
資料歸一化matlab及python 實現
歸一化的目的簡而言之,是使得沒有可比性的資料變得具有可比性,同時又保持相比較的兩個資料之間的相對關係。
歸一化首先在維數非常多的時候,可以防止某一維或某幾維對資料影響過大,其次可以程式可以執行更快。
資料歸一化應該針對屬性,而不是針對每條資料,針對每條資料是完全沒有意義的,因為只是等比例縮放,對之後的分類沒有任何作用。
Three common methods are used to perform feature normalization in machine learning algorithms.
Rescaling
The simplest method is rescaling the range of features by linear function. The common formula is given as:
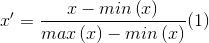
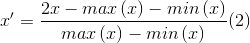
where x is the original value, x’ is the normalized value.
The equation (1) rescales data into [0,1], and the equation (2) rescales data into [-1,1].
Note: the parameters max(x) and min(x) should be computed in the training data only, but will be used in the training, validation, and testing data later.
我們必須使用同樣的方法縮放訓練資料和測試資料
縮放的最主要優點是能夠避免大數值區間的屬性過分支配了小數值區間的屬性。另一個優點能避免計算過程中數值複雜度。
線性函式轉換將一系列資料對映到相應區間,例如將所有資料對映到1~100,可用下列函式
y=((x-min)/(max-min))*(100-1)+1;
min是資料集中最小值,max是最大值
同理若將所有資料對映到a~b,可用下列函式
y=((x-min)/(max-min))*(b-a)+a;
There are also some methods to normalize the features using non-linear function, such as
logarithmic function:
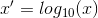
inverse tangent function:
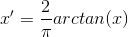
sigmoid function:
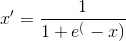
Standardization
Feature standardization makes the values of each feature in the data have zero-mean and unit-variance. This method is widely used for normalization in many machine learning algorithms (e.g., support vector machines,logistic regression, and neural networks). The general formula is given as:
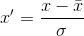
where is the standard deviation of the feature .
舉例說明(MATLAB):
% X is train data;
X=[790 3977 849 1294 1927 1105 204 1329
768 5037 1135 1330 1925 1459 275 1487
942 2793 820 814 1617 942 155 976
916 2798 901 932 1599 910 182 1135
1006 2864 1052 1005 1618 839 196 1081];
% 方法一
[Z,mu,sigma] = zscore(X)
% 方法二
[s t] = size(X)
Y=(X-repmat(mean(X),s,1))./repmat(std(X),s,1);
% Xnew is test data
[m n] = size(Xnew);
%
Ynew = ((Xnew-repmat(mu,m,1))./repmat(sigma,m,1))Scaling to unit length
Another option that is widely used in machine-learning is to scale the components of a feature vector such the complete vector has length one:
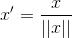
This is especially important if the Scalar Metric is used as a distance measure in the following learning steps.
3. Some cases you don’t need data normalization
3.1 using a similarity function instead of distance function
You can propose a similarity function rather than a distance function and plug it in a kernel (technically this function must generate positive-definite matrices).
3.2 Random Feforest
For random forests on the other hand, since one feature is never compared in magnitude to other features, the ranges don’t matter. It’s only the range of one feature that is split at each stage.
Random Forest is invariant to monotonic transformations of individual features. Translations or per feature scalings will not change anything for the Random Forest. SVM will probably do better if your features have roughly the same magnitude, unless you know apriori that some feature is much more important than others, in which case it’s okay for it to have a larger magnitude.
備註:
(1)在分類、聚類演算法中,需要使用距離來度量相似性的時候、或者使用PCA技術進行降維的時候,第二種方法(Z-score standardization)表現更好。
(2)在不涉及距離度量、協方差計算、資料不符合正太分佈的時候,可以使用第一種方法或其他歸一化方法。比如影象處理中,將RGB影象轉換為灰度影象後將其值限定在[0 255]的範圍。
不同型別資料要進行融合,也得將不同型別資料歸一化處理後進行運算
有些模型在各個維度進行不均勻伸縮後,最優解與原來不等價,例如SVM。對於這樣的模型,除非本來各維資料的分佈範圍就比較接近,否則必須進行標準化,以免模型引數被分佈範圍較大或較小的資料dominate。
有些模型在各個維度進行不均勻伸縮後,最優解與原來等價,例如logistic regression。對於這樣的模型,是否標準化理論上不會改變最優解。但是,由於實際求解往往使用迭代演算法,如果目標函式的形狀太“扁”,迭代演算法可能收斂得很慢甚至不收斂。所以對於具有伸縮不變性的模型,最好也進行資料標準化。
問題2:機器學習資料歸一化的的方法有哪些?適合於什麼樣的資料?
答:
1. 最值歸一化。比如把最大值歸一化成1,最小值歸一化成-1;或把最大值歸一化成1,最小值歸一化成0。適用於本來就分佈在有限範圍內的資料。
2. 均值方差歸一化,一般是把均值歸一化成0,方差歸一化成1。適用於分佈沒有明顯邊界的情況,受outlier影響也較小。
具體可檢視:
https://www.zhihu.com/question/26546711/answer/62085061
問題3:為什麼 feature scaling 會使 gradient descent 的收斂更好?
答:如果不歸一化,各維特徵的跨度差距很大,目標函式就會是“扁”的:
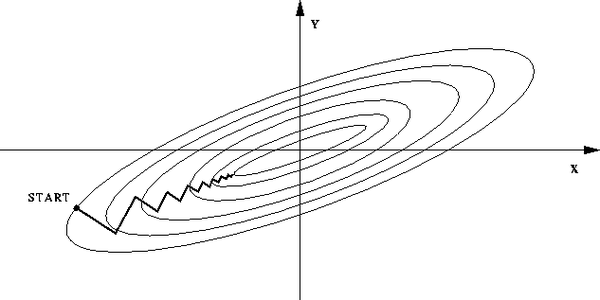
(圖中橢圓表示目標函式的等高線,兩個座標軸代表兩個特徵)
這樣,在進行梯度下降的時候,梯度的方向就會偏離最小值的方向,走很多彎路。
如果歸一化了,那麼目標函式就“圓”了:
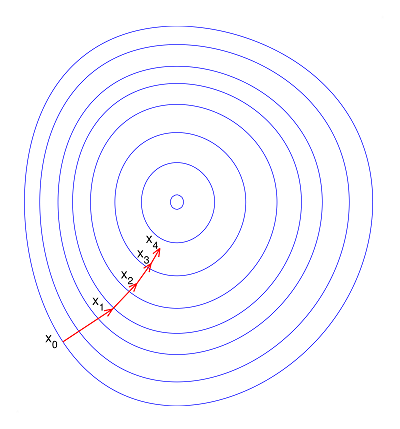
問題4:資料特徵的歸一化,是對整個矩陣還是對每一維特徵?
答:整體做歸一化相當於各向同性的放縮,做了也沒有用。
各維分別做歸一化會丟失各維方差這一資訊,但各維之間的相關係數可以保留。
如果本來各維的量綱是相同的,最好不要做歸一化,以儘可能多地保留資訊。
如果本來各維的量綱是不同的,那麼直接做PCA沒有意義,就需要先對各維分別歸一化。
具體可檢視:
https://www.zhihu.com/question/31186681/answer/50929278
MATLAB程式碼實現
function [X_norm, mu, sigma] = featureNormalize(X)
%FEATURENORMALIZE Normalizes the features in X
% FEATURENORMALIZE(X) returns a normalized version of X where
% the mean value of each feature is 0 and the standard deviation
% is 1. This is often a good preprocessing step to do when
% working with learning algorithms.
% You need to set these values correctly
% ====================== YOUR CODE HERE ======================
% Instructions: First, for each feature dimension, compute the mean
% of the feature and subtract it from the dataset,
% storing the mean value in mu. Next, compute the
% standard deviation of each feature and divide
% each feature by it's standard deviation, storing
% the standard deviation in sigma.
%
% Note that X is a matrix where each column is a
% feature and each row is an example. You need
% to perform the normalization separately for
% each feature.
%
% Hint: You might find the 'mean' and 'std' functions useful.
%
% let's calculate the total number of features
%mean([1; 2; 3; 4]) returns 2.5
%X(:,1) is the price of the houses
%X(:,2) is the number of bedrooms
%mu(1,1) = accessing the position of mu
%mu(1,2) = 2
% updating the positions of a given matrix's column
%d = [1 2; 3 4; 5 6]
%d(:, 1) = d(:, 1) .- d(:, 1)
% As defined in the class notes, n is the number of features.
n = size(X, 2);
% the given values of mu and sigma as initial zeros
mu = zeros(1, n);
sigma = zeros(1, n);
for featureColumn = 1:n
mu(1, featureColumn) = mean(X(:, featureColumn));
X(:, featureColumn) = X(:, featureColumn) .- mu(1, featureColumn);
sigma(1, featureColumn) = std(X(:, featureColumn));
X(:, featureColumn) = X(:, featureColumn) ./ sigma(1, featureColumn);
end;
% updating the value of the return X_norm
X_norm = X;
%disp(mu)
%disp(sigma)
% ============================================================
end 此外在matlab中也可以採用
[Z,mu,sigma] = zscore(X)
實現各個維度的標準化特徵Z。在求得mu和sigma後,如果新來一個特徵向量x,外面可以採用z = (x–mu)./sigma求得該向量的標準化向量。
matlab對訓練集和測試集歸一化
關於是否將訓練集和測試集放在一起進行歸一化有待討論,若在一起,則會讓測試集受到訓練集的影響,導致訓練集和測試集不相互獨立。正確的做法是記錄下訓練集的歸一化方法,用該方法對測試集單獨進行歸一化,matlab中的mapminmax函式提供了相應的機制。
對於一條新的資料,應該先按照訓練集的歸一化方法進行歸一化,再進行分類。
可通過
inst = [1 2 3 4; 2 3 4 5; 3 4 5 6];
[inst_norm, settings] = mapminmax(inst);
test = [1 3 5]';
test_norm = mapminmax('apply', test, settings)
test_norm =
-1.0000
-0.3333
0.3333解釋說明:該資料inst為3行4列,每一列代表一個數據,每一行代表同一個屬性,即資料個數為4個,屬性個數為3個,由於歸一化是針對於屬性歸一化的,所以每個屬性都對於一個歸一化的函式。
y = (ymax-ymin)*(x-xmin)/(xmax-xmin) + ymin,此時ymax=1,ymin=-1.
屬性1:y=2*(x-1)/(4-1) + (-1);
屬性2:y=2*(x-2)/(5-2) + (-1);
屬性3:y=2*(x-3)/(6-3) + (-1);那麼對於test = [1 3 5]’歸一化後,可得出相應的屬性值為
屬性1:y=2*(1-1)/(4-1) + (-1)=-1;
屬性2:y=2*(3-2)/(5-2) + (-1)=-0.333;
屬性3:y=2*(5-3)/(6-3) + (-1)=0.333;這裡的資料都是列數為樣本個數,行數為屬性個數。
其中settings記錄了訓練集的歸一化方法,得到以下歸一化結果
mapminmax會跳過NaN資料,最好的方法是歸一化之後,將NaN賦值成0。
inst_norm(find(isnan(inst_norm))) = 0;下面我們對mapminmax的用法進行詳解
[Y,PS] = mapminmax(X)
[Y,PS] = mapminmax(X,FP)
Y = mapminmax('apply',X,PS)
X = mapminmax('reverse',Y,PS)用例項來講解,測試資料 x1 = [1 2 4], x2 = [5 2 3];
[y,ps] = mapminmax(x1)
y =
-1.0000 -0.3333 1.0000
ps =
name: 'mapminmax'
xrows: 1
xmax: 4
xmin: 1
xrange: 3
yrows: 1
ymax: 1
ymin: -1
yrange: 2
no_change: 0
gain: 0.6667
xoffset: 1其中y是對進行某種規範化後得到的資料,這種規範化的對映記錄在結構體ps中.讓我們來看一下這個規範化的對映到底是怎樣的?
Algorithm
It is assumed that X has only finite real values, and that the elements of each row are not all equal.
y = (ymax-ymin)*(x-xmin)/(xmax-xmin) + ymin;
[關於此演算法的一個問題.演算法的假設是每一行的元素都不想相同,那如果都相同怎麼辦?實現的辦法是,如果有一行的元素都相同比如xt = [1 1 1],此時xmax = xmin = 1,把此時的變換變為y = ymin,matlab內部就是這麼解決的.否則該除以0了,沒有意義!]
也就是說對x1 = [1 2 4]採用這個對映 f: 2*(x-xmin)/(xmax-xmin)+(-1),就可以得到y = [ -1.0000 -0.3333 1.0000]
我們來看一下是不是: 對於x1而言 xmin = 1,xmax = 4;
則y(1) = 2*(1 - 1)/(4-1)+(-1) = -1;
y(2) = 2*(2 - 1)/(4-1)+(-1) = -1/3 = -0.3333;
y(3) = 2*(4-1)/(4-1)+(-1) = 1;
看來的確就是這個對映來實現的.
對於上面algorithm中的對映函式 其中ymin,和ymax是引數,可以自己設定,預設為-1,1;
比如
[y,ps] = mapminmax(x1);
ps.ymin = 0;
[y,ps] = mapminmax(x1,ps)
y =
0 0.3333 1.0000
ps =
name: 'mapminmax'
xrows: 1
xmax: 4
xmin: 1
xrange: 3
yrows: 1
ymax: 1
ymin: 0
yrange: 1
no_change: 0
gain: 0.3333
xoffset: 1則此時的對映函式為: f: 1*(x-xmin)/(xmax-xmin)+(0)
如果對x1 = [1 2 4]採用了某種規範化的方式, 現在要對x2 = [5 2 3]採用同樣的規範化方式[同樣的對映],如下可辦到:
[y1,ps] = mapminmax(x1);
y2 = mapminmax('apply',x2,ps)
y2 =
1.6667 -0.3333 0.3333即對x1採用的規範化對映為: f: 2*(x-1)/(4-1)+(-1),(記錄在ps中),對x2也要採取這個對映.
x2 = [5,2,3],用這個對映我們來算一下.
y2(1) = 2(5-1)/(4-1)+(-1) = 5/3 = 1+2/3 = 1.66667
y2(2) = 2(2-1)/(4-1)+(-1) = -1/3 = -0.3333
y2(3) = 2(3-1)/(4-1)+(-1) = 1/3 = 0.3333
X = mapminmax(‘reverse’,Y,PS)的作用就是進行反歸一化,講歸一化的資料反歸一化再得到原來的資料:
[y1,ps] = mapminmax(x1);
xtt = mapminmax('reverse',y1,ps)
xtt =
1 2 4