頻繁項集挖掘演算法——Apriori演算法
前言
關聯規則就是在給定訓練項集上頻繁出現的項集與項集之間的一種緊密的聯絡。其中“頻繁”是由人為設定的一個閾值即支援度 (support)來衡量,“緊密”也是由人為設定的一個關聯閾值即置信度(confidence)來衡量的。這兩種度量標準是頻繁項集挖掘中兩個至關重 要的因素,也是挖掘演算法的關鍵所在。對項集支援度和規則置信度的計算是影響挖掘演算法效率的決定性因素,也是對頻繁項集挖掘進行改進的入口點和研究熱點。
基於關聯規則的分類主要分為以下以個步驟:
1. 對訓練資料進行預處理(包括離散化、缺失值處理等)
2. 關聯規則挖掘
2.1 頻繁項集挖掘
2.2 關聯規則生成
3. 規則處理
4. 對測試集進行測試
在關聯規則挖掘中,最耗費時間和空間資源的就是頻繁項集挖掘,目前針對頻繁項集挖掘已經有很多比較成熟的演算法,在時間效率或空間效率對頻繁項集的挖掘進行不斷的優化和改進。
接下來的幾篇部落格都是筆者在閱讀論文或者相關文獻資料中學習的幾個頻繁項集挖掘演算法的介紹,在這裡分享一下,與大家一起學習~
Apriori演算法
演算法中最經典的莫過於Apriori演算法,它可以算得上是頻繁項集挖掘演算法的鼻祖,後續很多的改進演算法也是基於Apriori演算法的。但是遺憾的是Apriori演算法的效能一般,但是即使如此,該演算法卻是頻繁項集挖掘必須要掌握的入門演算法。
相關定義:
定義1. 設I={i1,i2,…,im}是一個全域性項的集合,其中ij(1≤j≤m)是項(item)的唯一標識,j表示項的序號。
事務資料庫(transactional databases)D={t1,t2,…,tn}是一個事務(transaction)的集合,每個事務ti(1≤i≤n)都對應I上的一個子集,其中ti是事務的唯一標識,i表示事務的序號。
定義2. 由I中部分或全部項構成的一個集合稱為項集(itemset),任何非空項集中均不含有重複項。如I1={i1,i3,i4}就是一個項集。
定義3. 給定一個全域性項集I和事務資料庫D,一個項集

支援度是一種重要性度量,因為低支援度的規則可能只是偶然出現。從實際情況看,低支援度的規則多半是沒有意義的。例如,顧客很少同時購買a、b商品,想通過對a或b商品促銷(降價)來提高另一種商品的銷售量是不可能的。
定義4. 給定D上的最小支援度(記為min_sup),稱為最小支援度閾值。
定義5. 給定全域性項集I和事務資料庫D,對於I的非空子集I1,若其支援度大於或等於min_sup,則稱I1為頻繁項集(Frequent Itemsets)。
定義6. 對於I的非空子集I1,若某項集I1中包含有I中的k個項,稱I1為k-項集。
若k-項集I1是頻繁項集,稱為頻繁k-項集。顯然,一個項集是否頻繁,需要通過事務資料庫D來判斷。
Apriori性質
(1)若A是一個頻繁項集,則A的每一個子集都是一個頻繁項集。
(2)若A是一個頻繁項集,則A的每一個子集都是一個頻繁項集。
基本的Apriori演算法
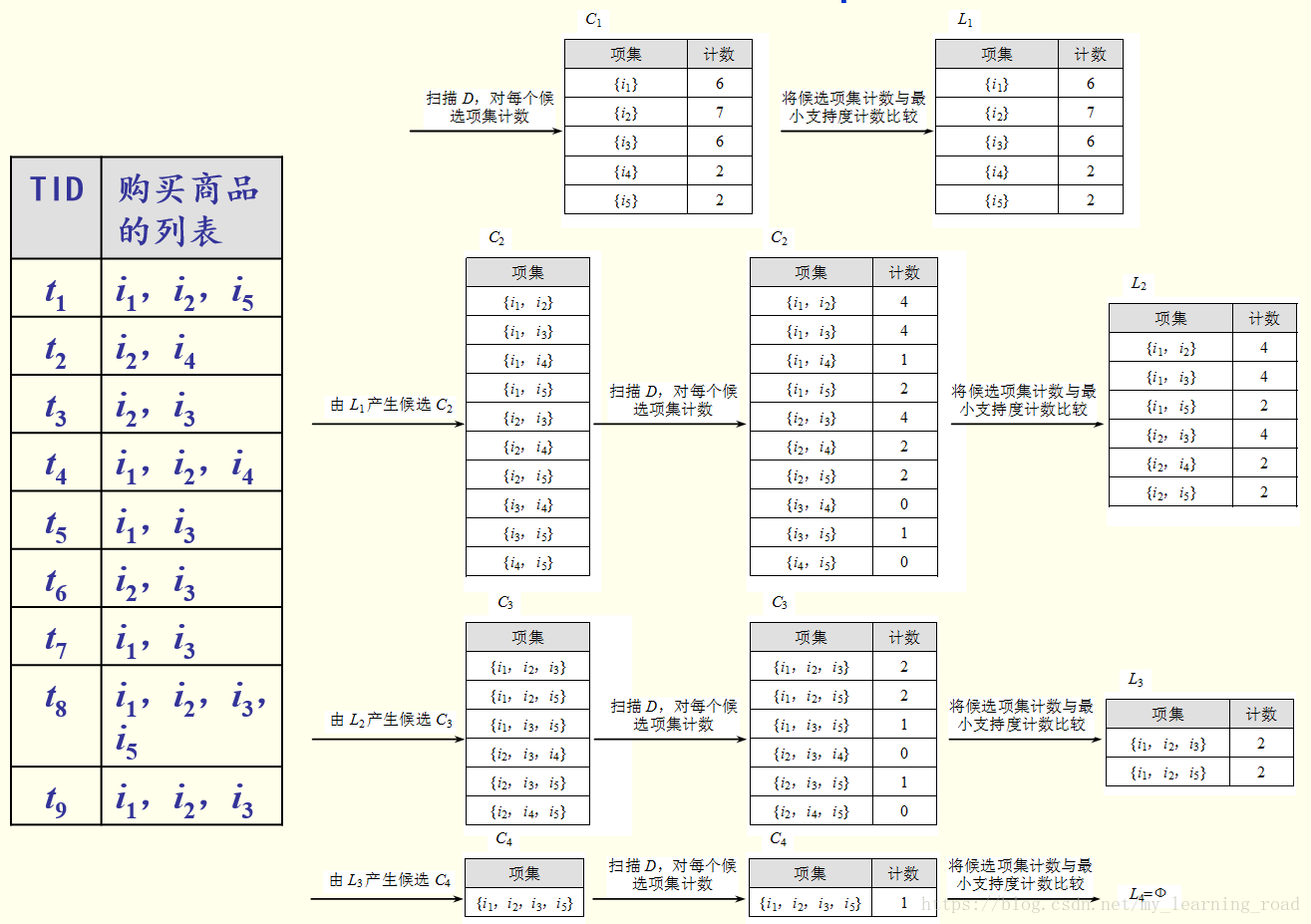
Apriori演算法的基本思路是採用層次搜尋的迭代方法,由候選(k-1)-項集來尋找候選k-項集,並逐一判斷產生的候選k-項集是否是頻繁的。設Ck是長度為k的候選項集的集合,Lk是長度為k的頻繁項集的集合。為了簡單,設最小支援度閾值min_sup為最小元組數,即採用最小支援度計數。
輸入:事務資料庫D,最小支援度閾值min_sup。
輸出:所有的頻繁項集集合L。
方法:其過程描述如下:通過掃描D得到1-頻繁項集L1;
for (k=2;Lk-1!=Ф;k++)
{ Ck=由Lk-1通過連線運算產生的候選k-項集;
for (事務資料庫D中的事務t)
{ 求Ck中包含在t中的所有候選k-項集的計數;
Lk={c | c∈Ck and c.sup_count≥min_sup};
//求Ck中滿足min_sup的候選k-項集
}
}
return L=∪kLk;
舉例
對於下表1.1所示的事務資料庫,設min_sup=2,產生所有頻繁項集的過程如右圖所示,最後L4=Ф,演算法結束,產生的所有頻繁項集為L1∪L2∪L3。