
核密度估計與自適應頻寬的核密度估計
最近看論文,發現一個很不錯的概率密度估計方法。在此小記一下。
先來看看準備知識。
密度估計經常在統計學中作為一種使用有限的樣本來估計其概率密度函式的方法。
我們在研究隨機變數的過程中,隨機變數的概率密度函式的作用是描述隨機變數的特性。(概率密度函式是用來描述連續型隨機變數取值的密集程度的,舉例:某地某次考試的成績近似服從均值為80的正態分佈,即平均分是80分,由正態分佈的圖形知x=80時的函式值最大,即隨機變數在80附近取值最密集,也即考試成績在80分左右的人最多。)但是在實際應用中,總體概率密度函式通常是未知的,那麼如何來估計總體概率密度呢?一般,我們通過抽樣或者採集一定的樣本,可以根據統計學知識從樣本集合中推斷總體概率密度。這種方法統稱為概率密度估計
引數估計(Parametric Estimation)是根據對問題的經驗知識,假設問題具有某種數學模型 ,隨機變數服從某種分佈,即先假定概率密度函式的形式,然後通過訓練資料估計出分佈函式的引數。常見的引數估計方法有極大似然估計方法和貝葉斯估計方法。對於引數估計,根據樣本中是否已知樣本所屬類別(即是否帶標籤)將引數估計又劃分為監督引數估計和非監督引數估計。監督引數估計是由 已知類別的樣本集對總體分佈的某些引數進行統計推斷 。而無監督引數估計已知總體概率密度函式形式但未知樣本所屬的類別,要求推斷出概率密度函式的某些引數 ,這種推斷方法稱之為非監督情況下的引數估計。
非引數估計
(若有閒暇,後續將極大似然、貝葉斯估計等等估計方法詳細總結)
這裡說說核密度估計方法(也有稱之為
進入正題
核密度估計的形式:
這裡
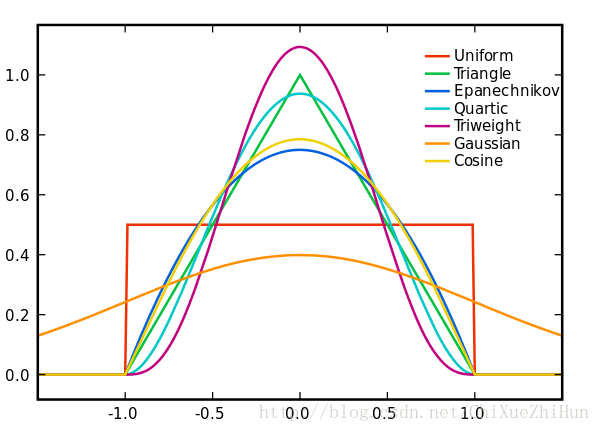
由於高斯核心方便的數學性質,也經常使用
舉例理解(該例子來自維基百科https://en.wikipedia.org/wiki/Kernel_density_estimation)
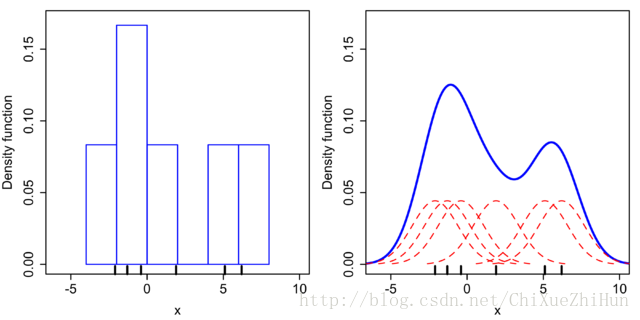
已知:6個數據點
對於直方圖,首先將水平軸劃分為覆蓋資料範圍的子間隔或區段。在這種情況下,我們有6個寬度為2的矩形。每當資料點落在此間隔內時,我們放置一個高度為
很明顯,直方圖得到的密度估計平滑程度比使用核密度估計得到的密度函式要差很多.
現在問題是如何選定核函式的“方差”呢?這其實是由
核頻寬的選擇
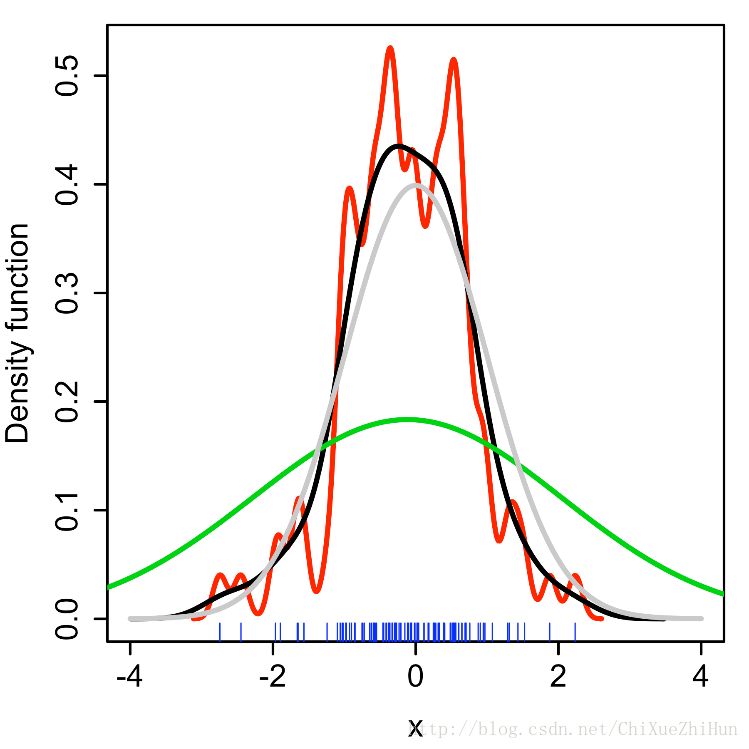
頻寬是一個自由引數,對所得到的估計值有很大的影響。為了說明效果,舉個例子:
下圖是從標準正態分佈中抽取的隨機樣本(橫軸上的藍色的點點代表樣本點)灰色曲線是真是的概率密度(正態密度,均值0,方差1)。相比之下,紅色曲線是使用了過小的頻寬
那麼對於
在
其中,
為了使
相關推薦
核密度估計與自適應頻寬的核密度估計
最近看論文,發現一個很不錯的概率密度估計方法。在此小記一下。 先來看看準備知識。 密度估計經常在統計學中作為一種使用有限的樣本來估計其概率密度函式的方法。 我們在研究隨機變數的過程中,隨機變數的概率密度函式的作用是描述隨機變數的特性。(概率密度函式是用來描
web前端-移動端響應式與自適應
logs lac tro 可維護 禁止 網頁 藍色 媒體查詢 [0 一. 在HTML的頭部加入meta標簽 在HTML的頭部,也就是head標簽中增加meta標簽,告訴瀏覽器網頁寬度等於設備屏幕寬度,且不進行縮放,代碼如下: <meta name="view
[ZZ] 多領域視覺數據的轉換、關聯與自適應學習
matching vld 性別 .science 多核 性能 調整 輸出 求解 哈工大左旺孟教授:多領域視覺數據的轉換、關聯與自適應學習 http://blog.sciencenet.cn/home.php?mod=space&uid=3291369&do
響應式與自適應的區別
響應式 的區別 TP 代碼 image bubuko com inf bsp 就一張圖 響應式(RWD) = 所有設備的代碼是一樣的 自適應(AWD)= 不同設備的代碼是不一樣的 就問你服不服 哈~哈~哈~哈響應式與自適應的區別
CS229 Machine Learning學習筆記:Note 12(強化學習與自適應控制)
inf 輸入 概念 play 化學 適應 UNC 之前 stat 強化學習的概念 在監督學習中,我們會給學習算法一個訓練集,學習算法嘗試使輸出盡可能接近訓練集給定的真實值y;訓練集中,對於每個樣本的輸入x,都有確定無疑的正確輸出y 在強化學習中,我們只會給學習算法一個獎勵函
Flex佈局與自適應rpx
Flex佈局 又稱(彈性佈局)是W3C組織在2009年提出的一個新的佈局方案,其宗旨是讓頁面的樣式佈局更加簡單,並且可以很好地支援響應式佈局,主要作用在容器上 flex-direction: 該屬性的值確定主軸的方向,軸有兩個方向,分別是水平和垂直 首次,設定display:fl
淺談響應式開發與自適應佈局!
談到響應式,大家不自覺的會想到什麼? 首先映入眼簾的便是隨著網頁寬度變化而網頁內容呈現出不同內容的效果!那麼由來是什麼呢? 2009時間段,網際網路發生了一件天大的事情! 那就是在北京時間2009年6月9日凌晨2:48分,在美國舊金山MosconeWest
互斥鎖,自旋鎖與自適應自旋鎖
執行緒安全與鎖的優化 互斥鎖: 從 實現原理上來講,Mutex屬於sleep-waiting型別的鎖。例如在一個雙核的機器上有兩個執行緒(執行緒A和執行緒B),它們分別執行在Core0和 Core1上。假設執行緒A想要通過pthread_mutex_lock
unity 2D 正交攝像機下 uGUi 比例與自適應問題
unity自帶的UGui普遍都有rect transform屬性 orthographic攝像機下 如果size是1 那麼半個高度的ugui canvas就是1單位長度, 一個cube是1米 1米
【雙11背後的技術】基於深度強化學習與自適應線上學習的搜尋和推薦演算法研究
1. 搜尋演算法研究與實踐 1.1 背景 淘寶的搜尋引擎涉及對上億商品的毫秒級處理響應,而淘寶的使用者不僅數量巨大,其行為特點以及對商品的偏好也具有豐富性和多樣性。因此,要讓搜尋引擎對不同特點的使用者作出針對性的排序,並以此帶動搜尋引導的成交提升,是一個極具挑戰性的問題。
Vulkan移植GpuImage(一)高斯模糊與自適應閾值
## 自適應閾值效果圖 [demo](https://github.com/xxxzhou/aoce/tree/master/samples/vulkanextratest)  計算樣本向量x的概率密度估計
LIBSVM使用與自定義核函式
LIBSVM訓練函式使用如下: model = svmtrain(trainlabel,traindata,'-s 0 -t 2 -c 1.2 -g 2.8') trainlabel:訓練樣本標籤 traindata:訓練樣本資料集,行向量為樣本值 SVM型別,用引數-s 設定,預設
順序性,一致性,原子性:現代多核體系結構與原子操作·CAS與自旋鎖·自旋鎖與併發程式設計的原語·語句原子性和程式設計邏輯的原子性·行鎖與資料庫事務原子性·binlog與資料庫同
順序性: 亂序執行·邏輯正確性 現代體系結構的每一個核的指令流水是亂序執行的,但是他能夠保證其執行效果正確,即等同於順序執行。 不過這帶來的問題是對於一個核在主觀上它的執行狀態最終保證正確,但是對於別的核,如果在某一箇中間時間點需要觀察它呢?看到的是一個不正確的
內核模板安裝與卸載
log archive 模板 內核 .net code tail 卸載 www http://www.linuxidc.com/Linux/2016-03/129476.htm http://blog.csdn.net/crazycoder8848/article/deta
Linux 內核中 likely 與 unlikely 的宏定義解析
帶來 內核版本 sta don 等價 ddc 編譯 views lines 在 2.6 內核中,隨處能夠見到 likely() 和 unlikely() 的身影,那麽為什麽要用它們?它們之間有什麽差別? 首先要明白: if(likel
CARTA:Gartner的持續自適應風險與信任評估戰略方法簡介
gartner carta 自適應 在2017年6月份舉辦的第23屆Gartner安全與風險管理峰會開幕式上,來自Gartner的三位VP級別的分析師(Ahlm, Krikken and Neil McDonald)分享一個題為《Manage Risk ,Build Trust, and Embr
Linux學習筆記之內核啟動流程與模塊機制
oid img 相關 call rootfs _exit alt 執行 分模塊 本文旨在簡單的介紹一下Linux的啟動流程與模塊機制: Linux啟動的C入口位於/Linux.2.6.22.6/init/main.c::start_kernel() 下圖簡要的描述了一下內核
css基礎 BFC 不與浮動元素產生交集、自適應
order src 效果 css基礎 border htm log 學習 w3c 禮悟: 公恒學思合行悟,尊師重道存感恩。葉見尋根三返一,江河湖海同一體。 虛懷若谷良心主,願行無悔給最苦。讀書鍛煉養身心,誠勸且行且珍惜。
自適應和響應式布局的區別,em與rem
樣式 都是 變化 使用 元素 屏幕大小 響應式 大小 媒體查詢 自適應布局:不同終端上顯示的文字,圖片,等位置排版都是一樣的,只是大小不同。 響應式布局:通過媒體查詢監聽屏幕大小的變化,做出響應式的改變,在不同設備可能展現不同的樣式效果。 em:是相對其父