
基於python,scrapy,redis實現主從式(分散式的一種)master-slave爬蟲
前言
這是本人的第一篇部落格,感觸還是很多的,最近在幫朋友做一個分散式爬蟲的論文,遇到很多坑,不過已經一一填平,廢話不多說啦。
分類
(1)主從分散式爬蟲:由一臺master伺服器, 來提供url的分發, 維護待抓取url的list。由多臺slave伺服器執行網頁抓取功能, slave所抽取的新url,一律由master來處理解析,而slave之間不需要做任何通訊。
(2)對等分散式爬蟲:
由多臺相同的伺服器整合,每臺伺服器可單獨運作,完成爬蟲工作,每臺伺服器之間的分工有一定的運算邏輯(ex: hash),由運算(配置)的結果,來決定由那臺伺服器做抓取網頁的工作。
本文講解第一種-主從式,只是簡單的闡明,所以master端只負責爬取url儲存到redis資料庫,slave端取出redis裡url佇列進行爬取網頁內容,解析並儲存到mongodb資料庫。
準備
python3(本人使用的是3.6版本)scrapy
redis
mongodb
安裝教程自行百度,使用到的python模組(這裡是需要使用pip安裝,最好是pip新版本):
scrapy-redis
pymongo
python連結mongodb例子:
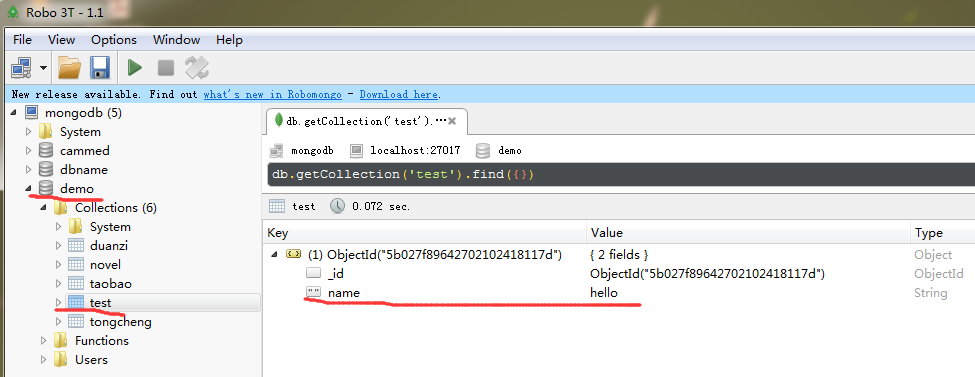
import pymongo as pm host = 'localhost' port = 27017 # 連結資料庫 client = pm.MongoClient(host,port) # 選擇db db = client.demo # 選擇集合test # 注意這裡的集合可以直接使用,如果沒有mongodb會自動建立 db.test.insert({"name":"hello"}) client.close()
實現
我們以58同城為例,爬取二手房,爬取中間有些錯誤但不影響,由於網站整改302重定向了。1. master端
spider檔案
from scrapy.spider import CrawlSpider,Rule from scrapy.linkextractors import LinkExtractor from master.items import MasterItem class myspider(CrawlSpider): name = 'master' allowed_domains = ['58.com'] item = MasterItem() start_urls = ['http://cd.58.com/ershoufang/'] rules = ( Rule(LinkExtractor(allow=('http://cd.58.com/ershoufang/\d{14}x.shtml.*?',)), callback='parse_item', follow=True), ) def parse_item(self,response): item = self.item item['url'] = response.url return item
繼承CrawlSpider可以遍歷整個網站,Rule和LinkExtractor限制遍歷那些網頁,allow為允許的網址(正則表示式),callback回撥函式,注意一定不能寫預設的parse函式。
item檔案
import scrapy
class MasterItem(scrapy.Item):
# define the fields for your item here like:
url = scrapy.Field()
pass只儲存url
middleware檔案
import random
from .useragent import agents
class UserAgentMiddleware(object):
def process_request(self, request, spider):
agent = random.choice(agents)
referer = request.meta.get('referer', None)
request.headers["User-Agent"] = agent
request.headers["Referer"] = referer這裡對預設的middleware檔案進行修改,useragent是自建的檔案,裡面agents=['內容略']陣列,欄位程式碼表示為每次請求隨機一個User-Agent(瀏覽器身份),一定程度避免認為是爬蟲。
pipeline檔案
import redis
class MasterPipeline(object):
def __init__(self):
self.redis_url = 'redis://123456:@localhost:6379/'
self.r = redis.Redis.from_url(self.redis_url,decode_responses=True)
def process_item(self, item, spider):
self.r.lpush('myredis:start_urls', item['url'])redis.Redis(host="localhost",port=6379)預設使用db0,一定要使用db0,否則slave端取不到資料(可能由於本人才疏學淺沒有找到連結其他db供slave端使用的方式)
setting檔案
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES = {
'master.middlewares.UserAgentMiddleware': 543,
}
ITEM_PIPELINES = {
'master.pipelines.MasterPipeline': 300,
}注意這裡只是部分程式碼不要覆蓋上去,替換相同的地方即可。爬蟲一開始會取得網站的robot.txt檔案(也叫君子協議檔案),得知那些網址可爬,我們設定ROBOTSTXT_OBEY=False不遵循他的協議。
2. slave端
spider檔案
import re
from scrapy_redis.spiders import RedisSpider
from scrapy.http import Request
from slave.items import SlaveItem
class myspider(RedisSpider):
name = 'slave'
item = SlaveItem()
redis_key = 'myredis:start_urls'
def parse(self, response):
item = self.item
item['title'] = response.xpath('//div[@class="house-title"]/h1/text()').extract()[0]
item['price'] = response.xpath('//div[@id="generalSituation"]//li[1]/span[2]/text()').extract()[0]
item['type'] = response.xpath("//div[@id='generalSituation']//li[2]/span[2]/text()").extract()[0]
item['area'] = response.xpath("//div[@id='generalSituation']//li[3]/span[2]/text()").extract()[0]
item['direct'] = response.xpath("//div[@id='generalSituation']//li[4]/span[2]/text()").extract()[0]
item['floor'] = response.xpath(
"//div[@id='generalSituation']//ul[@class='general-item-right']/li[1]/span[2]/text()").extract()[0]
item['decorat'] = response.xpath(
"//div[@id='generalSituation']//ul[@class='general-item-right']/li[2]/span[2]/text()").extract()[0]
item['start'] = response.xpath(
"//div[@id='generalSituation']//ul[@class='general-item-right']/li[4]/span[2]/text()").extract()[0]
item['village'] = response.xpath("string(/html/body/div[4]/div[2]/div[2]/ul/li[1]/span[2])").extract()[0]
item['position'] = response.xpath("string(/html/body/div[4]/div[2]/div[2]/ul/li[2]/span[2])").extract()[0]
item['phone'] = response.xpath("//div[@id='houseChatEntry']//p[@class='phone-num']/text()").extract()[0]
txt = response.xpath("/html/head/script[1]/text()").extract()[0]
pattern = re.compile(".*?____json4fe.brokerUrl = '(.*?)';.*?", re.S)
result = re.findall(pattern, txt)
yield Request("http://" + result[0], callback=self.get_user)
def get_user(self, response):
item = self.item
item['user'] = response.xpath("/html/body/div[2]/div[2]/div[1]/div[1]/div/div[1]/text()").extract()[0]
return item這裡不在講解xpath的用法,告訴你們一個好方法,瀏覽器F12選中一個元素,右鍵->複製->xpath。用redis_key代替start_urls,‘myredis:start_urls’為redis資料庫db0的鍵,就是我們master端儲存的,直接使用預設回撥函式parse。
item檔案
import scrapy
class SlaveItem(scrapy.Item):
title = scrapy.Field()
price = scrapy.Field()
type = scrapy.Field()
area = scrapy.Field()
direct = scrapy.Field()
floor = scrapy.Field()
decorat = scrapy.Field()
start = scrapy.Field()
village = scrapy.Field()
position = scrapy.Field()
user = scrapy.Field()
phone = scrapy.Field()
passmiddleware檔案(同master端)
pipeline檔案
import pymongo as pm
host = 'localhost'
port = 27017
client = pm.MongoClient(host,port)
db = client.demo.tongcheng
class SlavePipeline(object):
def process_item(self, item, spider):
db.insert(dict(item))儲存到mongodb資料庫
setting檔案
# 啟用Redis排程儲存請求佇列
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#不清除Redis佇列、這樣可以暫停/恢復 爬取
# SCHEDULER_PERSIST = True
# 確保所有的爬蟲通過Redis去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#指定用於連線redis的URL(可選)
#如果設定此項,則此項優先順序高於設定的REDIS_HOST 和 REDIS_PORT
REDIS_URL = 'redis://[email protected]:6379/'
BOT_NAME = 'slave'
SPIDER_MODULES = ['slave.spiders']
NEWSPIDER_MODULE = 'slave.spiders'
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES = {
'slave.middlewares.UserAgentMiddleware': 543,
}
ITEM_PIPELINES = {
'slave.pipelines.SlavePipeline': 300,
}加入和替換配置
結果
redis資料庫
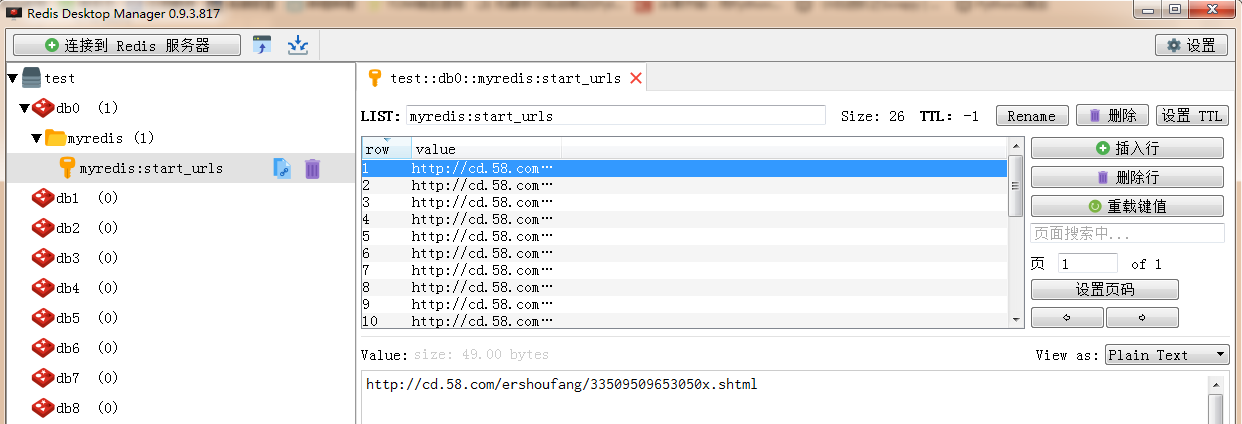
mongodb資料庫

最後
本人也是小白,寫的粗糙,有不懂或見解的地方一起交流。
相關推薦
基於python,scrapy,redis實現主從式(分散式的一種)master-slave爬蟲
前言這是本人的第一篇部落格,感觸還是很多的,最近在幫朋友做一個分散式爬蟲的論文,遇到很多坑,不過已經一一填平,廢話不多說啦。分類(1)主從分散式爬蟲:由一臺master伺服器, 來提供url的分發, 維護待抓取url的list。由多臺slave伺服器執行網頁抓取功能, sla
Python基於皮爾遜系數實現股票預測(多線程)
author top def split pat init -s bubuko odi 1 # -*- coding: utf-8 -*- 2 """ 3 Created on Tue Dec 4 08:53:08 2018 4 5 @a
Redis實現主從複製(Master&Slave)
由於前段時間公司專案比較趕,一直抽不出時間寫部落格,今天偷空寫一篇吧。前面給大家講解了單機版redis的基本操作,現在繼續給大家講解一下Redis的進階部分,主從複製和讀寫分離。 一、Master&Slave是什麼? 也就是我們所
(Flask Web開發:基於Python的Web應用開發實戰)------學習筆記(第2章)
第2章 程式的基本結構 本章將帶你瞭解 Flask 程式各部分的作用,編寫並執行第一個 Flask Web 程式。 2.1 初始化 所有 Flask 程式都必須建立一個程式例項,程式例項是 Flask 類的物件。 Web 伺服器使用一種名為 Web 伺服器閘
linux上一鍵安裝redis以及主從配置(指令碼自動安裝)
一、環境配置 1:任何位置建立資料夾 mkdir redis;cd redis;mkdir conf;cd conf #下載安裝安裝包 wget http://www.redis.cn/download.html/redis-5.0.3.tar.g
python版:單機redis實現秒殺,防止超限
測試環境 ubuntu 16.04 python 3.6.6 redis 3.0.6 簡單描述 搶購、秒殺是一個很常見的應用場景,主要需要解決的問題有兩個: 1 高併發 2 如何解決庫存的正確減少("超賣"問題) redis 命令說明 exists 返回key是否
Python識別圖形驗證碼,實現自動登陸(附視訊教程)
驗證碼有圖形驗證碼、極驗滑動驗證碼、點觸驗證碼、宮格驗證碼。這回重點講講圖形驗證碼的識別。 雖說圖形驗證碼最簡單,但是對於我這等新手,還是要苦學一番。首先尋找測試網站,網站選的是如雲閣小說網,小網站不怕被封。他們的驗證碼一般如下:視訊教程: &n
Nginx+Tomcat搭建叢集,Spring Session+Redis實現Session共享
小夥伴們好久不見!最近略忙,部落格寫的有點少,嗯,要加把勁。OK,今天給大家帶來一個JavaWeb中常用的架構搭建,即Nginx+Tomcat搭建服務叢集,然後通過Spring Session+Redis實現Session共享。 閱讀本文需要有如下知識點:
15.7,哨兵叢集 redis-sentinel主從複製高可用
redis-sentinel主從複製高可用 Redis-Sentinel Redis-Sentinel是redis官方推薦的高可用性解決方案,當用redis作master-slave的高可用時,如果master
容器雲環境下,Nginx+tomcat+redis實現web專案叢集
環境:由於在Windows下Tomcat8與Nginx實驗不成功,錯誤的認為8不行,就有了下面的歷程,,,,經過請教師兄,發現自己的方法不對, #利用centos基礎映象以及jdk Tomcat 編輯新的映象Tomcat7 #刪掉jdk資料夾下多餘檔案, 降低build的
企業實戰-KeepAlived+Redis實現主從熱備、秒級切換
keepalived redis 楊文 最近公司生產環境需要做一個Redis+Keepalived的集群架構,分別用六個端口,實現多路復用,最終實現主從熱備、秒級切換。一、部署Redis集群首先用兩臺虛擬機模擬6個節點,一臺機器3個節點,創建出3 master、3 salve 環境。然後模擬成功,
Nginx+keepalived做雙機熱備,實現負載均衡(主主模式)
nginx keepalive Keepalived: 簡介:Keepalived的作用是檢測服務器的狀態,如果有一臺web服務器宕機,或工作出現故障,Keepalived將檢測到,並將有故障的服務器從系統中剔除,同時使用其他服務器代替該服務器的工作,當服務器工作正常後Keepali
淺談基於Python的Scrapy爬蟲入門
Python爬蟲教程 Python內容講解 (一)內容分析 接下來創建一個爬蟲項目,以圖蟲網為例抓取裏面的圖片。在頂部菜單“發現”“標簽”裏面是對各種圖片的分類,點擊一個標簽,比如“Python視頻課程”,網頁的鏈接為:http://www.codingke.com/Python視頻課程/,我們以
腳本一鍵安裝redis實現主從復制
redis自動化安裝腳本安裝腳本及配置文件上傳至家目錄即可,sh執行腳本即可選擇主從#!/bin/bash#Description:atuo install redis#Date:2018.4.11 Download_redis=http://download.redis.io/releases/redis
Redis實現主從復制(Master&Slave)
現在 開啟 博客 ont water 備機 mil 一個數 投票 由於前段時間公司項目比較趕,一直抽不出時間寫博客,今天偷空寫一篇吧。前面給大家講解了單機版redis的基本操作,現在繼續給大家講解一下Redis的進階部分,主從復制和讀寫分離。 一、Ma
基於python+whoosh的全文檢索實現
whoosh的官方介紹:http://whoosh.readthedocs.io/en/latest/quickstart.html 因為做的是中文的全文檢索需要匯入jieba工具包以及whoosh工具包 直接上程式碼吧 from whoosh.qparser import QueryPa
實現客戶端寫入字串,在服務端翻轉後返回(多執行緒)
實現客戶端寫入字串,在服務端翻轉後返回 服務端: package network.tcp; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import
mysql5.7 yum安裝及主從配置(從庫只讀),不重啟主庫新增從庫配置
yum -y remove mysql wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm rpm -ivh mysql57-community-release-el7-8.noarch.rpm yum -y ins
使用思事標籤,實現包含GTD模式的一種方法
GTD(Getting Things Done)工作法,很多軟體採用了這個模式。它具體做法可以分成收集、整理、組織、回顧與行動五個步驟。我使用思事的標籤,預設標籤很方便的實現了GTD模式,同時還設定了一些自己需要的、常用的標籤,請參考。 下圖為我的標籤截圖: 關
關於將aop功能封裝成jar包後,被其他模組依賴後,aop功能無法實現的問題(包掃描)
在開發中,將aop的功能寫到了公共模組後,然後將公共模組封裝成jar包,被其他專案所依賴。但是出現aop功能無法實現,是因為未掃描到該包下的類,需要在引用模組的啟動類中加入掃描的程式碼 @ComponentScan(basePackages = {"xxx.xxx.*"})