
【ATF】林偉:大資料計算平臺的研究與實踐
2016 ATF阿里技術論壇於4月15日在清華大學舉辦,主旨是闡述阿里對世界創新做出的貢獻。阿里巴巴集團技術委員會主席王堅,阿里巴巴集團首席技術官(CTO)張建鋒(花名:行癲),阿里巴巴集團首席風險官(CRO)劉振飛(花名:振飛),螞蟻金服首席技術官(CTO)程立(花名:魯肅)以及來自阿里巴巴集團各部門多位技術大咖齊聚一堂,與莘莘學子分享阿里的技術夢想。
在下午的雲端計算與大資料論壇上,阿里雲資深專家林偉(花名:偉林)帶來了以《大資料計算平臺的研究與實踐》為主題的深度分享。林偉目前負責阿里雲MaxCompute平臺的架構設計,在加入阿里雲之前,就職於微軟總部BingInfrastructure團隊,從事大資料平臺Cosmos/Scope的研發。在大資料領域研究多年的他,演講內容非常務實,引發學生們的多次互動。
他的分享主題聚焦目前阿里雲在大資料計算平臺建設過程中的一些思考,以及在面對資料儲存、資源排程等挑戰時的解決思路和實踐經驗,同時對大資料計算平臺建設的最新進展進行了簡明的介紹。本文內容根據其演講內容整理。
分散式檔案系統
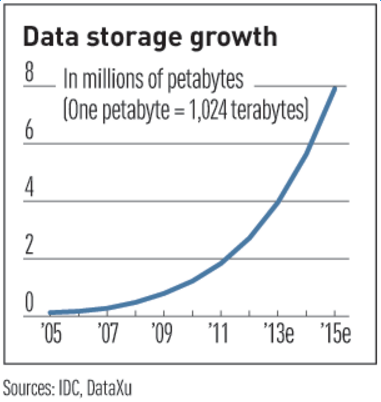
圖1 資料的增長速度曲線
相關研究資料表明,我們正面臨的是一個數據指數爆炸的時代,資料無時無刻不在產生,而90%的資料產生於近2年,產生的速度是非常驚人的。2011年有預測表明,2015年時資料即可達到800萬PB,而阿里雲的願景是打造資料分享第一平臺,幫助使用者挖掘資料價值,在面對如此海量的資料、想要通過大資料平臺分析其背後的巨大價值之前,首先就需要能夠將資料儲存下來,並且是要廉價的保留下來。這就要求一定要使用基於大規模工業流水線上生產的普通PC和SATA磁碟,打造廉價的儲存系統用於儲存資料。但是,由於是大規模流水線生產出來的普通硬體,一定會有相對的次品率,一塊硬碟平均每年會有百分之幾的出錯概率。在這種情況下,如何在這個出錯概率上去保證資料服務的高可用性,我們就需要依賴多副本來提高我們的容錯能力。從而能夠做到我們10個九的可靠性的資料服務。
多副本
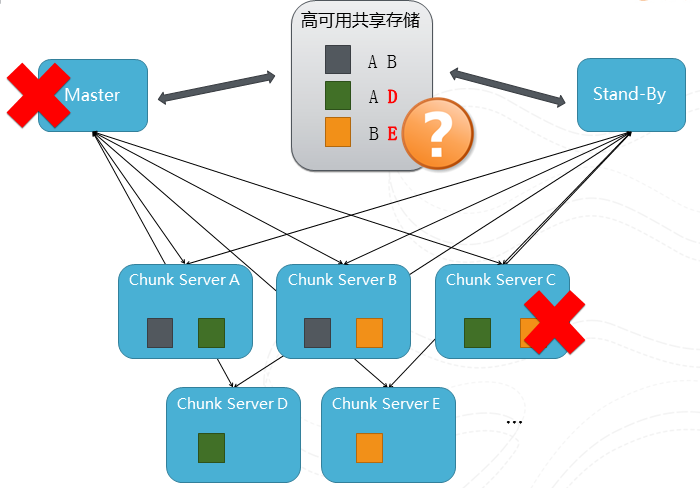
圖2 一個多副本slide的過程
這張圖描述了一個多副本的過程,我們有多臺chunkserver分散式的來儲存檔案,在這個例子中有灰,綠和橙色三個檔案,為了簡化描述,假設每個檔案有2個副本(在真實系統裡面副本的個數是可以控制的,根據資料的重要性、副本可以擴充套件到3個或多個不等)分佈在不同的chunk server中。然後我們把關於副本位置的元資料儲存在元資料伺服器Master中,假設這個時候Chunk Server C機器壞了,但是因為每個檔案至少還是有個副本在服務,所以對服務是沒有影響的。不過為了保持系統的容錯水平,我們及時把綠和橙色檔案從ServerA和ServerB複製到D和E上從而恢復2副本的水平。但是這裡還有一個問題,如果Master的機器壞了怎麼辦?這就相當於丟失了副本的位置資訊,使用者就沒有辦法知道各副本的分佈位置,就是副本是還是安全可靠的,但是整個服務還是會停滯了。為了解決這個問題,Hadoop的方案是採用加一個stand-by的機器,當Master出錯的時候,stand-by的機器將接管元資料的服務。但這個解決方案需要依賴於有個高可用的共享儲存來儲存元資料本身。但是我們本來就是想搭建一個高可用的儲存服務,不能去依賴另外一個服務來作為保證,所以我們採用了Paxos的協議來搭建我們的元資料服務。
Paxos高可用方案(盤古)
Paxos協議,是2013年圖靈獎獲得主Lamport在1989年發表的一篇論文,該論文解決了分散式系統下一致性問題。如果大家感興趣可以去讀一下論文。

圖3 Leslie Lamport
(LeslieLamport,微軟研究院科學家,2013年圖靈獎得主,1989發表Paxos解決了分佈系統下的一致性問題)
這個協議的推演是個複雜的過程,其主要思路就是在2N+1的群體中通過協議交換資訊,通過少數服從多數的方式達到整個資料的一致性。這樣一來,元資料可以大家分別各自儲存,不存在需要額外的高可用的共享儲存。並且只要存在多數者,我們就能提供準確一致的元資料服務。
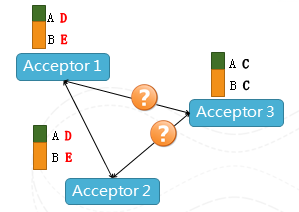
圖4 場景示意
在上圖中,Acceptor相當於一個仲裁者,我們可以看到Acceptor 3因為某種原因不能和Acceptor1、2聯絡,但是隻要1、2看到是一致的元資料,服務就可以繼續下去,所以不會存在單點Failure,整個系統的容錯等級也是可以配置的,根據機器的環境、出錯的概率、恢復的速度進行調整,最多可以容忍N臺機器出錯(2N+1機器組成的Paxos),並且該協議中各個請求不需要同步,都是純非同步的方式,使得整個協議不會因為某些機器的延時而造成效能的下降,在分散式系統中,這個臨時效能波動是非常常見的。這個方案沒有任何額外需要高可用的共享儲存,就可以通過普通PC的機器環境裡面來達到高可用性。
盤古分散式檔案系統

圖5 場景示意
剛剛講到阿里的分散式檔案系統盤古就是由儲存資料多副本的大量的Chunk Server加上一個提供高可用的元資料服務的Paxos群來提供高可靠的資料服務。此外,我們還在高可靠,多租戶,高效能,大規模等方面做了大量的研究和工作。比如多租戶訪問許可權控制,流控,公平性,離線線上混布;高效能方向,比如混合儲存,我們知道SSD盤儲存量高、讀寫效能好但是貴,我們如何結合SSD的高效能,高吞吐和SATA的低沉本高密度做到一個性能上貼近SSD,但是成本貼近SATA等等。
資源排程的挑戰
剛剛說了儲存,資料存下來了,但是如果僅僅是存,而不是分析,那資料只是躺在系統裡的垃圾。所以,資料一定要動起來。在儲存的基礎上去搭建一個計算平臺去分析資料背後的價值,而首要解決的的就是排程的問題,如何任務能夠高效排程到我們叢集中的資源上去執行。其實就是把你的需求和你的資源做個Match。這麼說起來很簡單的問題,但是一旦規模大了、需求各異了,就會變得很難。因為我們的規模,機器負載時時刻刻都在變化,需求上也是要求各異,比如CPU/磁碟/網路等等, 執行時間,實時性要求,需求直接的關係也是各自不同的。如何在有限的時間中快速的進行bin-pack的演算法,達到資源的充分使用,並同時保證實時性,公平性等等不同需求的平衡是非常挑戰的。
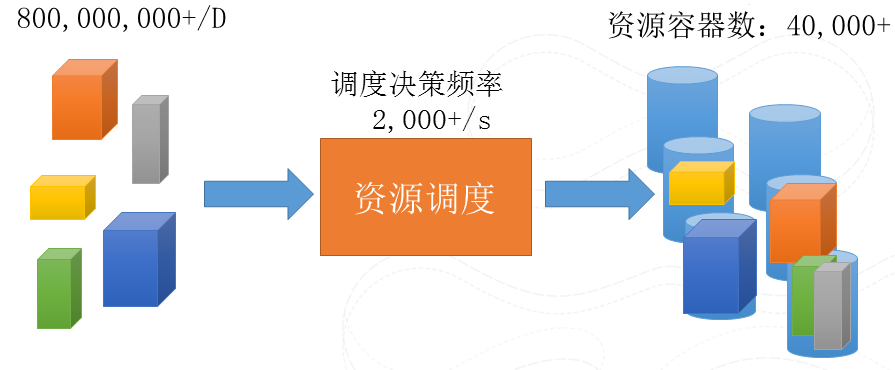
圖6 待排程例項數
調動的多維目標
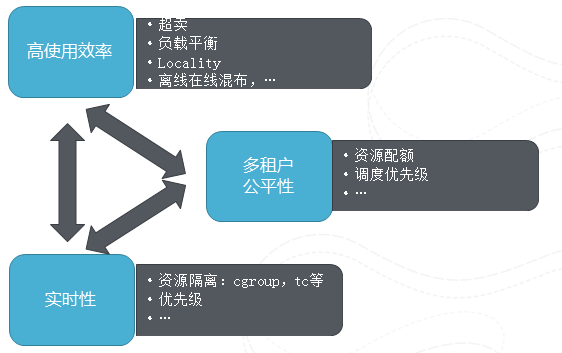
圖7 調動的多維目標
這裡主要展示了在排程中多個維度的目標,這些目標是相互牽扯的。比如高效率就希望儘量把機器裝滿,有空就塞一個任務進去,但是這樣就會影響公平性,如果總是以這種方式,那麼小任務、比較靈活的任務容易被執行,總能夠得到機會排程,那些比較有更多要求,約束條件的任務就會被餓死,所以高可用性和公平性是有矛盾的。再舉個例子,實時性就是希望預留資源從而不會出現打滿的情況,但這樣勢必帶來資源的浪費,影響使用效率。阿里雲在各個維度上均做了大量的工作,比如高使用效率上,我們做了負載平衡,離線線上混布,就近執行優化,資源複用。多租戶方面資源配額的管理,優先順序。實時性方向,資源如何隔離等等。而要在這些看似矛盾的排程目標上做到最好一個排程系統,其本身需要基於非常詳盡的執行統計和預測資料,比如資源要求的推算,機器負載的實時統計資料等等,並在這些資料幫助下及時的做出好的決策。
舉一個資源複用的例子說明一下提高機器的使用效率同時保證實時性不被破壞,我們套用航空中的例子來解釋。我們把使用者分成幾種group.:有非常重要的job,對於實時性,完成時間要求很高的使用者,他們就是金卡會員,他來了我們優先讓他登機,訪問我們機器的資源;剩下是普通使用者,需用排隊享用雲服務;最後一部分使用者他們對完成時間沒有什麼要求,如果碰巧金卡會員沒有來,或者使用的資源沒有佔滿,他們就可以提前坐當前航班,但是如果來了金卡會員,他們就只能做下一班航班了。通過這種方式我們來達到資源使用和實時性要求的一種平衡。聽起來似乎很簡單,但是如何設計各個艙位的比例,什麼時候能夠允許搶佔,誰搶佔,搶佔誰。還有每個任務的執行時間,開始時間的不同,如何分配他們到不同的航班,每個都是可以好好研究的問題,這個事情需要真正和業務、和後面的服務進行一種可適配的調整來去達到效能最好的平衡。
伏羲作業程式設計模型:DAG
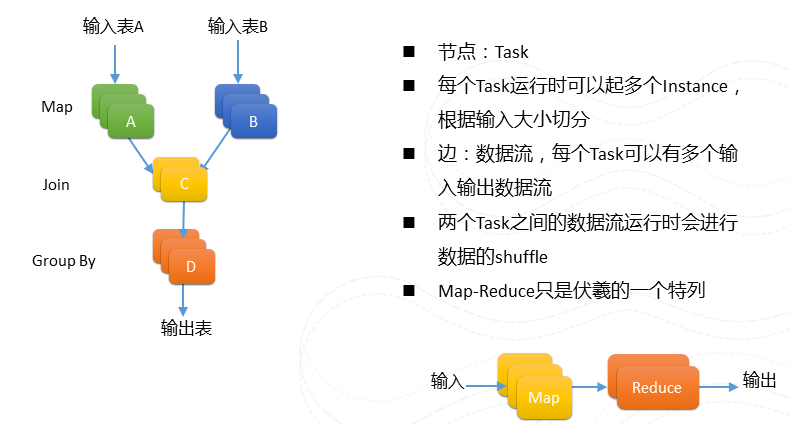
圖8 DAG
講完排程問題,在講計算平臺之前大概簡單介紹一下我們作業的程式設計模型。有別於Map-Reduce把運算分為Map和reduce兩個階段,我們作業可以被描述為一個的DAG圖。每個節點可以有多路的輸入和輸出。例如左圖。
MaxCompute(原ODPS)分散式海量資料計算引擎
有了儲存,有了資源排程。讓使用者來裸寫DAG圖來進行計算還是太難。所以我們需要搭建一個計算引擎來幫助資料工程師更加好的,更加容易的來做資料分析。這個計算引擎我們希望達到海量的高效能的計算能力,同時有完善安全的體制,有統一應用的程式設計框架,能夠讓我們上面的資料工程師更好更方便的開發資料應用,我們需要有穩定性、因為穩定是服務的第一要素。
統一的計算引擎
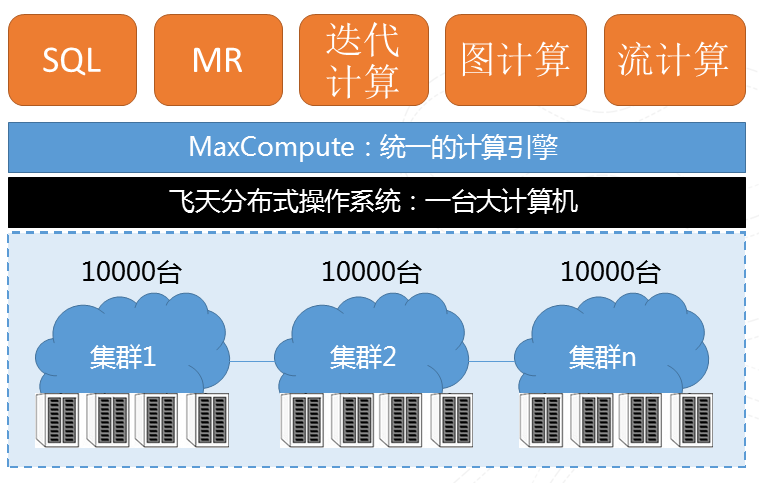
圖9 計算基本架構
我們有多個萬臺以上的物理叢集分佈在多地的,在此基礎上會有一個飛天的分散式操作系,再上面會搭建一個統一的計算引擎幫助我們的開發者迅速的進行開發。之上我們提供了很多種運算方式,比如傳統的SQL、MR、迭代計算、圖計算、流計算等種種計算模式幫助開發人員解決現實問題。這個平臺最主要有兩個特點,第一是“大”,去年雙十一6小時處理了100PB的資料;第二是“快”,去年打破世界紀錄,100TB資料排序377秒。
MaxCompute系統架構
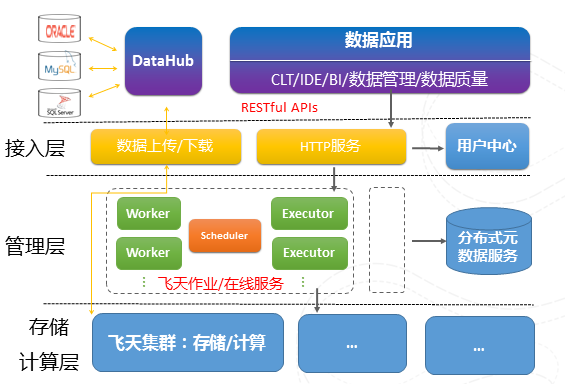
圖10 MaxCompute系統架構
上圖揭示了MaxCompute平臺的體系結構,資料通過DataHub接入到計算引擎,不同於其他的計算分散式系統,我們還分割管理層和運算層,管理層封裝底層多個計算叢集,使得計算引擎可以當成一個運算平臺,可以打破地域的限制,做到真正的跨地域、跨機房的大型運算平臺,還有一個重要原因是基於安全性的要求。我們只在計算叢集內去執行使用者自定義的函式,而在管理層我們進行使用者許可權檢查,在利用沙箱技術隔離惡意使用者程式碼的同時,通過網段隔離,進一步保障使用者資料的安全性。
資料從某種意義上是阿里的生命線,所以我們系統設計的時候就非常強調資料的管理,我們有很詳盡的資料血緣關係的分析,分析資料之間的相關性。豐富的資料發現工具幫助資料工程師理解和使用資料等等。阿里也非常強調資料的質量,因為提高了系統中的資料質量將大大提高資料分析的效率,使得我們資料處理變得事半功倍。我們建立完整資料質量監控閉環,記錄計算平臺本身中各種執行資料的和各種元資料,這些資料其實本身就是非常巨大,我們正好利用自己平臺本身的強大資料分析能力來分析這些資料,通過系統已有的監控能力等等來提高自己上資料質量。
迴歸到運算,剛剛講到我們在統一的計算引擎上面很多種計算模式,因為時間有限,我們就只用一個簡單的例子來解釋一下整個SQL的過程。
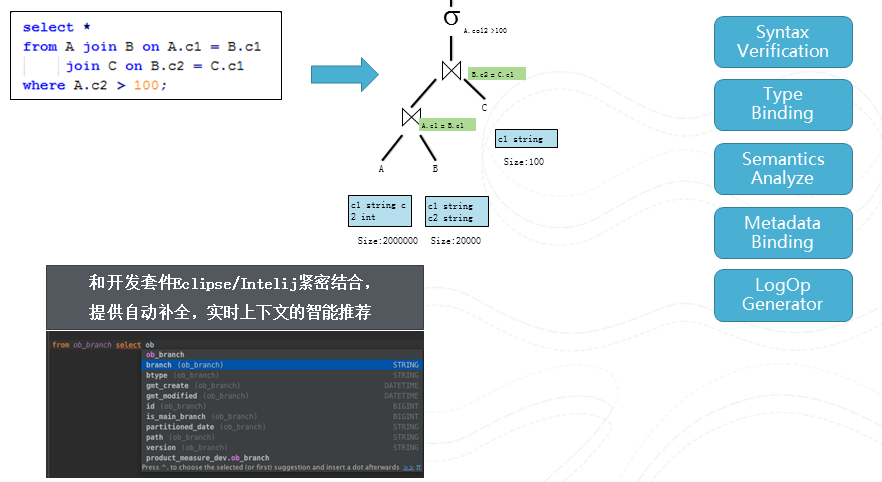
圖11 編譯
這個例子很簡單,就是將A,B,C做個join後進行fliter後返回。編譯器將該查詢轉變一個語法樹,然後對該樹進行多次的visit. 將不同的資訊附加到該樹上。我們將編譯器和IDE緊密結合,在編輯查詢的同時不停的進行編譯,從而能夠提供自動補全,上下文智慧推薦等等visual studio的程式設計體驗。
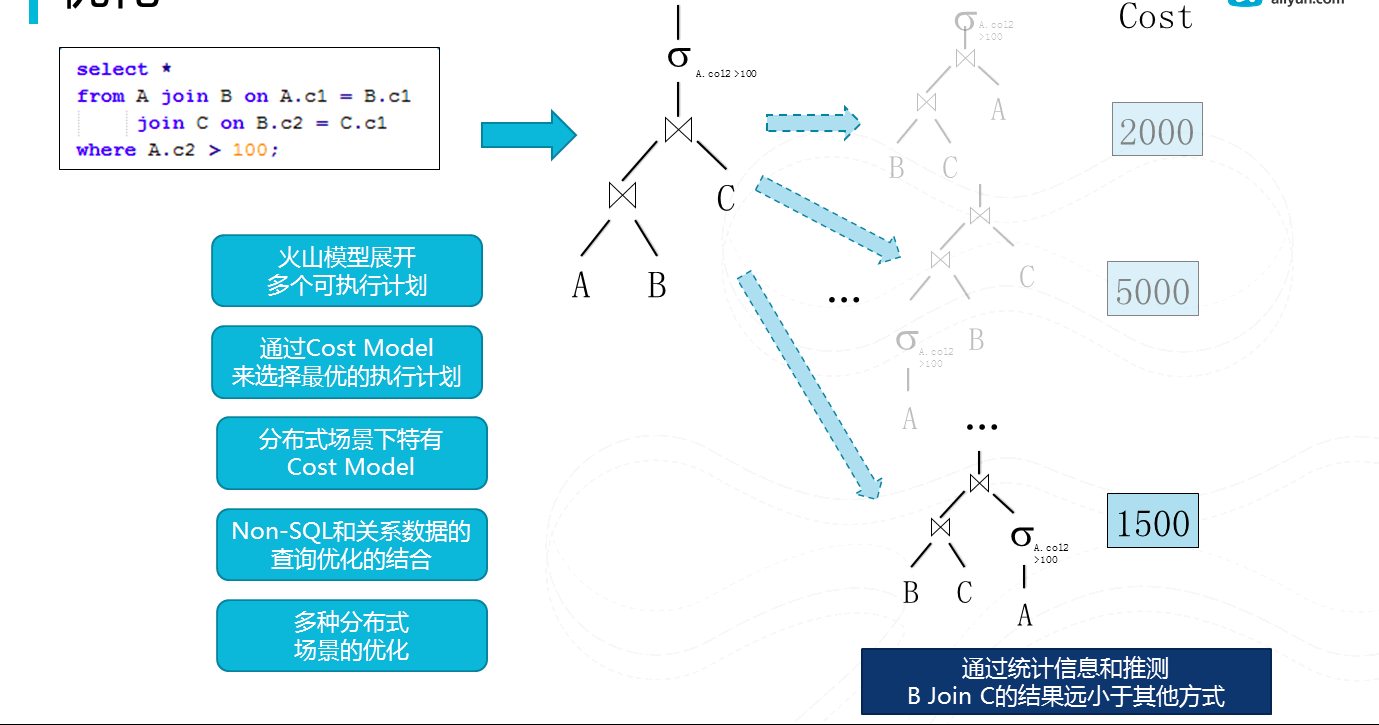
圖12優化
經過編譯,我們將生成一個邏輯執行計劃,接下來我們將其進行優化來生成一個物理執行計劃。我們採用cascading優化模型。就是將邏輯執行計劃,利用變換規則把其分裂出多個等價的物理執行計劃,然後通過一個統一的cost model來選擇一個最優的執行計劃(cost最低),現在開源社群也在從簡單的rule-based像這種更加先進的cost-based的優化器演進。有別於單機成熟的資料庫產品中的已經廣泛使用cascading優化器。在分散式系統下,cost model本身, 大量使用者自定義函式和分散式場景都帶來不同的問題場景。
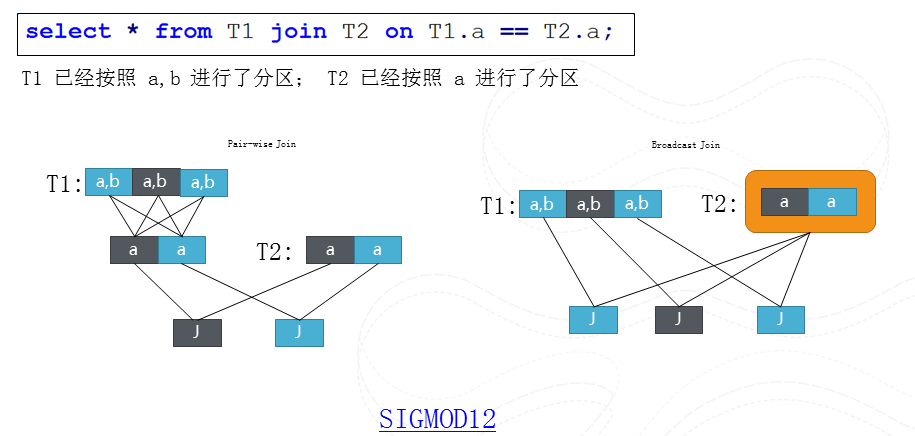
圖13 分散式查詢中的一個優化問題
這裡就舉一個例子來解釋下分散式系統下的查詢優化一個問題。我們需要T1和T2兩個表格在
a column上做join,T1按照a, b進行分片, T2按照a進行分片。所以我們可以把T1重新按照a進行重新分片然後和T2進行join, 我們也可以把T2作為整體然後broadcast到T1的每個分片。這兩個執行孰優孰劣取決於重新分片T1帶來多餘一個步驟重,還是broadcast T2帶來多餘資料拷貝重。如果這個分片是Range分片,我們還會有更多有趣的執行計劃,大家可以去閱讀我在SIGMOD 12上的論文。
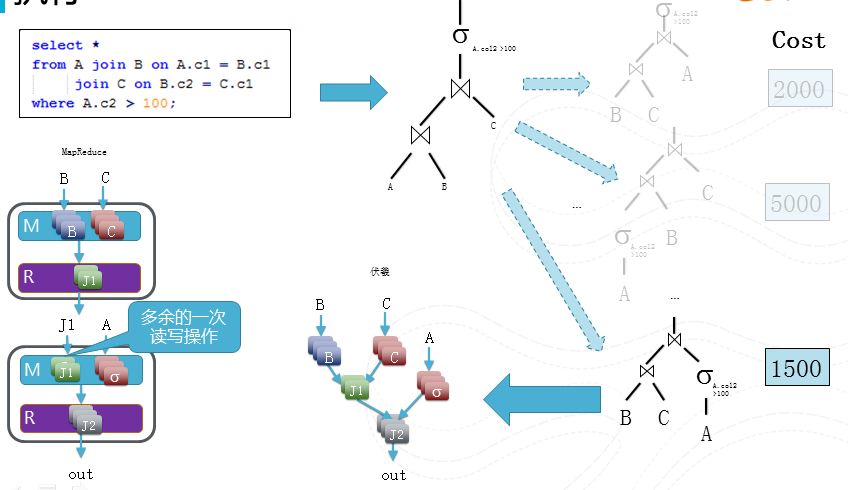
圖14 執行
有了物理執行計劃,我們將會把這個計劃翻譯為伏羲的一個作業區排程,因為伏羲作業可以描述DAG, 對比於常規的Map-Reduce,所以我們在這個例子中能夠節省一次多餘的讀寫操作。
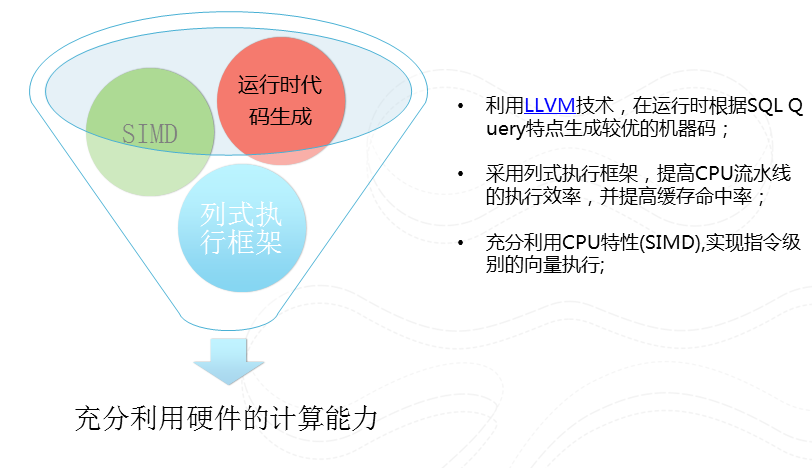
圖15 更高效的執行引擎
我們在每個worker中執行的程式是經過根據該查詢經過程式碼生成,然後經過LLVM編譯器生成的高效的機器程式碼。我們採用列式執行,充分利用CPU本身向量執行指令來提高CPU流水線執行效率,並提高快取的命中率。
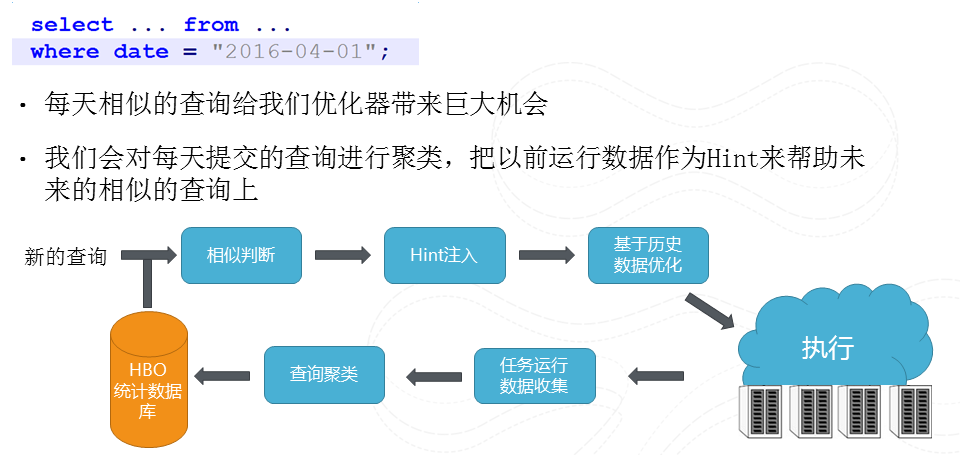
圖16 HBO(基於歷史的優化)
我們有大量相似查詢,他們僅僅在處理資料時間上不同。所以我們可以利用資料分析的手段將這些相似的查詢進行聚類,然後把原來以前執行得到的統計資訊來幫助進行優化,這樣我們就能夠對使用者自定義函式有了一些大致判斷從而提高優化的結果
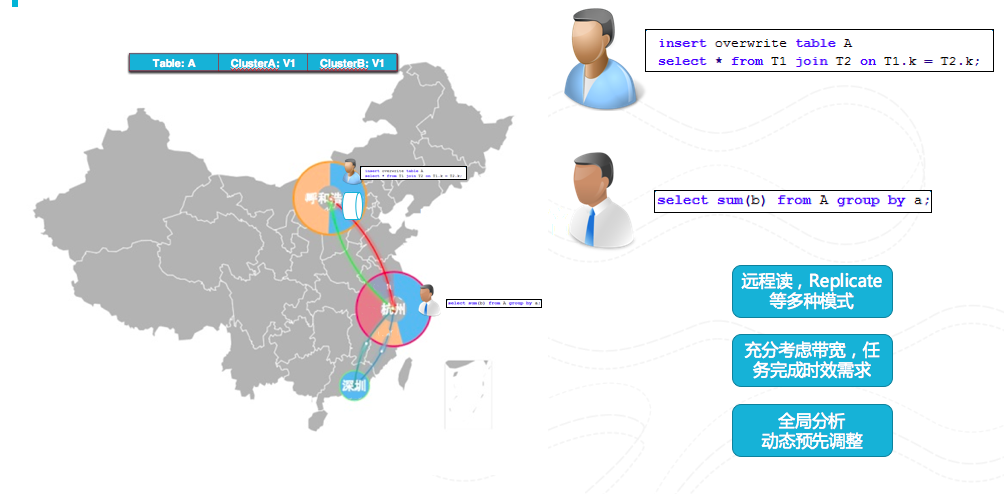
圖17 全域性排程
MaxCompute的管理層封裝了多個計算叢集從而做到打破機房限制,做到多地域的計算平臺。再考慮任務完成時效要求,多叢集之間的頻寬大小等因素下進行全域性分析,利用動態預先調整,遠端讀,複製等多種手段做到全域性排程。
總結一下MaxCompute的特點,首先是大規模,萬臺單機群有跨叢集的能力;相容Hive語言;高效能,有列儲存, 向量運算,C++程式碼執行,高執行效率,更好的查詢優化;有穩定性,在阿里巴巴有5年的實踐經驗;有豐富UDF擴充套件,能夠支援多種執行狀態等等。講講大資料平臺最新的進展,在剛剛做的基礎上面會繼續做的工作:會增強伏羲DAG,描述能力進一步增強,支援迭代計算、條件式的結束條件等,在MaxCompute平臺繼續加強優化,會做更多擴充套件,做更多效能上和成本上的優化;會貼近需求做更多迭代計算滿足機器學習的演算法特性等。