
揭開知識庫問答KB-QA的面紗3·資訊抽取篇
內容速覽
- 你是如何通過知識庫回答問題的
- 如何確定候選答案
- 如何對問題進行資訊抽取
- 如何篩選候選答案
- 論文實驗與總結

本期我們將介紹KB-QA傳統方法之一的資訊抽取(Information Extraction),我們以一個該方法的經典代表作為例,為大家進一步揭開知識庫問答的面紗。該方法來自約翰·霍普金斯大學Yao X, Van Durme B.的 (文章發表於2014年的ACL會議)。
該類方法通過提取問題中的實體,通過在知識庫中查詢該實體可以得到以該實體節點為中心的知識庫子圖,子圖中的每一個節點或邊都可以作為候選答案。通過觀察問題,依據某些規則或模板進行資訊抽取,得到表徵問題和候選答案特徵的特徵向量,建立分類器,通過輸入特徵向量對候選答案進行篩選,從而得出最終答案。
你是如何回答問題的
想一想,如果有人問你 “what is the name of Justin Bieber brother?" ,並且給你一個知識庫,你會怎麼去找答案?顯然,這個問題的主題(Topic)詞就是Justin Bieber,因此我們會去知識庫搜尋Justin Bieber這個實體,尋找與該實體相關的知識(此時相當於我們確定了答案的範圍,得到了一些候選答案)。接下來,我們去尋找和實體關係brother相關的實體(事實上freebase裡沒有brother這個實體關係,而是sibling,我們需要進行一個簡單的推理),最後得到答案。
而資訊抽取的方法,其靈感就是來自於剛才我們的這種思考方式。
如何確定候選答案
根據我們人的思維,當我們確定了問句中的主題詞,我們就可以去知識庫裡搜尋相應的知識,確定出候選答案。如果我們把知識庫中的實體看作是圖節點,把實體關係看作是邊,那麼知識庫就是一個龐大的圖,通過問句中的主題詞可以找到它在知識庫中對應的圖節點,我們將該圖節點相鄰幾跳(hop)範圍內的節點和邊抽取出來得到一個知識庫的子圖,這個子圖作者稱為主題圖(Topic graph),一般來說,這裡的跳數一般為一跳或兩跳,即與主題詞對應的圖節點在一條或兩條邊之內的距離。主題圖中的節點,即是候選答案。接下來,我們需要觀察問題,對問題進行資訊抽取,獲取能幫助我們在候選答案中篩選出正確答案的資訊。
如何對問題進行資訊抽取
還是這個例子,讓我們先放慢腳步,想想我們人類是怎麼對這個問題進行資訊抽取和推理的。首先,我們會潛意識地對這個句子結構進行分析,下圖是 “what is the name of Justin Bieber brother?" 這個問句的語法依存樹(Dependency tree),如果你對依存樹不瞭解,可以把它理解成是一種句子成分的形式化描述方式。
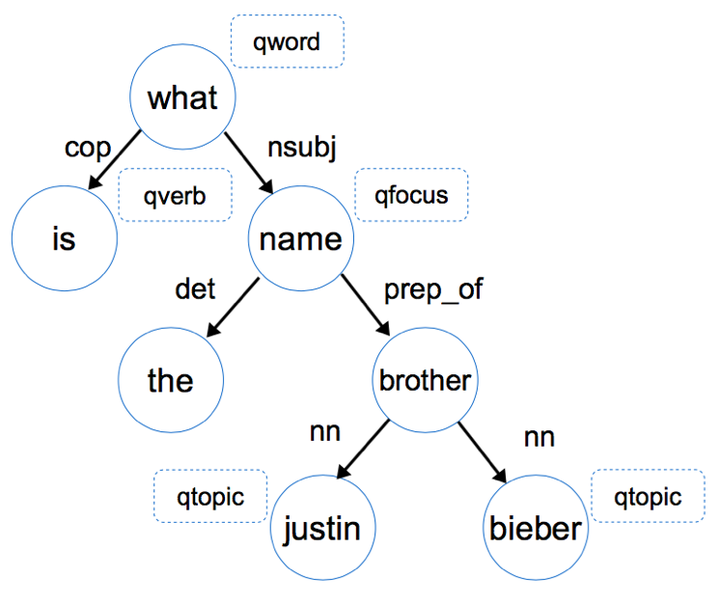 我們首先通過依存關係nsubj(what, name) 和 prep_of(name, brother) 這兩條資訊知道答案是一個名字,而且這個名字和brother有關,當然我們此時還不能判斷是否是人名。進一步,通過nn(brother, justin bieber)這條資訊我們可以根據justin bieber是個人,推匯出他的brother也是個人,綜合前面的資訊,我們最終推理出來我們的答案應該是個人名。(注:這裡nsubj代表名詞性主語,prep_of代表of介詞修飾,nn代表名詞組合,如果你想了解更多tag,可以點選這裡)當確定了最終答案是一個人名,那麼我們就很容易在備選答案中篩選出正確答案了。
我們首先通過依存關係nsubj(what, name) 和 prep_of(name, brother) 這兩條資訊知道答案是一個名字,而且這個名字和brother有關,當然我們此時還不能判斷是否是人名。進一步,通過nn(brother, justin bieber)這條資訊我們可以根據justin bieber是個人,推匯出他的brother也是個人,綜合前面的資訊,我們最終推理出來我們的答案應該是個人名。(注:這裡nsubj代表名詞性主語,prep_of代表of介詞修飾,nn代表名詞組合,如果你想了解更多tag,可以點選這裡)當確定了最終答案是一個人名,那麼我們就很容易在備選答案中篩選出正確答案了。我們剛才進行的步驟,實際上就是在對問題進行資訊抽取,接下來,讓我們看看這篇文章具體是怎麼實施的。
首先我們要提取的第一個資訊就是問題詞(question word,記作qword), 例如 who, when, what, where, how, which, why, whom, whose,它是問題的一個明顯特徵 。第二個關鍵的資訊,就是問題焦點(question fucus, 記作qfocus),這個詞暗示了答案的型別,比如name/time/place,我們直接將問題詞qword相關的那個名詞抽取出來作為qfocus,在這個例子中,what name中的name就是qfocus。第三個我們需要的資訊,就是這個問題的主題詞(word topic,記作qtopic),在這個句子裡Justin Bieber就是qtopic,這個詞能夠幫助我們找到freebase中相關的知識,我們可以通過命名實體識別(Named Entity Recognition,NER)來確定主題詞,需要注意的是,一個問題中可能存在多個主題詞。最後,第四個我們需要提取的特徵,就是問題的中心動詞(question verb ,記作qverb),動詞能夠給我們提供很多和答案相關的資訊,比如play,那麼答案有可能是某種球類或者樂器。我們可以通過詞性標註(Part-of-Speech,POS)確定qverb。通過對問題提取 問題詞qword,問題焦點qfocus,問題主題詞qtopic和問題中心動詞qverb這四個問題特徵,我們可以將該問題的依存樹轉化為問題圖(Question Graph),如下圖所示
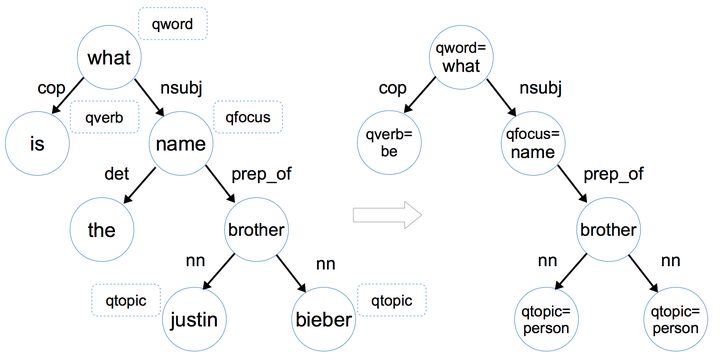 具體來說,將依存樹轉化為問題圖進行了三個操作
具體來說,將依存樹轉化為問題圖進行了三個操作1)將問題詞qword,問題焦點qfocus,問題主題詞qtopic和問題中心動詞qverb加入相對應的節點中,如what -> qword=what。
2)如果該節點是命名實體,那就把該節點變為命名實體形式,如justin -> qtopic=person (justin對應的命名實體形式是person)。這一步的目的是因為資料中涉及到的命名實體名字太多了,這裡我們只需要區分它是人名 地名 還是其他型別的名字即可。
3)刪除掉一些不重要的葉子節點,如限定詞(determiner,如a/the/some/this/each等),介詞(preposition)和標點符號(punctuation)。
從依存樹到問題圖的轉換,實質是就是對問題進行資訊抽取,提取出有利於尋找答案的問題特徵,刪減掉不重要的資訊。
如何構建特徵向量對候選答案進行分類
在候選答案中找出正確答案,實際上是一個二分類問題(判斷每個候選答案是否是正確答案),我們使用訓練資料問題-答案對,訓練一個分類器來找到正確答案。那麼分類器的輸入特徵向量怎麼構造和定義呢?特徵向量中的每一維,對應一個問題-候選答案特徵。每一個問題-候選答案特徵由問題特徵中的一個特徵,和候選答案特徵的一個特徵,組合(combine)而成。
問題特徵:我們從問題圖中的每一條邊e(s,t),抽取4種問題特徵:s,t,s|t,和s|e|t。如對於邊prep_of(qfocus=name,brother),我們可以抽取這樣四個特徵:qfocus=what,brother,qfocus=what|brother 和 qfocus=what|prep_of|brother。
候選答案特徵:對於主題圖中的每一個節點,我們都可以抽取出以下特徵:該節點的所有關係(relation,記作rel),和該節點的所有屬性(property,如type/gender/age)。(注:我在揭開知識庫問答KB-QA的面紗1·簡介篇中對知識庫中屬性和關係的區別進行了講解)對於Justin Bieber 這個topic我們可以在知識庫找到它對應的主題圖,如下圖所示:
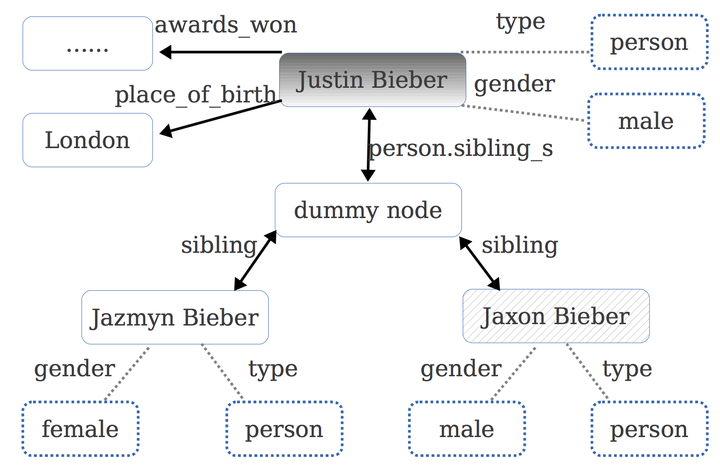 (注:圖中虛線表示屬性,實線表示關係,虛線框即屬性值,實現框為topic node。在知識庫中,如果同一個topic節點的同一個關係對應了多個實體,如Justin Bieber的preon.sibing_s關係可能對應多個實體,那麼freebase中會設定一個虛擬的dummy node,來連線所有相關的實體)
(注:圖中虛線表示屬性,實線表示關係,虛線框即屬性值,實現框為topic node。在知識庫中,如果同一個topic節點的同一個關係對應了多個實體,如Justin Bieber的preon.sibing_s關係可能對應多個實體,那麼freebase中會設定一個虛擬的dummy node,來連線所有相關的實體)例如,對於Jaxon Bieber這個topic節點,我們可以提取出這些特徵:gender=male,type=person,rel=sibling 。可以看出關係和屬性都刻畫了這個候選答案的特徵,對判斷它是否是正確答案有很大的幫助。
問題-候選答案特徵:每一個問題-候選答案特徵由問題特徵中的一個特徵和候選答案特徵中的一個特徵,組合(combine)而成(組合記作 | )。我們希望一個關聯度較高的問題-候選答案特徵有較高的權重,比如對於問題-候選答案特徵 qfocus=money|node type=currency(注意,這裡qfocus=money是來自問題的特徵,而node type=currency則是來自候選答案的特徵),我們希望它的權重較高,而對於問題-候選答案特徵qfocus=money|node type=person我們希望它的權重較低。
接下來我們用WebQuestion作為訓練資料,使用Stanford CoreNLP幫助我們對問題進行資訊抽取。訓練集中約有3000個問題,每個問題對應的主題圖約含1000個節點,共計有3 million的節點和7 million種問題-候選答案特徵,作者用帶L1正則化的邏輯迴歸(logistic regression)作為分類器,訓練每種問題-候選答案特徵的權值(L1正則化的邏輯迴歸很適合處理這種稀疏的特徵向量,作者表示其效果好於感知機Percptron和支援向量機SVM)。 訓練完畢後,得到了3萬個非零的特徵,下表列出了部分特徵和它相應的權值,可以看出問題特徵和候選答案特徵相關度較高時,其權值較高。
 因此,在使用的時候,對於每一個候選答案,我們抽取出它的特徵(假設有k個特徵)後,再和問題中的每一個特徵兩兩結合(假設有m個特徵),那麼我們就得到了k*m個問題-候選答案特徵,因此我們的輸入向量就是一個k*m-hot(即k*m維為1,其餘維為0)的3萬維向量。
因此,在使用的時候,對於每一個候選答案,我們抽取出它的特徵(假設有k個特徵)後,再和問題中的每一個特徵兩兩結合(假設有m個特徵),那麼我們就得到了k*m個問題-候選答案特徵,因此我們的輸入向量就是一個k*m-hot(即k*m維為1,其餘維為0)的3萬維向量。在提取候選答案的特徵時,我們對每個實體提取了它的關係和屬性,在論文中,作者還額外提取了一個更強力的特徵,即每一個關係R和整個問題Q的關聯度,可表示為概率的形式。那麼這個概率如何求解呢?作者採用樸素貝葉斯,backoff model(即
)的思想和假設,對於
這種複合關係,如people.person.parents,也採用backoff的思想(即
)這個概率進行近似,即
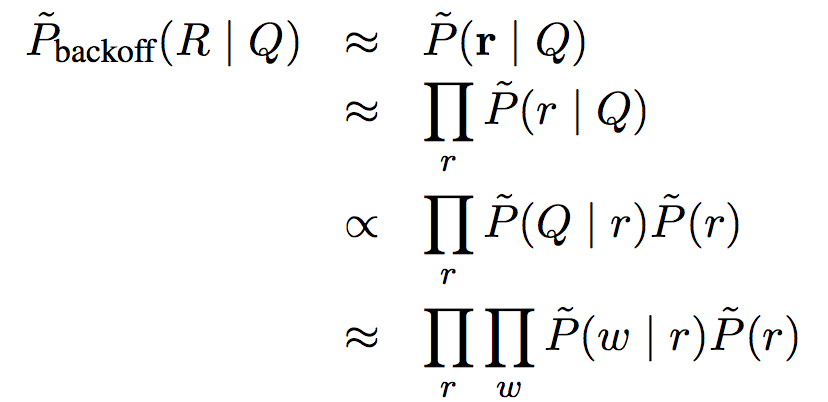 作者通過freebase知識庫和兩個資料集分別對上面的概率進行統計估算。第一個資料集是Berant J, Chou A, Frostig R, et al. 中Semantic Parsing on Freebase from Question-Answer Pairs使用到的利用ReVerbopen IE system在ClueWeb09抽取的三元組資料集,包含了15million個三元組,該資料集記作ReverbMapping,第二個資料集是含1.2 billion對齊對(alignment pairs)的CluewebMapping。值得一提的是,這些資料中並不直接包含知識庫中的關係rel,那麼要如何去估算
作者通過freebase知識庫和兩個資料集分別對上面的概率進行統計估算。第一個資料集是Berant J, Chou A, Frostig R, et al. 中Semantic Parsing on Freebase from Question-Answer Pairs使用到的利用ReVerbopen IE system在ClueWeb09抽取的三元組資料集,包含了15million個三元組,該資料集記作ReverbMapping,第二個資料集是含1.2 billion對齊對(alignment pairs)的CluewebMapping。值得一提的是,這些資料中並不直接包含知識庫中的關係rel,那麼要如何去估算在兩個資料集上分別完成統計和計算後,作者使用了WebQuestion進行了測試,分別計算給定每一個問題Q,答案對應的relation,它們的概率和其他relation相比,排名在top1, top5, top10, top50, top100和100之後這六種情況的百分比,如下表所示
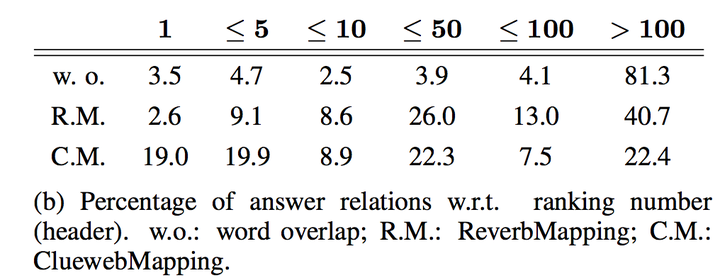 可以看出當使用ClueWebMapping這個超大資料集訓練後,給定一個問題,每次選擇概率最高的rel時,有19%的正確率。因此,作者對於主題圖中的每一個候選答案,增加這樣一種特徵,即該候選答案對應的每一個關係rel,其概率
可以看出當使用ClueWebMapping這個超大資料集訓練後,給定一個問題,每次選擇概率最高的rel時,有19%的正確率。因此,作者對於主題圖中的每一個候選答案,增加這樣一種特徵,即該候選答案對應的每一個關係rel,其概率至此,我們已經搞清楚了這篇文章方法涉及到的所有元素:問題特徵,候選答案特徵,每個候選答案和問題的特徵向量以及分類器。最後,我們再簡單介紹下實驗。
論文實驗與總結
候選答案的主題圖是根據問題中的主題詞確定的,而一個問題可能包含多個主題詞。作者先通過命名實體識別提取問題中的所有命名實體(如果提取不到一個命名實體,則使用名詞短語代替),將所有命名實體輸入到Freebase Search API中,選取返回排名最高的作為最終的主題詞,使用FreebaseTopic API得到相應的主題圖。
當然使用Freebase Search API這個方法可能會錯過真正和答案相關的主題詞(topic),作者也測試了模型在真實的主題詞(Gold Retrieval)下的F1 score,結果如下:
 可以看出,資訊抽取的這個方法,相比我在揭開知識庫問答KB-QA的面紗2·語義解析篇 - 知乎專欄中介紹的Semantic Parsing on Freebase from Question-Answer Pairs方法在F1-score下有較高的提升,到達了42.0的F1-score。
可以看出,資訊抽取的這個方法,相比我在揭開知識庫問答KB-QA的面紗2·語義解析篇 - 知乎專欄中介紹的Semantic Parsing on Freebase from Question-Answer Pairs方法在F1-score下有較高的提升,到達了42.0的F1-score。資訊抽取的辦法,總體來說涉及到了不少linguistic的知識,比較符合人類的直覺。雖然也涉及到了很多手工和先驗知識的東西,但個人認為它的思想還是很不錯的。
作者在構造候選答案特徵時,引入了和相關的特徵,這個思路是一個很好的思路,但是對
的估計方式總體來說還是比較粗暴(比如使用backoff),個人認為可以使用Deep Learning的方法進行提升。
資訊抽取的特徵向量,每一維都代表了一個可解釋的特徵,是一種離散的表達。在下一期中,我們將介紹KB-QA的第三種傳統方法——向量建模,它將使用分散式表達(Distributed Embedding)來構造問題和答案的特徵向量,該方法相比資訊抽取和語義解析,涉及到較少的linguistic和手工規則,也較容易通過Deep Learning進行提升。我們將以Bordes A, Chopra S, Weston J. 的Question answering with subgraph embeddings這篇文章為例,為大家進一步揭開KB-QA的面紗。
敬請期待。
https://zhuanlan.zhihu.com/p/25782244