臺各元件都是天生的支援的,但對於net的支援找了些開源元件,發現Pinpoint和SkyWalking給出的Demo都是基於NetCore(SkyWalking可以在github上搜skywalking-netcore,Pinpoint沒有好的推薦),版本要求比較高,但不可能更改現有平臺的FW框架,Zipkin有開源專案 Medidata.zipkinTracerModule 、zipkin.net、zipkin-csharp,網上依次推薦是從前到後,經過測試發現Medidata.zipkinTracerModule、zipkin.net也是用於Net Core的,在NuGet上安裝報錯。最後測試zipkin-csharp(https://github.com/openzipkin-attic/zipkin-csharp)可以成功,在NuGet中搜索Zipkin.Core,現在版本也只有一個,如下:

然後檢視給出的demo中程式碼:zipkin-csharp/examples/ZipkinExample/Program.cs
using System; using System.Net; using System.Threading; using Zipkin; using Zipkin.Tracer.Kafka; namespace ZipkinExample { class Program { static void Main(string[] args) { var random = new Random();// make sure Zipkin with Scribe client is working //var collector = new HttpCollector(new Uri("http://localhost:9411/")); var collector = new KafkaCollector(KafkaSettings.Default); var traceId = new TraceHeader(traceId: (ulong)random.Next(), spanId: (ulong)random.Next());var span = new Span(traceId, new IPEndPoint(IPAddress.Loopback, 9000), "test-service"); span.Record(Annotations.ClientSend(DateTime.UtcNow)); Thread.Sleep(100); span.Record(Annotations.ServerReceive(DateTime.UtcNow)); Thread.Sleep(100); span.Record(Annotations.ServerSend(DateTime.UtcNow)); Thread.Sleep(100); span.Record(Annotations.ClientReceive(DateTime.UtcNow)); collector.CollectAsync(span).Wait(); } } }
可以看出這裡的traceId和spanId都是隨機生成的,在這裡推薦自己生成ID,注意是ulong型,這裡毫秒數只格式化兩位(資料庫的位數20位,會超),也可以用更保險的其它方法。
/// <summary> /// 獲得隨機數 /// </summary> /// <returns></returns> private static ulong getRandom() { var random = new Random(); return ulong.Parse(DateTime.Now.ToString("yyyyMMddHHmmssff") + random.Next(100, 999)); } }
collector這裡使用Http來接收,註釋kafka的,放開http的。去掉 collector.CollectAsync(span).Wait(); 中的Wait。
Zipkin的幾個基本概念
Span:基本工作單元,一次鏈路呼叫(可以是RPC,DB等沒有特定的限制)建立一個span,通過一個64位ID標識它, span通過還有其他的資料,例如描述資訊,時間戳,key-value對的(Annotation)tag資訊,parent-id等,其中parent-id 可以表示span呼叫鏈路來源,通俗的理解span就是一次請求資訊
Trace:類似於樹結構的Span集合,表示一條呼叫鏈路,存在唯一標識,即TraceId
Annotation:註解,用來記錄請求特定事件相關資訊(例如時間),通常包含四個註解資訊
cs - Client Start,表示客戶端發起請求
sr - Server Receive,表示服務端收到請求
ss - Server Send,表示服務端完成處理,並將結果傳送給客戶端
cr - Client Received,表示客戶端獲取到服務端返回資訊
BinaryAnnotation:提供一些額外資訊,一般以key-value對出現
啟動服務端測試
下載 https://github.com/openzipkin/zipkin/releases 最近的穩定版 release-2.7.1的jar包,這裡採用mysql的型式儲存記錄,因此需要建立資料庫zipkin,建立表:
SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for `zipkin_annotations` -- ---------------------------- DROP TABLE IF EXISTS `zipkin_annotations`; CREATE TABLE `zipkin_annotations` ( `trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.trace_id', `span_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.id', `a_key` varchar(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1', `a_value` blob COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB', `a_type` int(11) NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation', `a_timestamp` bigint(20) DEFAULT NULL COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp', `endpoint_ipv4` int(11) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_ipv6` binary(16) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address', `endpoint_port` smallint(6) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_service_name` varchar(255) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null', UNIQUE KEY `trace_id_high` (`trace_id_high`,`trace_id`,`span_id`,`a_key`,`a_timestamp`) COMMENT 'Ignore insert on duplicate', UNIQUE KEY `trace_id_high_4` (`trace_id_high`,`trace_id`,`span_id`,`a_key`,`a_timestamp`) COMMENT 'Ignore insert on duplicate', KEY `trace_id_high_2` (`trace_id_high`,`trace_id`,`span_id`) COMMENT 'for joining with zipkin_spans', KEY `trace_id_high_3` (`trace_id_high`,`trace_id`) COMMENT 'for getTraces/ByIds', KEY `endpoint_service_name` (`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames', KEY `a_type` (`a_type`) COMMENT 'for getTraces', KEY `a_key` (`a_key`) COMMENT 'for getTraces', KEY `trace_id` (`trace_id`,`span_id`,`a_key`) COMMENT 'for dependencies job', KEY `trace_id_high_5` (`trace_id_high`,`trace_id`,`span_id`) COMMENT 'for joining with zipkin_spans', KEY `trace_id_high_6` (`trace_id_high`,`trace_id`) COMMENT 'for getTraces/ByIds', KEY `endpoint_service_name_2` (`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames', KEY `a_type_2` (`a_type`) COMMENT 'for getTraces', KEY `a_key_2` (`a_key`) COMMENT 'for getTraces', KEY `trace_id_2` (`trace_id`,`span_id`,`a_key`) COMMENT 'for dependencies job' ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED; -- ---------------------------- -- Records of zipkin_annotations -- ---------------------------- -- ---------------------------- -- Table structure for `zipkin_dependencies` -- ---------------------------- DROP TABLE IF EXISTS `zipkin_dependencies`; CREATE TABLE `zipkin_dependencies` ( `day` date NOT NULL, `parent` varchar(255) NOT NULL, `child` varchar(255) NOT NULL, `call_count` bigint(20) DEFAULT NULL, `error_count` bigint(20) DEFAULT NULL, UNIQUE KEY `day` (`day`,`parent`,`child`), UNIQUE KEY `day_2` (`day`,`parent`,`child`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED; -- ---------------------------- -- Records of zipkin_dependencies -- ---------------------------- -- ---------------------------- -- Table structure for `zipkin_spans` -- ---------------------------- DROP TABLE IF EXISTS `zipkin_spans`; CREATE TABLE `zipkin_spans` ( `trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` bigint(20) NOT NULL, `id` bigint(20) NOT NULL, `name` varchar(255) NOT NULL, `parent_id` bigint(20) DEFAULT NULL, `debug` bit(1) DEFAULT NULL, `start_ts` bigint(20) DEFAULT NULL COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL', `duration` bigint(20) DEFAULT NULL COMMENT 'Span.duration(): micros used for minDuration and maxDuration query', UNIQUE KEY `trace_id_high` (`trace_id_high`,`trace_id`,`id`) COMMENT 'ignore insert on duplicate', UNIQUE KEY `trace_id_high_4` (`trace_id_high`,`trace_id`,`id`) COMMENT 'ignore insert on duplicate', KEY `trace_id_high_2` (`trace_id_high`,`trace_id`,`id`) COMMENT 'for joining with zipkin_annotations', KEY `trace_id_high_3` (`trace_id_high`,`trace_id`) COMMENT 'for getTracesByIds', KEY `name` (`name`) COMMENT 'for getTraces and getSpanNames', KEY `start_ts` (`start_ts`) COMMENT 'for getTraces ordering and range', KEY `trace_id_high_5` (`trace_id_high`,`trace_id`,`id`) COMMENT 'for joining with zipkin_annotations', KEY `trace_id_high_6` (`trace_id_high`,`trace_id`) COMMENT 'for getTracesByIds', KEY `name_2` (`name`) COMMENT 'for getTraces and getSpanNames', KEY `start_ts_2` (`start_ts`) COMMENT 'for getTraces ordering and range' ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED; -- ---------------------------- -- Records of zipkin_spans -- ----------------------------
啟動
進入程式的當前目錄啟動,注意引數內容,如果想要儲存到elasticsearch,需要按官方文件更改。
java -jar zipkin-server-2.7.1.jar --STORAGE_TYPE=mysql --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=123456 --MYSQL_HOST=localhost --MYSQL_TCP_PORT=3306
啟動後看到如下內容表明成功。
啟動成功後瀏覽器訪問 http://localhost:9411/
至此服務端和展示頁面已經啟動,不過功能還是很簡單的,具體的使用可另行查詢資料。
這裡用來測試的服務採用網友提供的 原始碼:mircoservice分散式跟蹤系統(zipkin+springboot) https://github.com/dreamerkr/mircoservice,文章可參考:微服務之分散式跟蹤系統(springboot+zipkin)https://blog.csdn.net/qq_21387171/article/details/53787019
用預設配置分別執行4個客戶端服務後執行效果:
(2)輸入zipkin地址,每次trace的列表
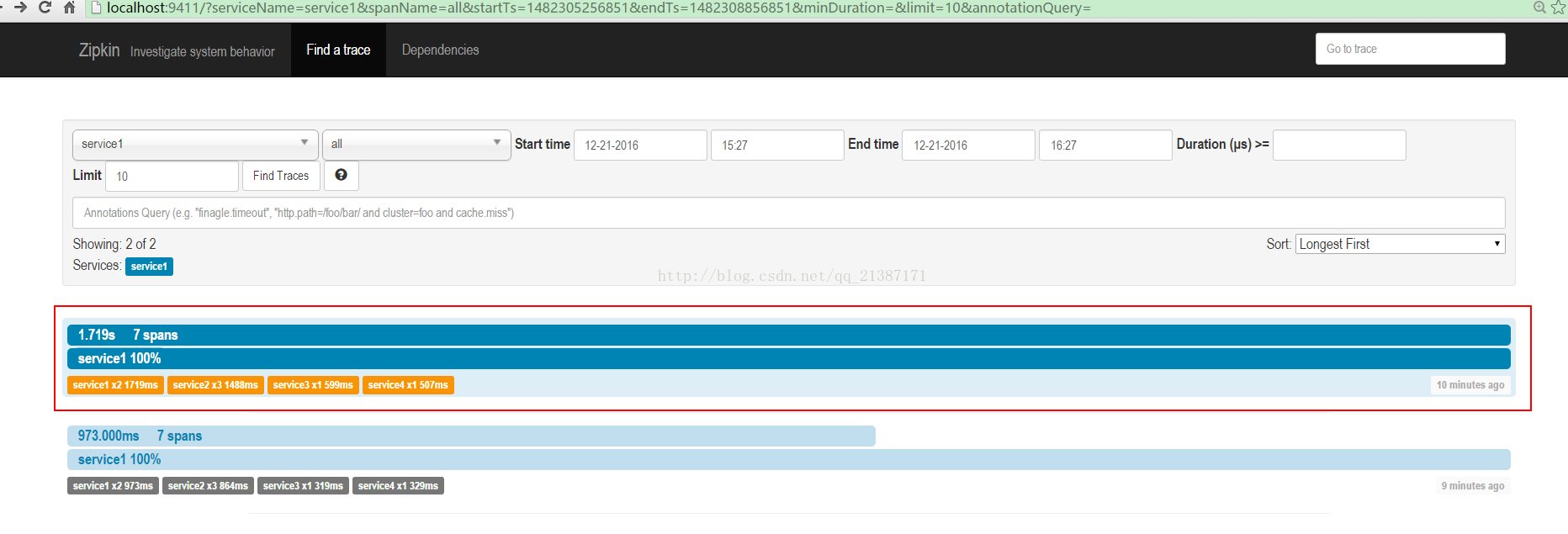
點選其中的trace,可以看trace的樹形結構,包括每個服務所消耗的時間:
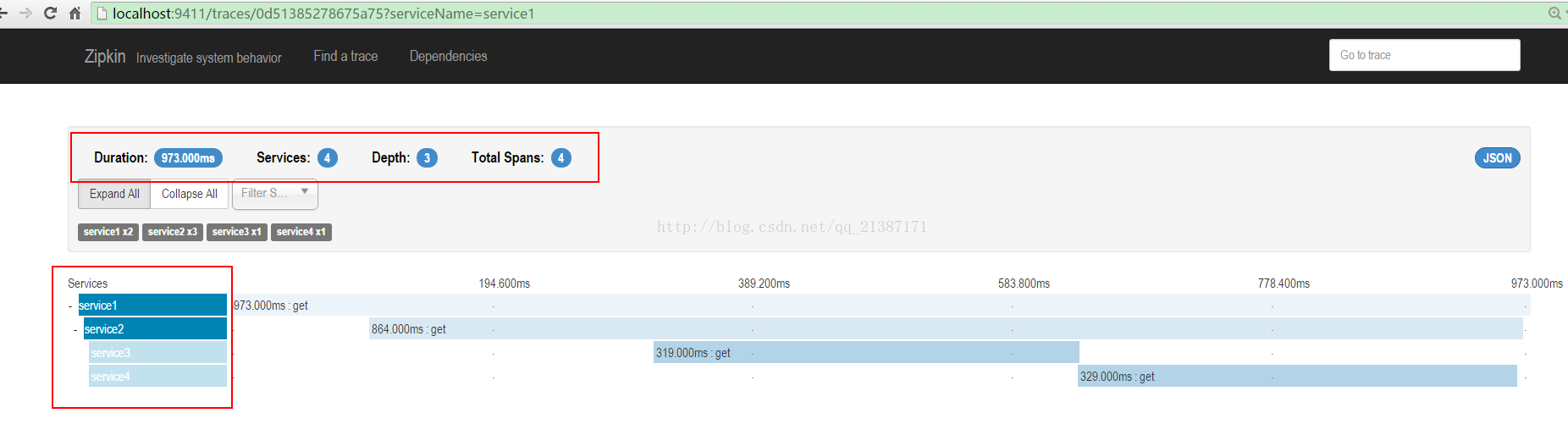
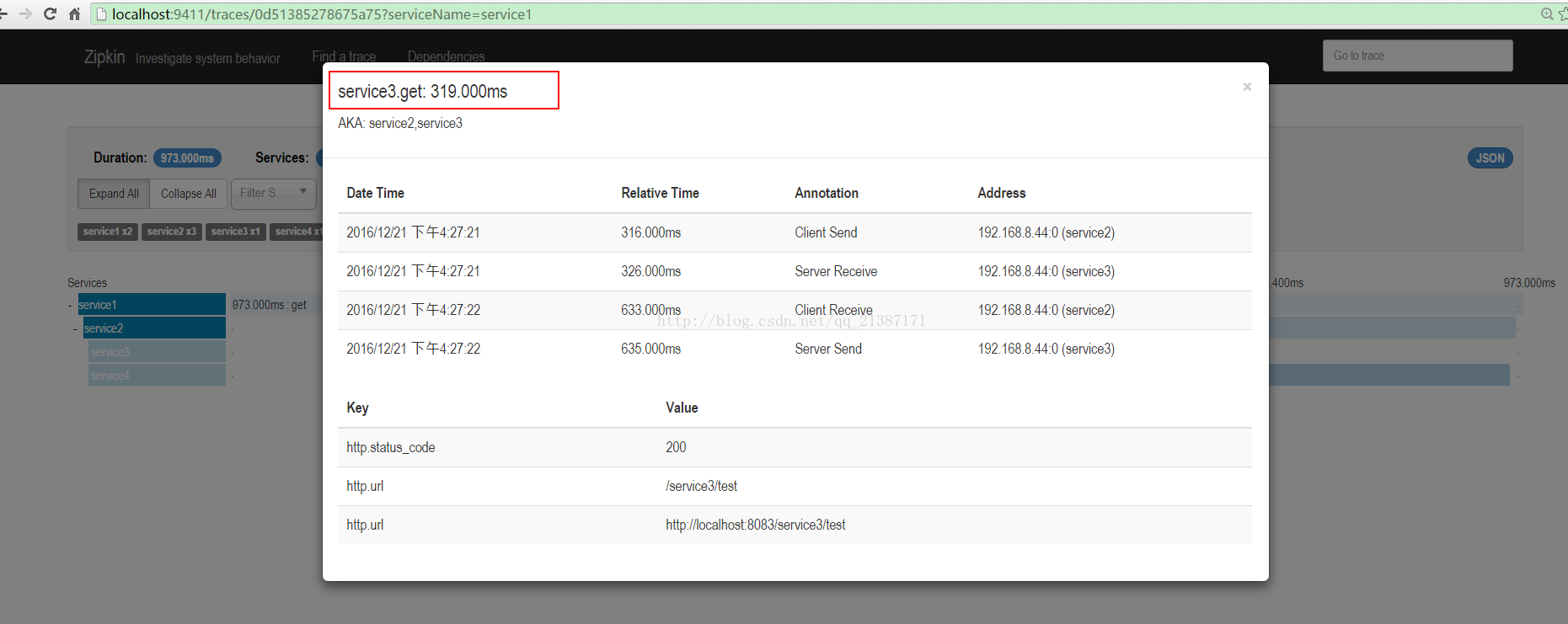
點選每個span可以獲取延遲資訊:
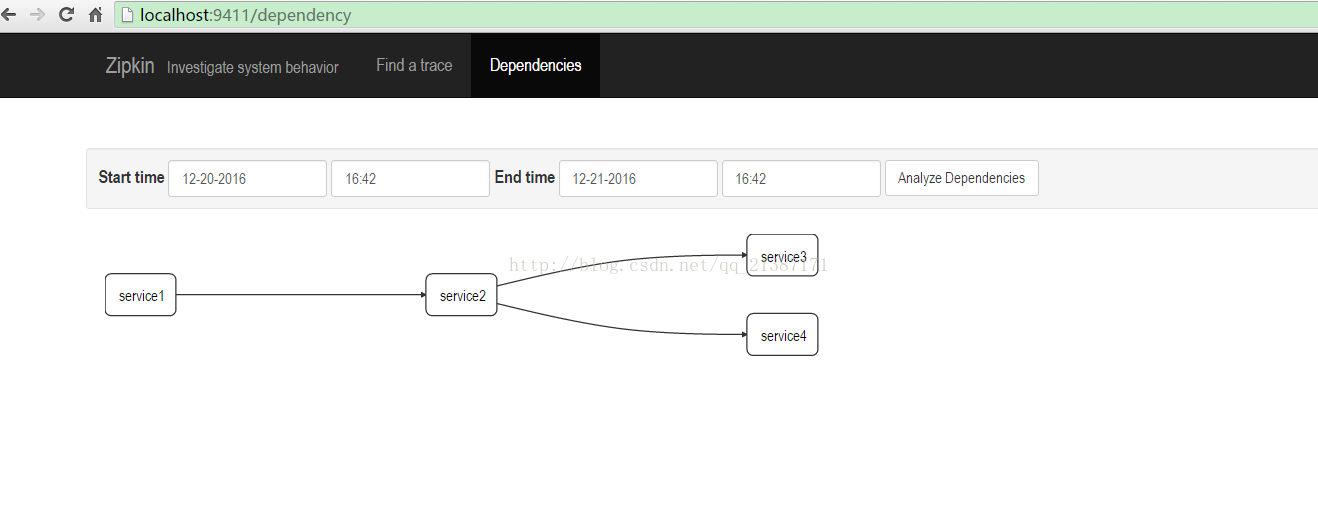
同時可以檢視服務之間的依賴關係:
測試Net平臺程式
將demo程式碼改為:
static void Main(string[] args) { var random = new Random(); // make sure Zipkin with Scribe client is working var collector = new HttpCollector(new Uri("http://localhost:9411/")); //var collector = new KafkaCollector(KafkaSettings.Default); var traceId = new TraceHeader(traceId: (ulong)random.Next(), spanId: (ulong)random.Next()); var span = new Span(traceId, new IPEndPoint(IPAddress.Loopback, 9000), "zipkinweb"); span.Record(Annotations.ClientSend(DateTime.UtcNow)); Thread.Sleep(100); span.Record(Annotations.ServerReceive(DateTime.UtcNow)); Thread.Sleep(100); span.Record(Annotations.ServerSend(DateTime.UtcNow)); Thread.Sleep(100); span.Record(Annotations.ClientReceive(DateTime.UtcNow)); collector.CollectAsync(span); }
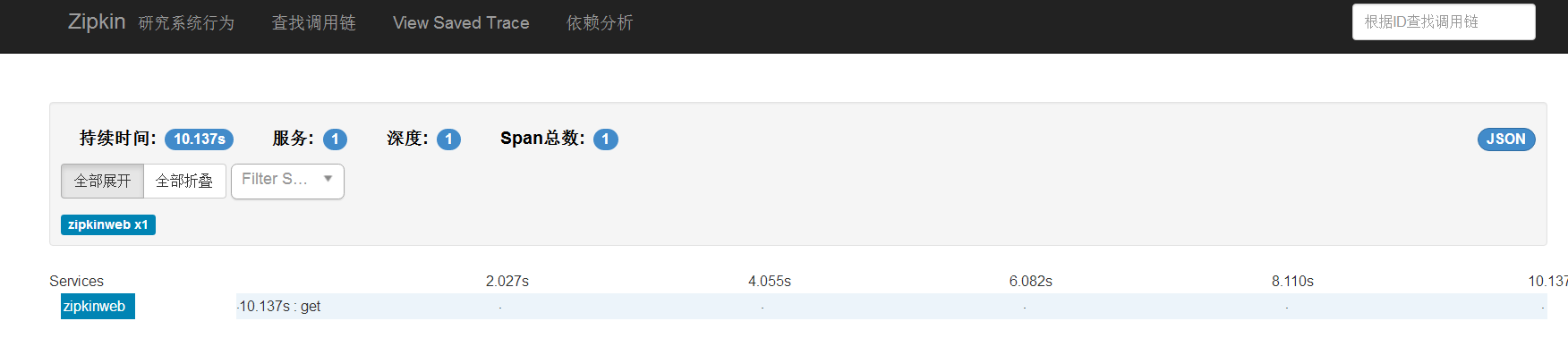
然後執行一次再檢視,會多出一條資訊

點進去會看到請求的詳細資訊和備註資訊:
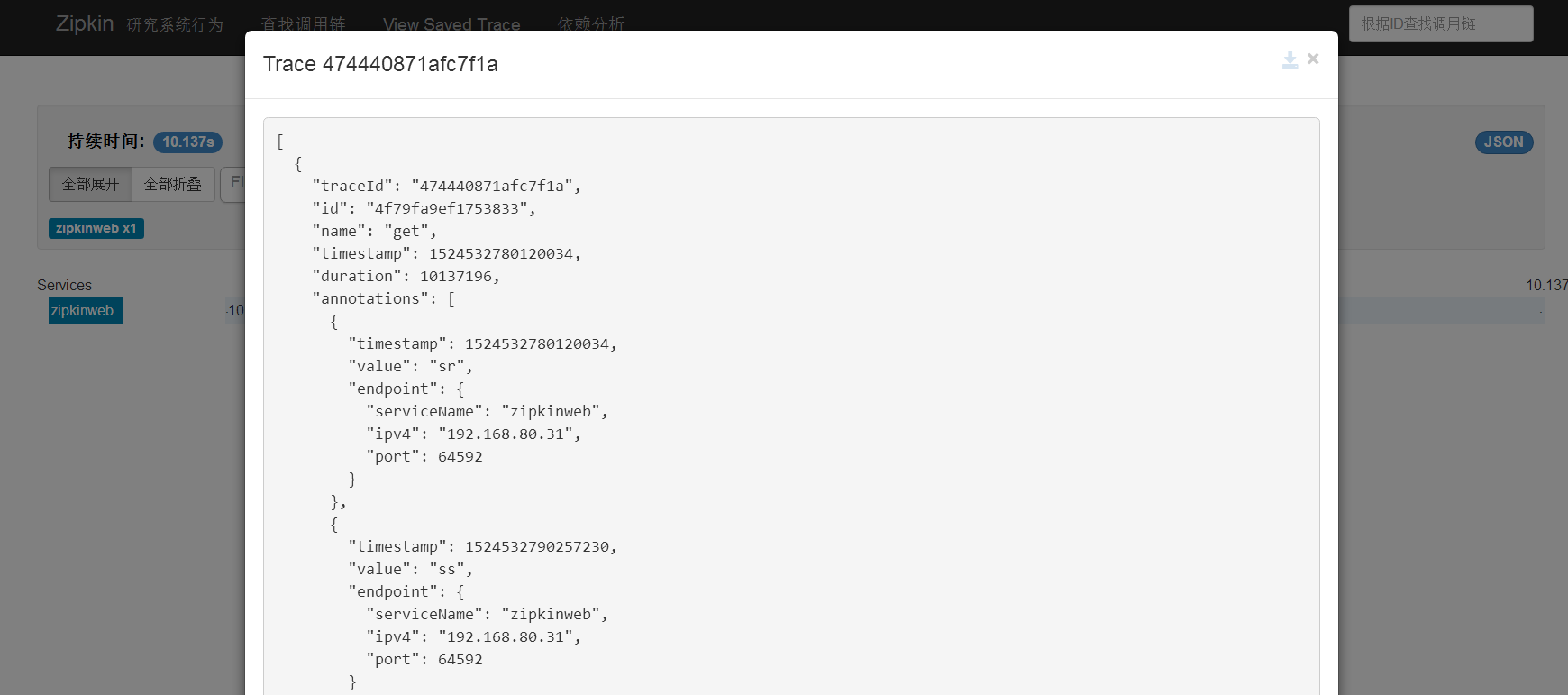
右上角檢視json
驗證了NET平臺下是可以成功呼叫的,而且可以看到zipkin服務前端展示是通過api請求的,前後臺分開的,因此我們可以以此來做二次開發,我們知道了資料結構或者通過自己請求資料庫內容做更復雜的業務前端。

這裡強調一點的是net最好用framework4.5以上的版本,由net的demo來看其實封裝性不高,所以靈活效能很高,需要自己進一步封裝才能達到程式碼的侵入性更少,效能更高。後面考慮到效能和資料量可改用kafka接收和ES儲存資料。